



多くの企業において、重要なデータがSaaSツール、ファイルサーバー、データベースなどに点在し、データのサイロ化や分析の遅延といった課題を引き起こしています。
例えば、営業データはCRM、顧客対応履歴はヘルプデスクツール、財務データは会計システムといった具合に、情報が各システム内に閉じ込められることで、部門横断的な分析が困難になります。
また、各システムから必要なデータを集める際には、手作業でエクスポートし、整形・統合する作業が発生します。
さらに、同じ指標でも、システムによって定義や集計方法が異なる場合、どの数字が正しいのかが分からなくなる「データ不信」の状態を招きます。
従来のビジネスインテリジェンス(BI)ツールやデータウェアハウス(DWH)構築は、これらの課題解決に有効ですが、大規模な初期投資と専門的な工数を要します。
そこで本記事では、ノーコード・ローコードでAIアプリケーション開発ができる「Dify」を活用し、社内の散らばったデータを自動収集・分析するための「データベース構築と連携の設計思想」について解説します。
Difyとは?AIアプリケーション開発のための統合プラットフォーム
Difyは、LLM(大規模言語モデル)を活用し、実用的なAIアプリケーションを迅速に構築・運用するための、オープンソースのノーコード・ローコードプラットフォームです。
従来のAI開発では、モデルの選定、プロンプトの設計、データ連携、インターフェースの構築などを個別に進める必要がありましたが、Difyはこれらを統合し、以下の主要な機能を提供します。
| 機能名称 | 概要 | Difyを活用した効果 |
|---|---|---|
| RAG(Retrieval-Augmented Generation)機能 | 社内のドキュメントやデータ(知識)を取り込み、AIが参照できるようにする機能。 | 最新の社内情報や非構造化データに基づいた、信頼性の高い回答をAIに生成させることが可能。 |
| プロンプトオーケストレーション | 目的のタスクに合わせたプロンプト(指示)の設計、デバッグ、バージョン管理を一元的に行える。 | AIの出力を安定させ、ビジネスロジックに沿った形でAIを運用・改善していくことが容易になる。 |
| ツール(Function Calling)連携 | 外部のアプリケーション(SaaSやデータベースのAPI)とAIを接続し、AIが自律的に外部システムを操作して情報を取得・実行できるようにする。 | 散在する構造化データやSaaSのリアルタイムデータにAIがアクセスし、より実践的なタスク実行や分析を可能にする。 |
| Webアプリへのデプロイ | 開発したAIアプリケーションを、すぐに利用可能なWebインターフェースとして公開できる。 | 開発後すぐに社内ユーザーが利用できる状態にでき、利用部門への展開を迅速に行える。 |
Difyは、こうした機能により、データ分析を専門としないユーザーでも、AIを中心とした新しいデータ連携・分析基盤を迅速に構築することを可能にします。
また、初期段階で大規模なデータパイプラインを必要とせず、基盤となるLLMの切り替えやプロンプトの調整が容易で、スモールスタートが可能なのもDifyの利点です。
まずは特定の部門やデータセットに絞ってRAGやツール連携を試し、フィードバックを得ながら分析範囲を拡張するアジャイルな開発に適しています。
