



前回は、GDEPアドバンスの「 DeepLearning BOX」で、データセット「MNIST」の画像認識を「TensorFlow」「Cognitive Toolkit(CNTK)」を使って深層学習させる様子を紹介した。
好みのフレームワークが自由に使える環境であることが確認できたと思う。
今回は、Linux版の「DeepLearning BOX」で、「DIGITS + Caffe」を使って画像認識させる様子を紹介する。
前編は、データセットを作成する方法を紹介する。
使用環境
今回の使用環境は以下のとおり。
「DeepLearning BOX」には、あらかじめいくつかの深層学習フレームワークがプリインストールされていて、利用可能な状態になっている。
今回使用する「DIGITS + Caffe」も、プリインストールされているフレームワークのひとつで、日本語に翻訳された「DIGITSのマニュアル」と併せてデスクトップ上にショートカットが用意されていた。
DIGITSとは
DIGITS(ディジッツ)は、NVIDIAが提供しているWebベースのディープラーニングトレーニングシステム。
ディープラーニングで使うデータセットの作成、学習モデルの作成、学習過程の可視化、レイヤーの可視化などをサポートしている。
DIGITSは、CaffeやTensorFlowといった多くの深層学習フレームワークと連携。
「DeepLearning BOX」上のDIGITSは、Caffeを使ってディープラーニングできるようセットアップされている。


Caffeとは
Caffe(カフェ)は、Berkeley AI Research (BAIR) / The Berkeley Vision and Learning Center (BVLC)とコミュニティによって開発されたオープンソース・ソフトウェアの深層学習フレームワークで、主に画像認識を得意とする。
「コマンドライン」「Python」「MATLABのインターフェイス」などから利用できる。
コアエンジンはC++/CUDAで作られており、GPUをシームレスに使いわけることで、高速な実行が可能になっている。
また、CaffeはGitHubを中心とした開発コミュニティが活発であることも知られている。
DIGITS + Caffeで画像処理
今回は、DIGITSのチュートリアルにあるセマンティック・セグメンテーションを使った深層学習を試して見たい。
セマンティック・セグメンテーションとは、画像ファイルを読み込み、その画像ファイル内にある画素から対象物(オブジェクト)を識別、分類することを指す。
