



三菱電機株式会社は、エッジデバイスで動作する製造業向けの言語モデルを開発した。
この言語モデルは、三菱電機のAI技術「Maisart(マイサート)」の開発成果であり、同社の事業に関するデータを用いて製造業ドメインに特化した事前学習をさせているため、製造業におけるさまざまなユースケースへの適用が可能とのことだ。
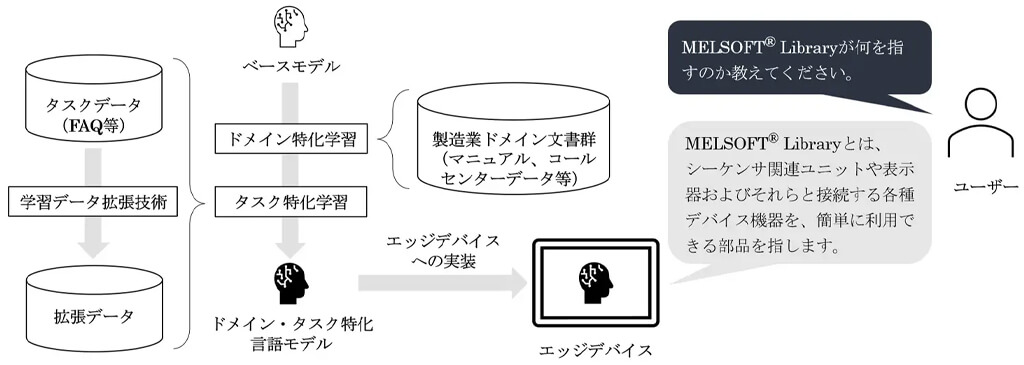
具体的には、公開されている日本語継続事前学習済みのベースモデルに対し、同社が保有するFA(Factory Automation)事業などのさまざまなデータを用いたドメイン特化型の学習を行うことで、製造業に特化した言語モデルを開発した。
LLM勉強会が公開しているオープンなモデルをベースモデルとし、製品マニュアルやコールセンター応対履歴など、同社が独自に保有する権利的・倫理的に問題のないデータで学習している。
さらに、独自に開発した学習データ拡張技術により、ユーザの用途に最適化した回答生成を実現する。また、独自の拡張技術で生成した学習データを用いることにより、効果的なタスク特化学習を可能としている。
具体的には、問い合わせや文章生成指示などの入力内容に対して「望ましい回答」が紐付けられた用途別学習用データから、正しい回答例文とテキストの類似性は高いが、入力された問いに対する回答としては正しくない回答テキストを抽出する。これを同一入力に対する「望ましくない回答」と見なすことで、ある入力に対する「望ましい回答」と「望ましくない回答」のペアを疑似的に自動生成し、望ましい表現を出力しやすい言語モデルの学習用データを充実化させている。
また、製造業のユーザが個別に保有する用途別データを用いた追加学習も可能で、これによりユーザごとに異なる用途に最適化した回答生成が可能な言語モデルを構築することができる。

同社がFA製品に関する知識の正誤を問うタスクで評価を実施したところ、ドメイン・タスク特化学習により、75%を超える正解率を達成したのだという。
なお、開発された言語モデルは、モデル圧縮技術により軽量化することで、メモリ不足により実行不可能だったエッジデバイスにおいても動作可能であることが確認されている。
これにより、限られたハードウェアリソースの中でも動作することができ、低遅延かつプライバシーに配慮した処理が可能なため、エッジデバイスなど計算リソースに制約のある環境や、顧客情報を扱うコールセンターなどのオンプレミス環境下における生成AI運用にも活用することができる。
今後は、2026年度中の製品適用を目指し、産業機器やロボットなどのデバイス上で言語モデルを動作させるユースケースの検討および社内外での実機実証を進めていく計画だ。