データの「正しい形」とは?AI分析に適したデータ構造の原則
データ分析を行う際、データを集めることは必須となりますが、データをどんなに大量に集めても、AIがその意味(構造、文脈)を理解できなければ、分析や推論はできません。
そのため、集めたデータをAIが理解できるよう「正しい形」に整理する必要があります。
この「正しい形」を理解するために、まず社内のデータを大きく「整理されたデータ」と「文書データ」の2種類に分けて考えましょう。なお、2つのデータはそれぞれ「構造化データ」と「非構造化データ」と呼ばれます。
「整理されたデータ」(構造化データ)の設計
「整理されたデータ」とは、Excelの表やデータベースのように、行と列で意味が明確に定義されているデータです。例えば、顧客リスト、販売実績、在庫数などがこれにあたります。
これらのデータを、AIの計算と推論を助ける設計にするには、「売上データ」と「顧客データ」のように、関連する情報がバラバラにならないよう、共通のID(キー)で結びつけておくことが重要です。
これによりAIは、「A社の最新の売上は?」という質問に対し、顧客情報と売上実績を正しく結びつけて分析できます。
Difyにおいても、AIがこれらのデータにアクセスする際、定義されたデータ構造を基に、どの情報(列や行)が必要かを判断します。
この設計が、AIの計算精度や判断の的確さに直接左右します。
「文書データ」(非構造化データ)の整理と文脈化
「文書データ」とは、形式が決まっていないテキストやファイルのことです。
例えば、社内マニュアル、議事録、顧客からのメール本文、PDFのレポートなどがこれにあたります。
文書データは、そのままではAIが効率的に参照できないため、意味の塊(セクション、パラグラフ)ごとに小さく分割し、それぞれの「文脈」を保った断片(チャンク)にします。
そして、分割した各文書の断片に対して、「作成部署」「作成日」「対象製品」といったタグや付帯情報(メタデータ)を付け加えます。
Difyにおいては、RAG機能に文書データを取り込む際、このメタデータを設定します。
メタデータを設定しておけば、AIはタグや付帯情報を使って、文脈に合った情報だけを素早く見つけ出すことができるようになります。
データ定義の一貫性
AIが構造化データと非構造化データを正しく読み込めたとしても、その中のデータの定義がズレていると、AIの提示する答えも信頼性を失います。
例えば、営業部門の「売上」と、経理部門の「売上」の定義が異なっていた場合、「今月の売上はいくらですか?」という質問にAIが答えても、その数字が何を意味するのか、利用者は混乱してしまいます。
この問題を避けるために、全社で「真実の単一ソース」を確立する必要があります。
具体的には、顧客名、製品コードなどの、会社で最も重要な情報をマスターデータとして一元的に管理し、全システムで共有する一意のIDを割り当てます。
Difyにおいては、このマスターデータをiPaaSやワークフローツールを活用して、連携する各アプリケーションからDifyへデータを取り込む際の照合と変換のプロセスに組み込みます。
これにより、AIが「顧客A」を参照した際、どのシステムから情報を取得しても、同じ実体を参照している状態を保証します。