使うのはセマンティック・セグメンテーションをする際によく利用される「PASCAL VOC2012」という約2GBのデータセット。
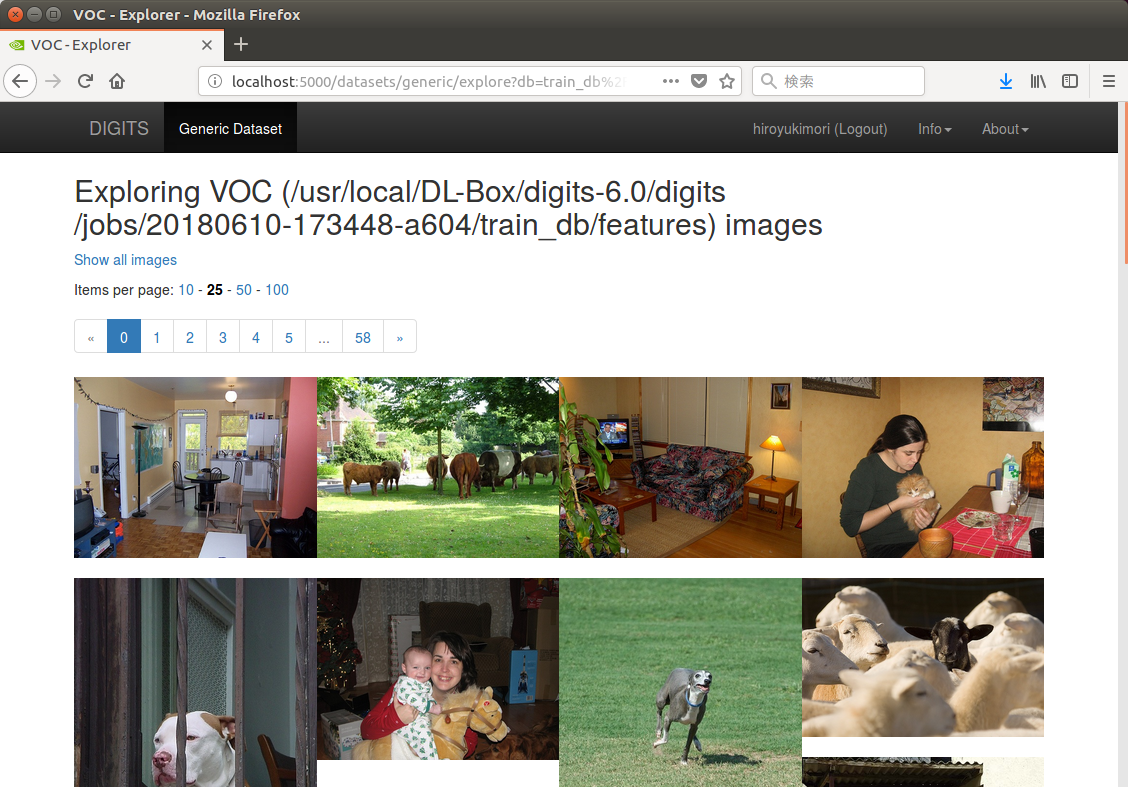
このデータセットには、以下のような画像データと、その中の物体位置を示すラベル画像が組み合わさって含まれている。



画像に写った物体を識別するには、合わせて「画像に写る物体が何か」といったラベルも必要になる。
そこで、このVOCイメージに「写る物体が何であるか」を示すラベルデータもデータセットに含めている。
このデータは、ラベルイメージの画像に表示されている色の部分が何の物体であるかを表す凡例データになっていて、それぞれの色に対応する対象物名を示すテキストファイルとなっている。
「PASCAL VOC2012」のデータセットには、「人物」「動物」「乗り物」「屋内の風景」といった画像で構成されている。
これらの「テキスト」「イメージ」「ラベルイメージ」をトレーニングデータとして使い、画像に写る物体を識別するモデルを作成する。
次ページ:データセットの取り込み
データセットの取り込み
まずはDIGITSを起動し、データセットを取り込む。
