



生成AIの実用化が急速に進み、推論時により長く思考させることで性能を向上できることが示されている。
一方で、現在大規模言語モデルの主流となっている「Transformer」アーキテクチャでは、長い文書を扱ったり、多数のユーザから同時に問い合わせを受けたりすると、過去の情報を保持するためのメモリアクセスが増加し、処理速度が低下してしまうという課題があった。
これにより、大規模運用時の計算リソースやコストの増大が企業にとって大きな負担となっている。
こうした中、富士通は2026年6月24日、大規模言語モデルの大幅なコスト削減を実現する新アーキテクチャ「PHOTON(Parallel Hierarchical Operation for TOp-down Networks)」を開発したと発表した。
同技術は、複数エージェントのような複雑な入出力を必要とする処理を低コストかつ効率的に実行し、少ないGPUリソースで高い生成性能を実現する基盤技術だ。
具体的には、文章を細かな文字(トークン)単位に分解してすべての関係を計算する従来の手法とは異なり、文章を「意味のまとまり」として捉え、階層的に処理することで計算量を削減している。
さらに、同じ問題に対して少しずつ異なる複数の質問や候補を作り、その結果を多数決などでまとめて最終的な答えを決める「マルチクエリー統合技術」を採用した。

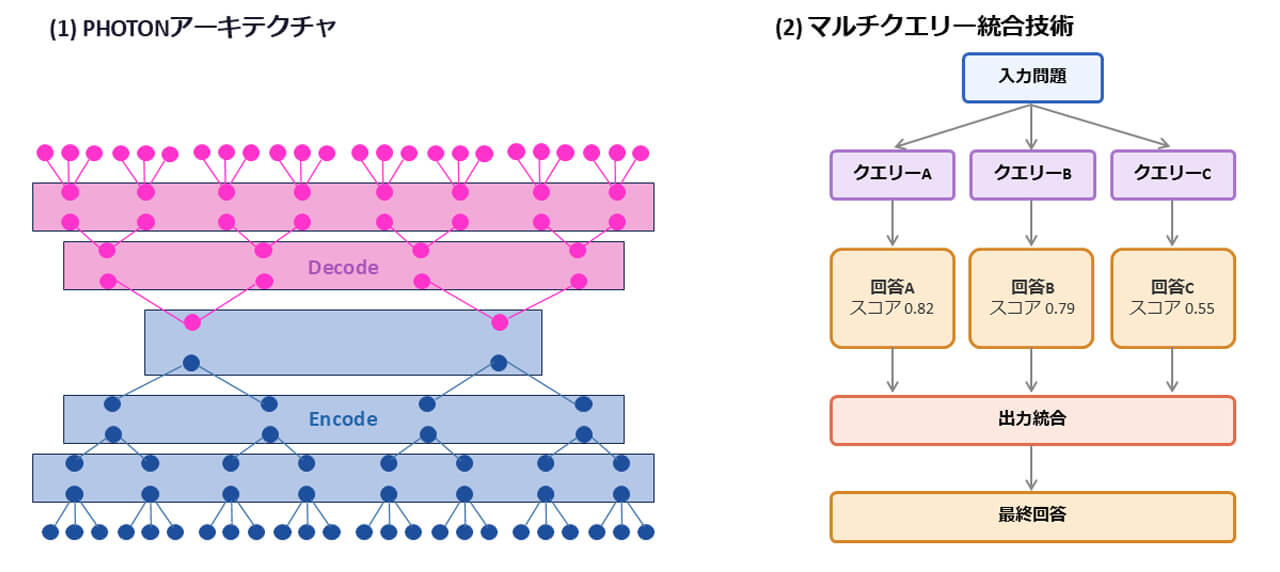
これにより、従来のアーキテクチャに依存していた膨大な計算リソースを圧縮し、企業が生成AIを運用・スケールさせる際のGPUコストと消費電力を削減する。
数値実験の結果、1.2Bパラメータモデルにおいて、わずかな性能劣化と引き換えに従来のTransformerと比べて約475倍のマルチクエリー計算能力(GPUリソース当たりのスループット)を達成した。
1回あたりの生成に必要なキャッシュ使用量が小さいため、同じGPUメモリの予算内であっても複数の生成結果を並列に得ることが可能となっている。
なお、今回開発された技術の成果は、7月2日より米国サンディエゴで開催される自然言語処理分野のトップカンファレンス「ACL 2026」のオーラルセッションにて発表される予定だ。