また、用語・単位の統一する必要があります。「見込み客」の定義、「月次」の締め日など、ビジネス上の主要な用語と単位を標準化し、全ての連携アプリケーションでその標準に従います。
このように、AIを活用するには「AIが質問の意図を理解し、その質問に対する答えを導き出すために必要な文脈情報と関連性が明確な形でのデータ化」が必須です。
Difyの機能を使ったデータ収集・連携アーキテクチャ
データは、大きく分けて「整理されたデータ」(構造化データ)と「文書データ」(非構造化データ)の2種類があることをご理解いただけたと思います。
では次に、Difyがこれらの異なる性質を持つデータを、どのように取り込み、分析を可能にするのかを解説します。
非構造化データの取り込み
社内のマニュアル、過去の議事録、顧客からのメール、製品仕様書といった非構造化データは、DifyのRAG機能を活用することで、AIが参照可能な「知識」として取り込みます。
RAGとは、生成AIに外部の信情報源を読み込ませ、その情報に基づいて回答を生成させる技術のことです。
これにより、AIがインターネット上の汎用的な知識ではなく、企業独自のノウハウに基づいた回答を生成することができます。
まずは、社内のファイルサーバーやSharePoint、Google Driveなどから、PDF、DOCX、TXT、CSVといったドキュメントを収集し、Difyの知識検索ノードのナレッジセクションにアップロードします。
この際、Difyが自動的にデータを処理し、チャンク分割を行います。
チャンクが分割された後は、分析精度を高めるため、各ファイルやチャンクに対し、「部門」「プロジェクト名」「最終更新日」などのメタデータを付与します。
そして、Difyがこれらのドキュメントをベクトル(数値データ)に変換し、ベクトルデータベースに格納します。
この一連の流れにより、ユーザーが質問をすると、AIはその質問の意図をベクトル化し、ナレッジベースから最も関連性の高いドキュメントのチャンクを検索することで、その情報を基に回答を生成します。
構造化データの連携
一方、営業実績、顧客属性、在庫数など、リアルタイム性や計算精度が求められる整理されたデータ(構造化データ)は、前述のRAGのようにファイルを格納するのではなく、Function Calling(関数呼び出し)メカニズムを通じて、外部システムと連携します。
Function Callingは、LLMが外部ツール(API)を使うための、ツール呼び出しメカニズムです。
RAGがデータをDify内に格納するのに対し、Function Callingはセキュリティと柔軟性を考慮し、直接接続しません。
間にAPIゲートウェイや軽量なAPIサーバーを挟み、CRMやERPなどのシステムに対し、データ参照や更新を実行するためのAPIを構築します。
そして、このAPI仕様を、Difyの「ツール」として事前登録します。
これにより、ユーザーが「今週のリード獲得数を部署ごとに集計して」と尋ねると、AIは登録されているツールの中から「リード獲得数を取得するAPI」を自律的に判断し、適切なパラメーターを指定してAPIを呼び出します。
APIはデータベースからデータを取得し、その結果をAIに返します。
このようにAPI呼び出しを行うことで、常に最新のデータを分析に利用できます。
また、Difyにデータベースの接続情報を直接持たせず、API経由でアクセス権を制御できるため、セキュリティを確保できるというメリットもあります。