DIGITSは、「DeepLearning BOX」のデスクトップにあるショートカットをダブルクリックすれば起動する。
起動すると、自動的にブラウザーが立ち上がり、DIGITSのトップページが表示される。
ここから、まずDataSetsのタブを開き、新しいデータセットを作成する。
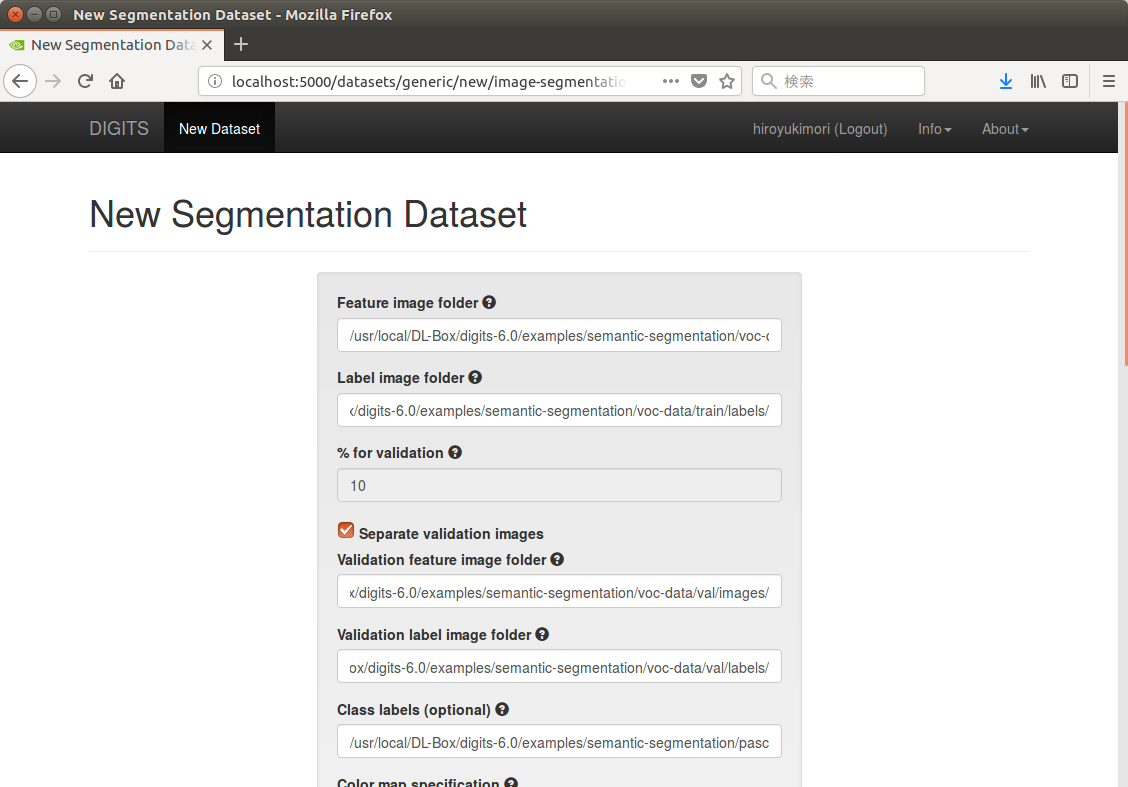

データセットの取り込みはバッチ処理で行なわれており、しばらくしてから、DIGITSのDataSetのジョブを確認すると、およそ30秒程度で取り込みが終わっていることが確認できる。
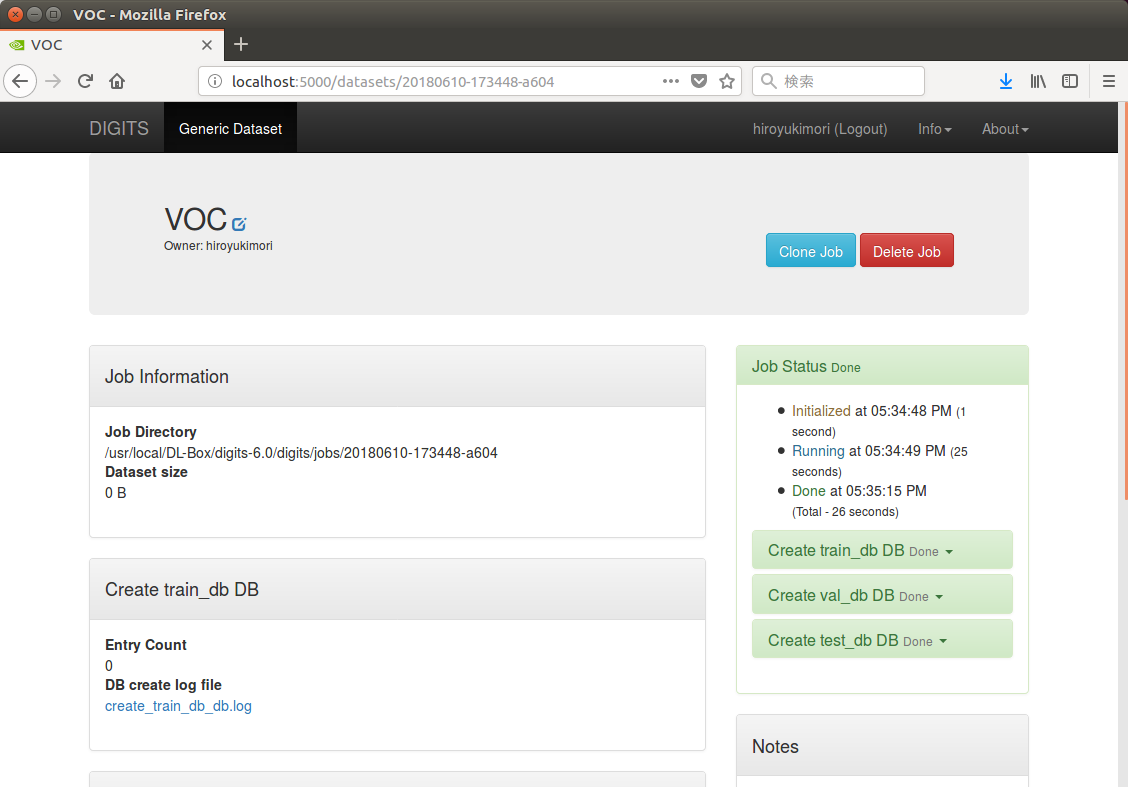
作成したデータセットは、DIGITSのDataSetsから確認することができる。
セマンティック・セグメンテーションを行なうモデルの作成
ここまでの流れを整理すると、セマンティック・セグメンテーションでは、画像データから「対象物の抽出」と「対象物が何であるか」を識別するため、その学習データとして、2GBの画像データとラベルデータを取り込んだ。
次の作業はモデルの学習だが、こちらもDIGITSのWebインターフェイスから設定・実行することができる。
