



「RNAアプタマー」は、抗体医薬品に代わるポテンシャルを持っており、次世代の中分子医薬品として注目されている。
一方で、有望な候補配列の探索や、製造コストを下げるための最適化(短鎖化)に膨大な実験と時間を要することが課題となっていた。
特に、候補配列を短く加工する工程は、品質を維持しながらコストを削減するために重要だが、従来の実験手法では試行錯誤への依存度が高かった。
こうした中、早稲田大学と株式会社リボミックなどの研究グループは、大規模言語モデル(LLM)を応用し、RNAアプタマーの結合活性を高精度に評価する新技術「RaptScore(ラプトスコア)」を開発したと発表した。
同技術は、文章生成などに用いられる大規模言語モデルの仕組みをバイオインフォマティクスに応用したものだ。
DNAの塩基配列を学習済みのモデル(DNABERT)をベースに、アプタマー選抜実験(SELEX法)のデータで調整を行うことで、対象となる配列が標的物質に対して「どれくらい結合しやすい自然なパターンか」をスコア化することに成功した。
これにより、従来の頻度解析による評価手法では不可能だった、実験データに含まれていない「未知の配列」や「長さの異なる配列」の結合活性をコンピュータ上で予測することが可能となった。

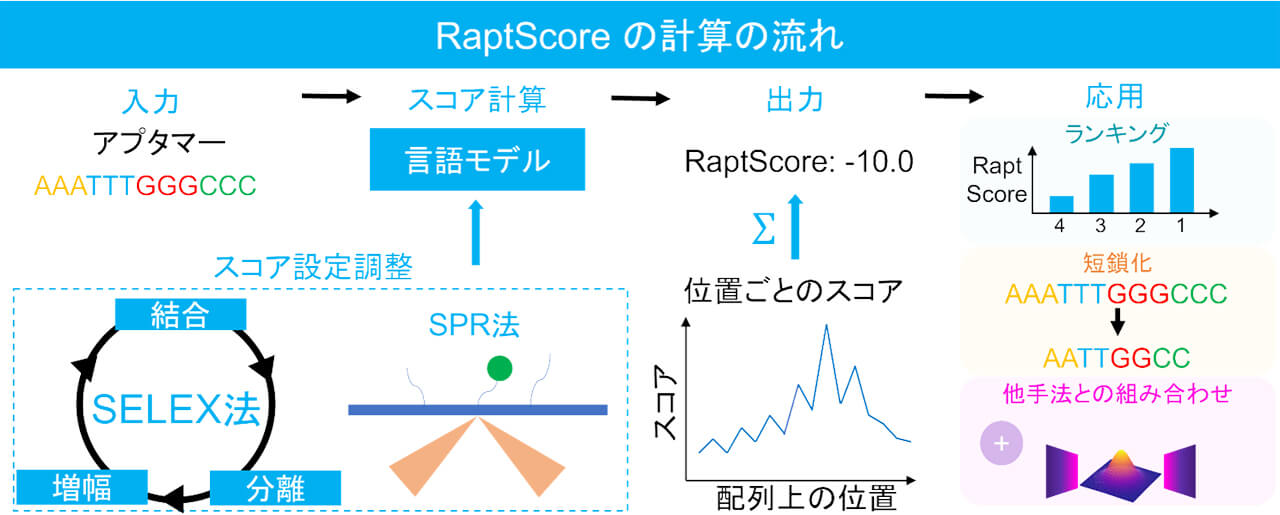
ビジネス視点での最大のインパクトは、医薬品化のプロセスにおけるコスト削減効果である。RNAアプタマー医薬品は、配列が短いほど化学合成時の製造コストが下がり、品質管理も容易になる特徴がある。
実証実験では、RaptScoreが高い値を示すように配列を削ることで、実際の実験を行わずとも、結合活性を維持・向上させながら配列の長さを最大3割削減できることが確認された。
これにより、開発のボトルネックとなっていた最適化プロセスが劇的に効率化される可能性があるとのことだ。
なお、早稲田大学は、これまでもアプタマー生成AI「RaptGen」を開発しており、今回の評価技術と組み合わせることで、AIが生成した多数の候補から、実際に実験すべき有望な候補を高確率で選抜するフローを確立した形だ。
研究チームは今後、現在の塩基配列情報に加え、RNAの3次元立体構造の情報も統合することで、予測精度をさらに高める方針だ。