このようにDifyは、RAG機能によるデータの参照と、Function CallingメカニズムによるAPI連携により、2つの異なるデータを連携させる機能を一つのプラットフォームで統合的に提供します。
データフローの自動化とDifyへの接続
非構造化データにせよ、構造化データにせよ、点在するデータはDifyに連携する前に、統合・変換する必要があります。
この役割を担うのが、iPaaS(Integration Platform as a Service)などのワークフロー自動化ツールです。
Zapier、Make、Power AutomateなどのiPaaSツールを活用することで、点在する複数のデータソースからデータを抽出し、第1章で定義した「正しい形」(マスターデータと紐づいたクリーンな構造)に変換します。
そして、整理・統合されたデータを、構造化データの場合は連携用データベースに格納し、Difyの「ツール」から常にアクセスできるようにします。
非構造化データの場合は、Difyのデータソースを集約するナレッジベースへ、新規・更新ドキュメントを自動でアップロードするように設定します。
こうすることで、データの抽出から整理・統合、データベースへの格納といったデータフローを自動化することができます。
実現可能なAI分析のユースケース例
ここまでで、データを「正しい形」に設計する方法と、Difyによる連携アーキテクチャ構築の流れを見てきました。
次は、構築した連携基盤を活用し、ビジネスの現場で実現可能な具体的なAI分析のユースケースをご紹介します。
営業・マーケティング部門:パフォーマンスの分析と戦略策定
営業・マーケティング部門では、リアルタイムな構造化データと、過去の戦略文書という性質の異なるデータを組み合わせて分析します。
例えば、営業戦略の立案をサポートするために、ユーザーが「A製品のキャンペーン成功要因と実績の推移を分析して」とDifyに質問したとします。
これに対しDifyは、まずツールを用いて最新の販売実績データベース(構造化データ)にアクセスし、A製品の売上推移を取得します。
同時に、ナレッジベースから「キャンペーン計画書」や「営業マニュアル」(非構造化データ)を検索し、戦略文書を検索します。
AIは、これらの定量的データと戦略文書を照合・推論し、「高い実績は、戦略文書にあったSNS限定プロモーションの実施時期と一致しており、特に若年層へのリーチが成功要因と見られます」といった具体的な示唆を返します。
また、リードの優先順位付けとリスク評価も可能です。
ユーザーが「B社が失注に至る可能性を評価し、次に打つべき具体的な施策を提案して」と質問すると、DifyはツールでCRMデータにアクセスしてB社の現状を取得し、ナレッジベースからは類似企業の過去の失注レポートを検索します。
AIはB社の現状と過去の失注パターンを比較し、「この段階で〇〇資料の提供がない点は失注リスク大。過去事例より、次のアクションとして製品のROIをまとめた〇〇ドキュメントを提供すべきです」とリスク評価と具体的な施策を提案します。
カスタマーサポート・製品開発部門:ナレッジ活用と問題特定
この部門では、リアルタイムの顧客行動データと、過去に蓄積されたノウハウ文書を組み合わせ、顧客の真のニーズを把握し、製品改善に繋げます。