モデルの作成は、DIGITSのインターフェイスから必要となる項目の設定や深層学習で使うニューラルネットワーク※のトポロジーをJSON形式のテキストで指定することができる。
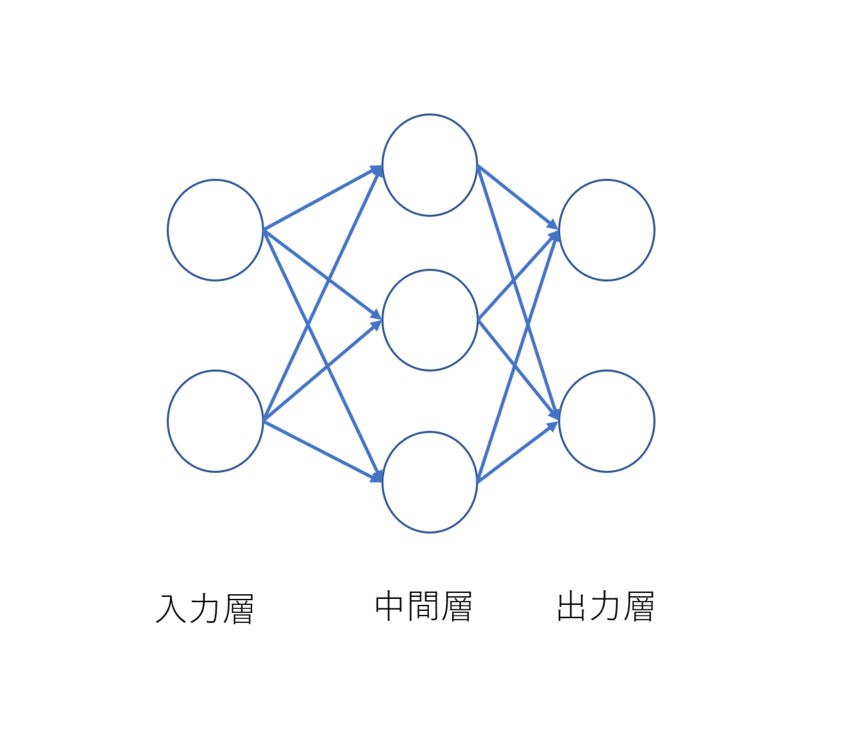
ニューラルネットワークとは
ニューラルネットワークとは、人間の脳の仕組みであるニューロンからヒントを得て数理モデル化したものを指す。


ちなみにこの式のxは入力値、wが重み付け、bがバイアスとなり、これらのパラメータの内容で0または1と判定できるようパラメータを調整する。
複数の入力を受け判定をするこのようなアルゴリズムを「パーセプトロン」と呼び、ニューラルネットワークの起源となった考え方である。
このニューロンを模した個々の数式をつなぎ合わせ、何層にもなる階層を作り、つなぎ合わせた演算結果から入力を判定することから、これらをニューラルネットワークと呼ぶ。

モデルの作成
それでは実際にモデルの作成しよう。
DIGITSのHome画面からModelsに切り替え、新しいモデルを作成すると、以下のような画面に遷移する。
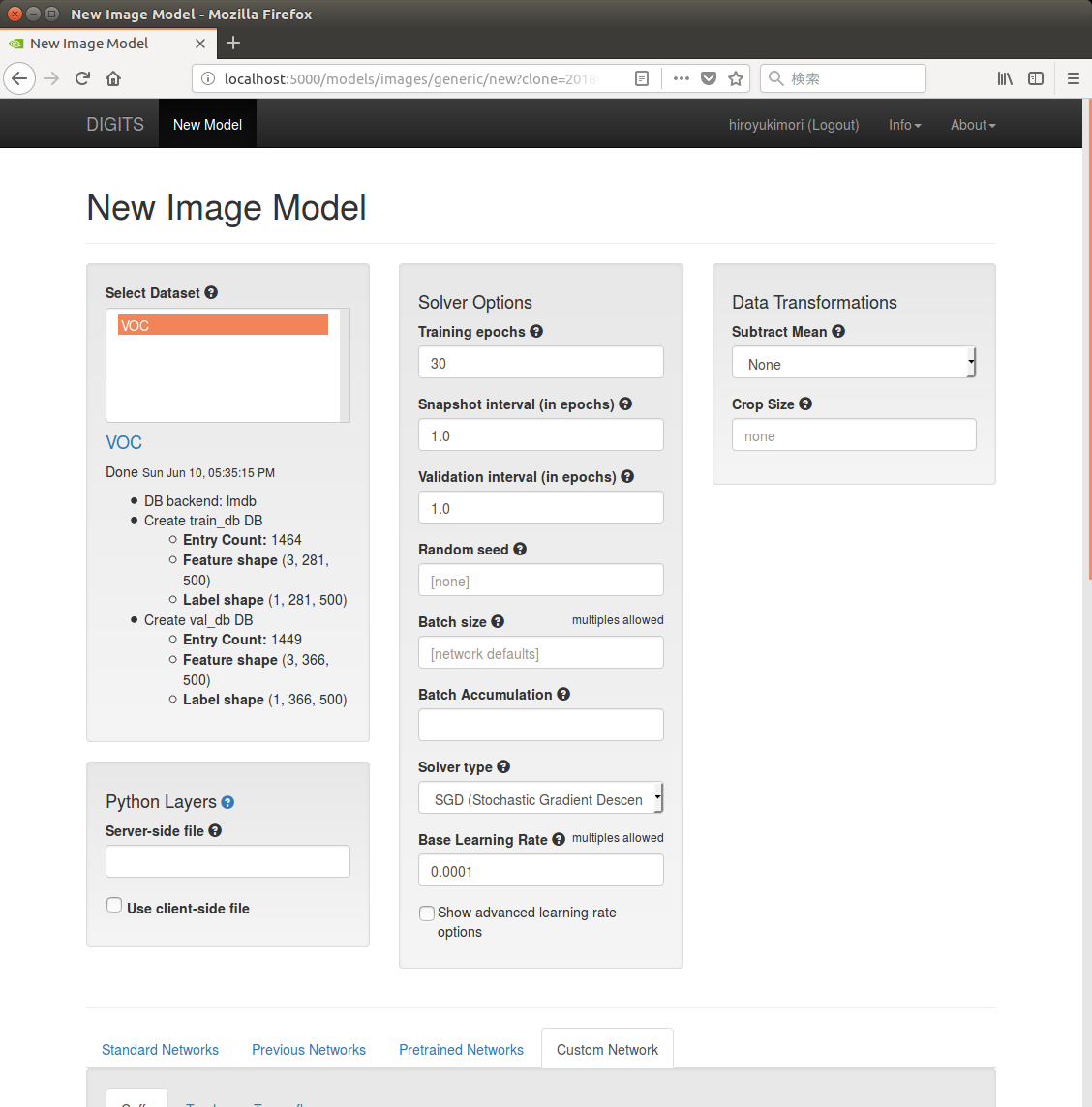

前回作成した「PASCAL VOC2012」のデータセットを選択し、必要なパラメータを入力する。
中でもニューラルネットワークのトポロジーを指定すると、視覚化して内容を確認することができる。
パラメータの入力が終わったら、モデルのトレーニングを開始しよう。
次ページ:モデルのトレーニング
モデルのトレーニング
モデル作成の際に「Create」をクリックすると、モデルをトレーニングするジョブが実行される。
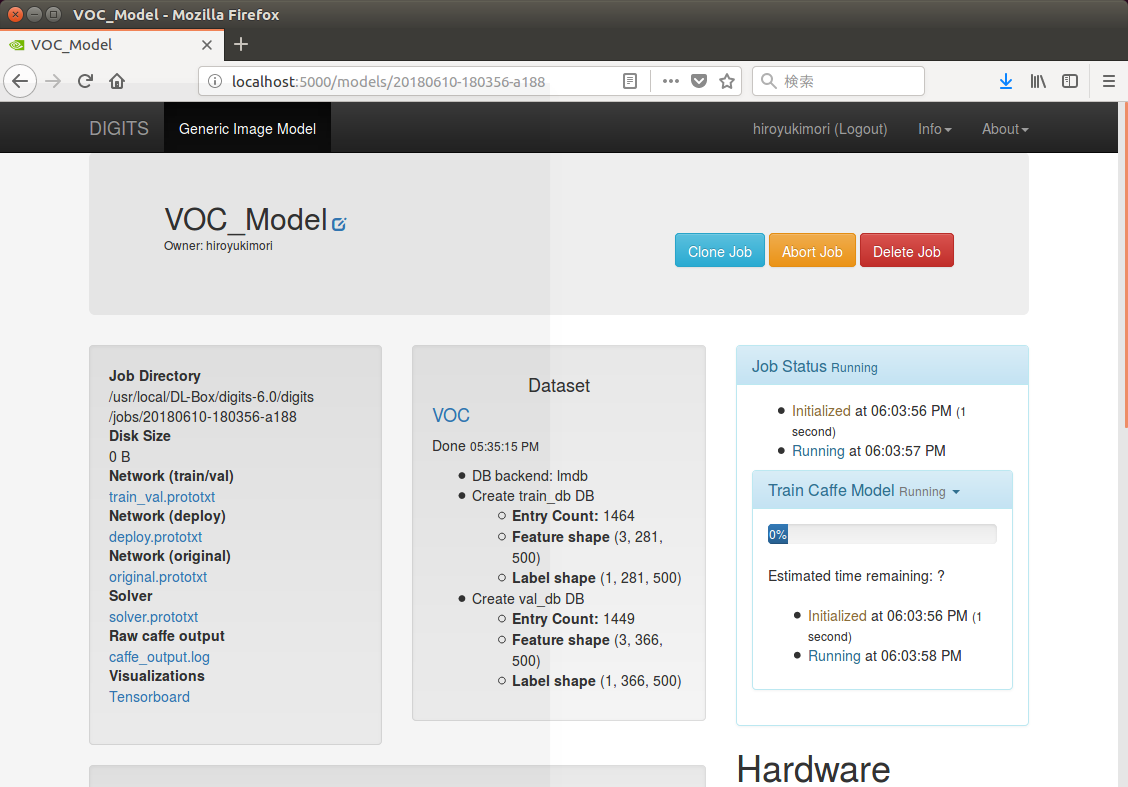
ジョブが実行されている間、その学習の遷移は学習中も常に更新されており、その様子はDIGITSのインターフェイスから進捗状況を確認することができる。
モデルの学習は、今回の実施したものでおよそ5時間で終了した。
モデルの学習が終了すると、インターフェイスがグリーンになる。
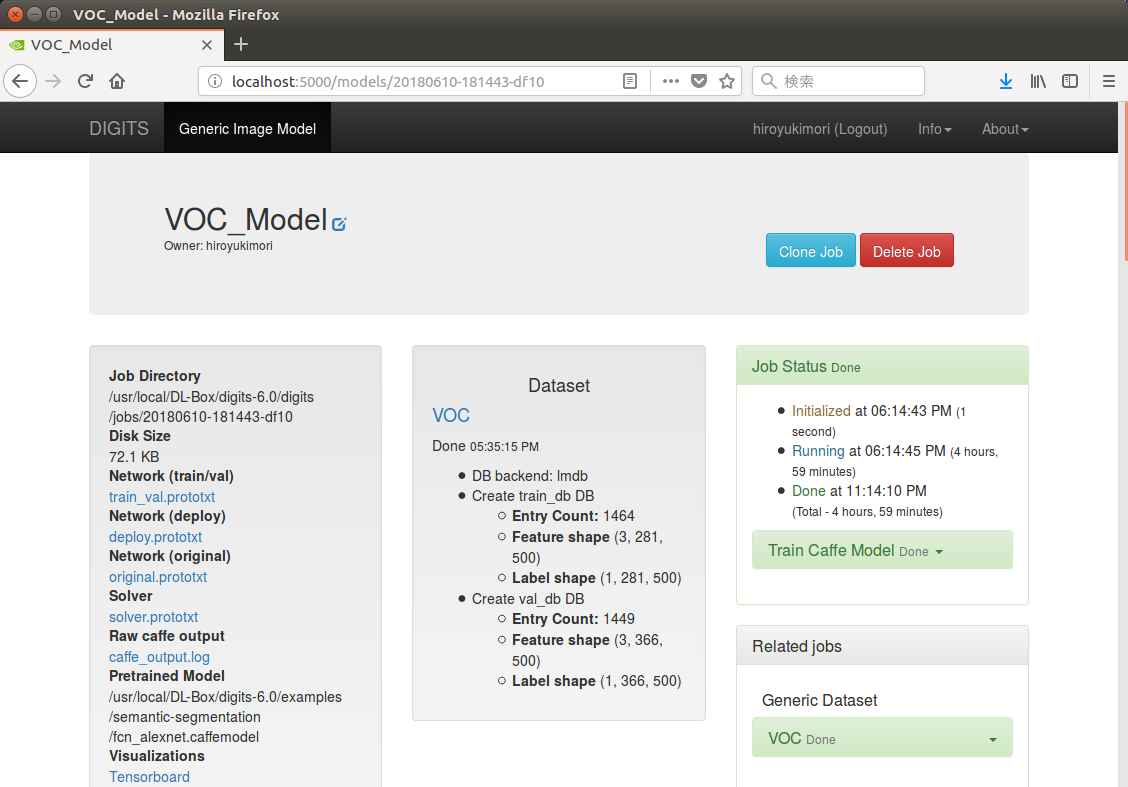
「トレーニングの進行状況」や「CPU/GPUの使用率」「メモリの使用状況」「ハードウェアの温度」などの各種レポートは、学習を行っている間もリアルタイムに更新され、グラフで視覚化された状態で確認できる。
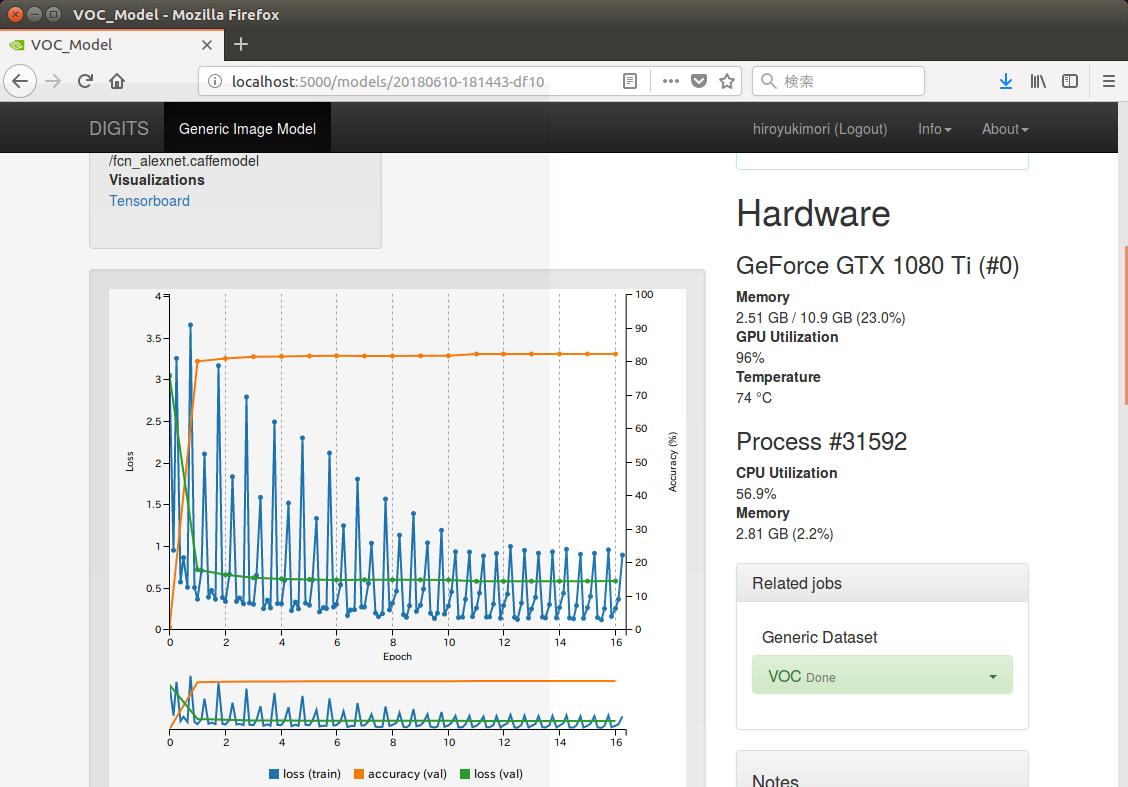