例えば、トラブル解決支援の効率化を図るため、オペレーターが「特定の顧客Aが過去に問い合わせたC製品のトラブル事例と、その解決策を要約して」と質問したとします。
これに対しDifyは、まずツールを用いてヘルプデスクのデータベースにアクセスし、顧客Aの問い合わせログ(構造化データ)を取得します。同時に、ナレッジベースからはC製品の関連マニュアルと技術者メモ(非構造化データ)を抽出します。
AIはこれらの情報源を統合し、「顧客A様は過去2回、電源エラーについて問い合わせています。解決策はマニュアルSection 3に記載の通り、設定Aの変更と再起動です」といった、顧客個別の状況に基づいた簡潔な解決手順を提示します。
また、潜在的な不具合の特定も可能です。
ユーザーが「ヘルプページへのアクセスが急増した製品と、その直前のリリース変更の関連性を分析して」と分析を依頼すると、Difyはツールを通じてアクセスログデータべースのデータ(構造化データ)を取得し、アクセス急増製品を特定。同時にナレッジベースからは、その製品のリリース履歴や仕様書(非構造化データ)を検索します。
AIはログの急増データとリリース日を時系列で結びつけ、「アクセス急増は〇月〇日に確認されました。これは、直前の〇月〇日にリリースされた『新機能X』に関するドキュメントが不十分であるため、ユーザーが混乱している可能性があります」といった、問題の仮説を提示します。
管理部門:業務プロセスの可視化と最適化
管理部門では、定量的なプロセス管理データと、その背景を記した定性的な文書を連携させ、組織のボトルネックを特定します。
例えば、業務効率のボトルネック分析として、「先週最も遅延したタスクの担当者と理由を分析して」と指示したとします。
これに対しDifyは、まずツールを用いてタスク管理SaaSのAPIにアクセスし、遅延したタスクのデータ(構造化データ)を特定。さらに、ナレッジベースからそのタスクに関する進捗報告書や日報(非構造化データ)を検索します。
AIは遅延の定量データと、報告書内の「仕様変更による手戻りが発生した」といった定性的な記述を結合し、「最も遅延したタスクは〇〇氏担当のAタスクで、報告書から、主に部門間の連携不足が原因であったと分析されます」と、具体的なボトルネックとその背景を特定します。
Difyを活用して社内に点在するデータをAIで分析してみた
では実際に、Difyを活用して簡易的なワークフローを構築することで、データ統合と分析の理解を深めていきます。
本章では、営業担当者の「リード確度評価と推奨アクションの提示」を自動化するワークフローをDifyで構築してみました。
このフローの目的は、点在する構造化データと非構造化データをAIで統合することです。
具体的には、ある顧客のIDを入力した後、属性情報取得し、知識検索、データ統合、確度評価、アクション生成という一連の流れが正しく機能するかを検証しました。
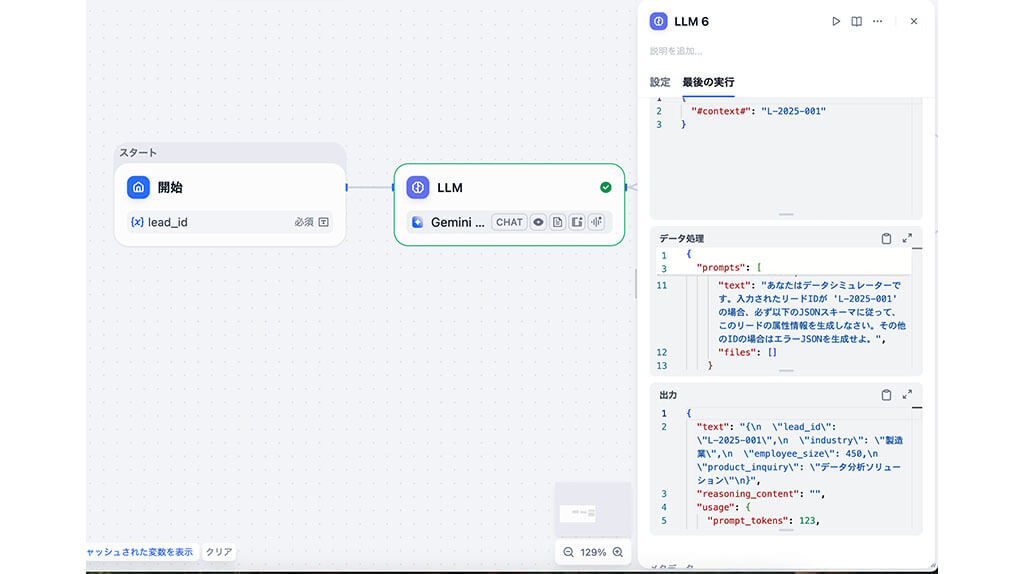
ステップ1:構造化データの取得
まず、AI分析のトリガーとなる情報(リードID)を入力し、必要なデータソースへのアクセスを開始するノードを構築します。
本来であれば、DifyはCRMなどの既存システムへ接続し、その都度、業種や従業員規模といった最新のリード属性をリアルタイムで取得します。