以下は、学習が完了した時点までのモデルの正確さを時系列で表わしたグラフである。
学習の進み具合を示す横軸(Epoch)が進むにつれて、学習時および検証時のロスが減り、「正確さ」が早期の段階で80%を超えて、その後、緩やかに80%以上で安定する様子が確認できる。
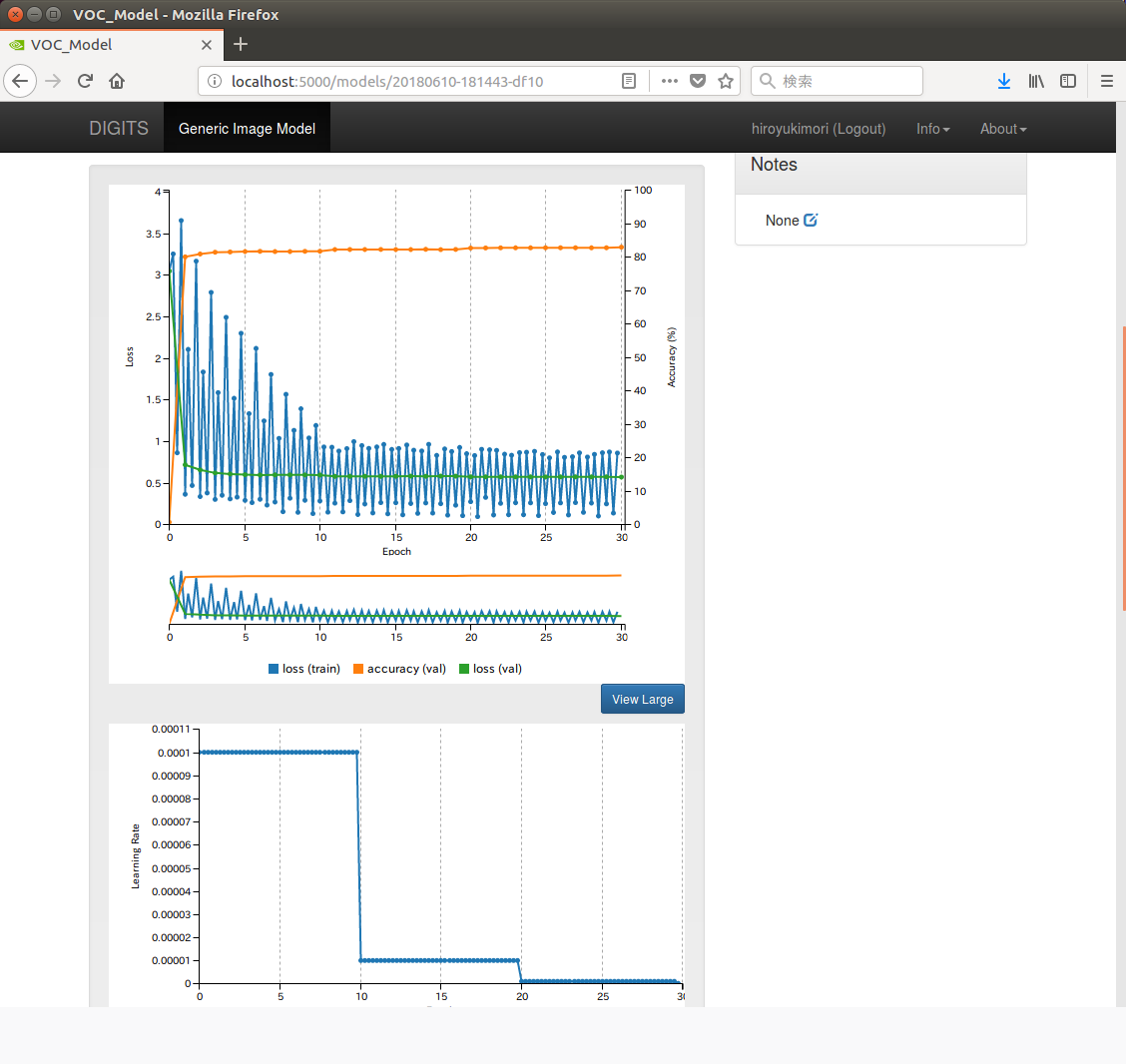

モデルのテスト
それでは、実際にトレーニングされたモデルを使ってテストしよう。
テストも同じくDIGITSのModelsの画面から行なうことができる。
トレーニングが完了するとグラフの下に、モデルのダウンロードのための項目とテストのための項目がが現れる。
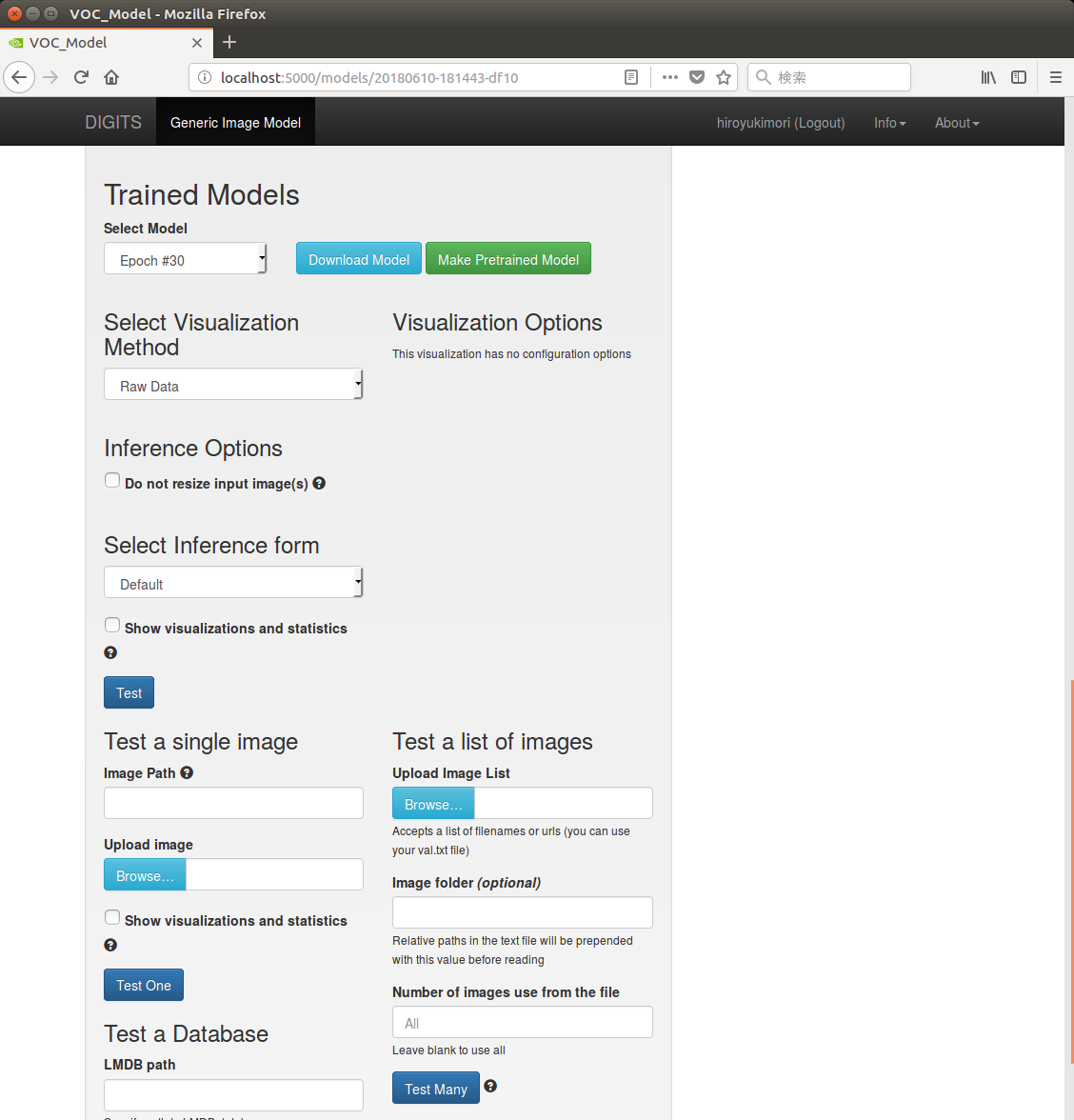

「Test a single image」の欄にあるUpload imageから、トレーニングに使った画像を読み込ませると、以下のように識別された。
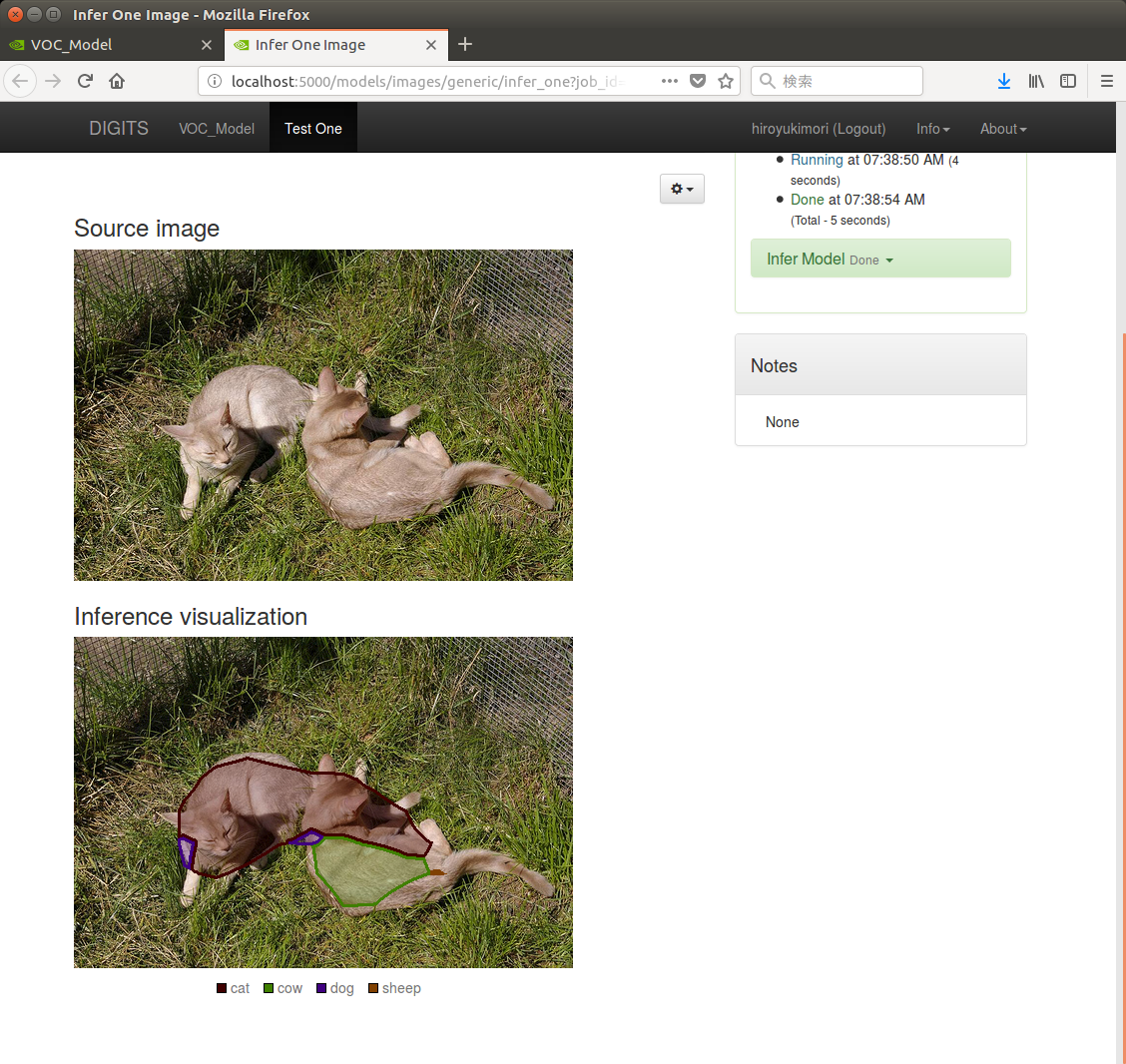
上の猫は「cat」または一部を「dog」と判定されており、下の猫は「cow」や「sheep」と判定されたようである。
次に、手持ちの画像をアップロードして判定したところ、結果は下図のようになった。
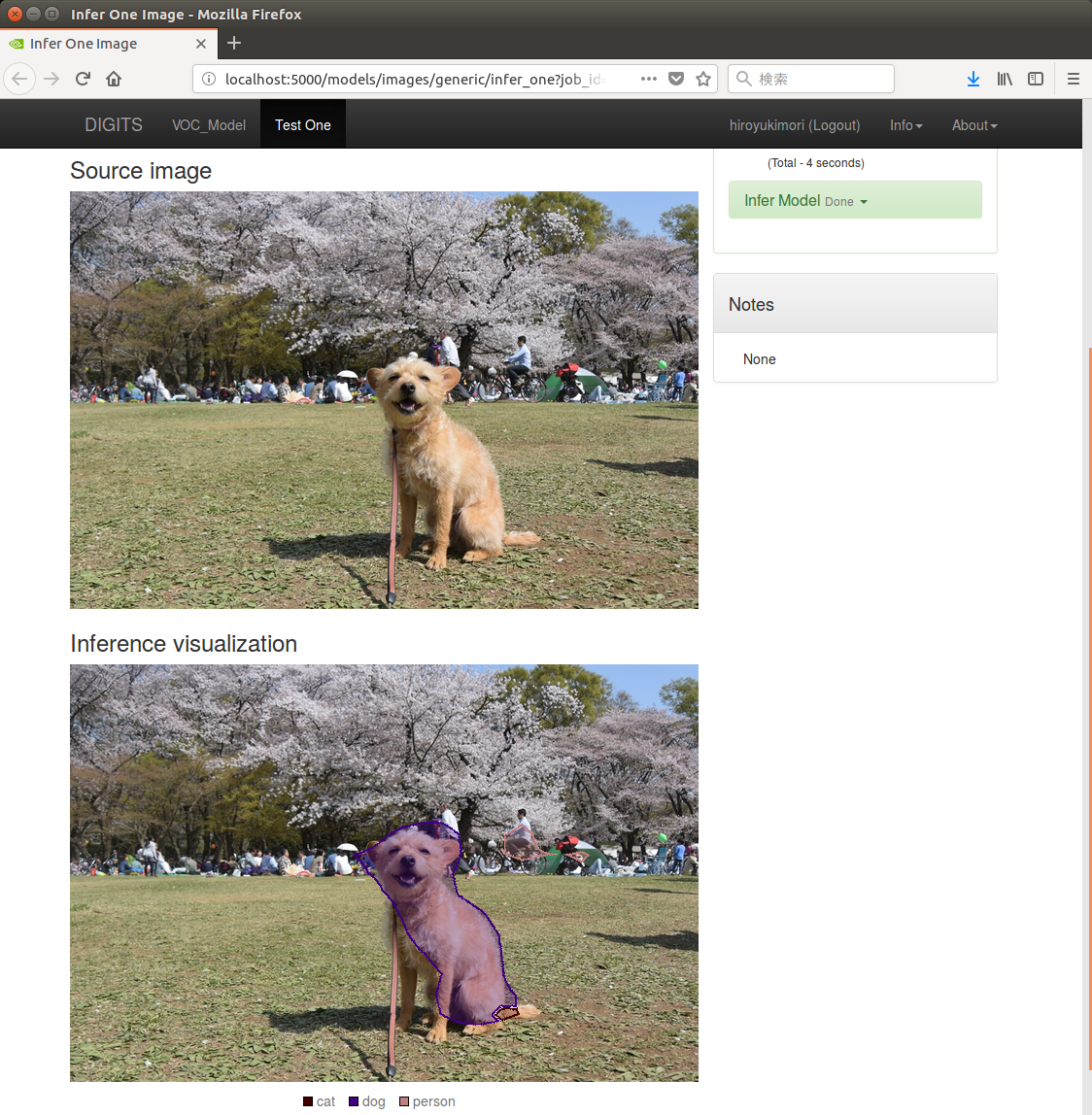

全面に写っている犬はしっかりと「dog」と識別されており、一部に「cat」と識別がされているようである。奥に「person」と識別されている枠も見られた。
ディープラーニングに最適なマシン
2回にわたって「DeepLearning BOX」を使った深層学習を行う様子を紹介してきたが、初学者の筆者であってもスムーズにディープラーニングを始めることができた。
筆者も自己学習のため、自前で環境を用意して深層学習のサンプルなどの実行を行ったが、深層学習で使用するツールやフレームワークは、特定のOS・ハードウェアといった環境に依存するケースや、使用するライブラリやフレームワークのバージョンの組み合わせが厳密にあってないと動作しないなど、調整が非常に難しく、フレームワークに付属するサンプルの実行すらうまく動作しない場合もあった。
「DeepLearning BOX」は、ディープラーニングに必要な「ハードウェア」や「フレームワーク」「ツール」「ライブラリ」がきっちりとまとめられており、ディープラーニングしたいエンジニアが、幅広く利用できるマシンと言えるだろう。
【関連リンク】
・DeepLearning BOX