今回は、既存システムが存在しないため、あらかじめ設定したリード属性を次のプロセスへと受け渡す形にしました。
これにより、ユーザーが入力欄に仮のリードID「L-2025-001」と入力すると、「業種:製造業」「従業員規模:450」「問い合わせ製品:データ分析ソリューション」という構造化データを取得します。

ステップ 2: 非構造化データの取得
構造化データを取得したら、次は過去事例やノウハウといった非構造データを同時に取得させます。
活用するノードは知識検索ノードで、ナレッジベースという箇所に、反映させたい過去事例やノウハウをあらかじめ格納しておきます。こうすることで、AIは推論の根拠として格納されたデータを活用することができます。
そして、ナレッジベースに事例レポートを格納する際には、「業種:製造業」「従業員規模:400名」といったタグや付帯情報(メタデータ)を付与します。
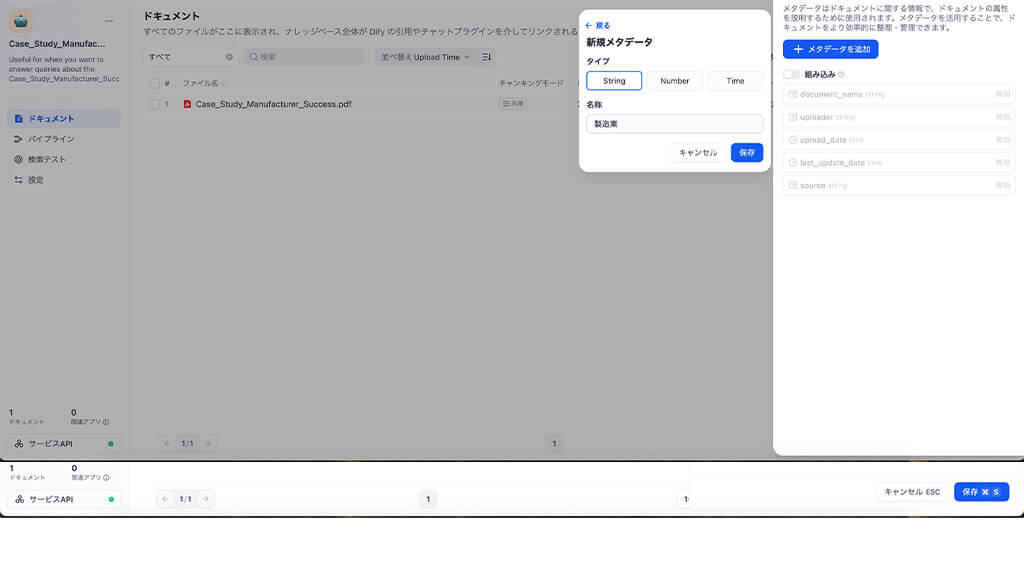
これにより、AIが膨大な文書の中から「製造業かつ従業員規模が400名程度」に合致する事例を見つけ出すことができます。
ステップ3:データ統合と分析準備
ステップ2で、構造化データと非構造データという異なるデータを取得しました。
ステップ3では、この異なるデータを、AIが分析しやすいように整形・統合します。
そこで、LLMノードを活用し、プロンプトにて「構造化データと非構造化データを解釈し、次のステップのAIがすぐに推論に使えるよう、簡潔で論理的な一つのレポートとしてまとめよ。」と指示します。

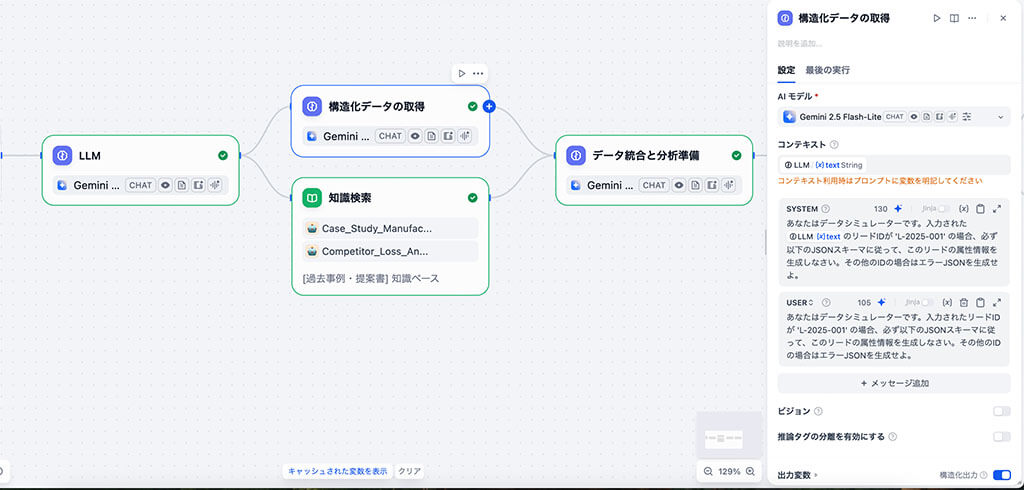
これによりAIは、両方の情報を解釈・結合し、次のステップのための一貫性のある文脈レポートとして整形・出力します。
ステップ 4:コア推論の実行
次は、ステップ3で出力された統合レポートを基に、ビジネスインテリジェンスの中核となる判断を下します。
ここでもLLMノードを活用し、過去の成功・失敗パターンと照合した上で、客観的な「受注確度スコア」と「リスク要因」を判断し、JSON形式で出力してもらいます。
システムプロンプトは以下の内容にしました。
あなたは厳密なJSONパーサーです。入力されたレポートを読み込み、リード属性と過去の受注・失注パターンの関連性を厳密に比較せよ。特に、成功事例に一致する要素(例:部門決定、コスト削減ニーズ)と、失注事例に一致する要素(例:カスタム要求、短納期要求)を特定し、その度合いに基づき客観的な受注確度(0-100)を判断せよ。出力は必ずJSON形式とし、他の説明やテキストは一切出力してはならない。
なお、JSON形式を強制している理由は、後続のノードや外部システムでの処理効率と正確性を保証するためです。
例えば、AIが「確度スコアは75%です」という文章で回答した場合、後のノードは、この文章から「75」という数字だけを正確に抽出することが困難ですが、JSON形式であれば、正確に「75」という数値を取り出すことができます。
また、次のステップである最終レポートの提示の際、インプットの形が崩れると後続の全てのノードが停止するため、厳格な構造を持つJSON形式を強制することで、安定性を確保しています。
つまり、JSON形式での出力は、「AIの推論結果を、人間が読む文章ではなく、機械が正確に処理できるデータ形式に変換する」という目的のために行なっています。
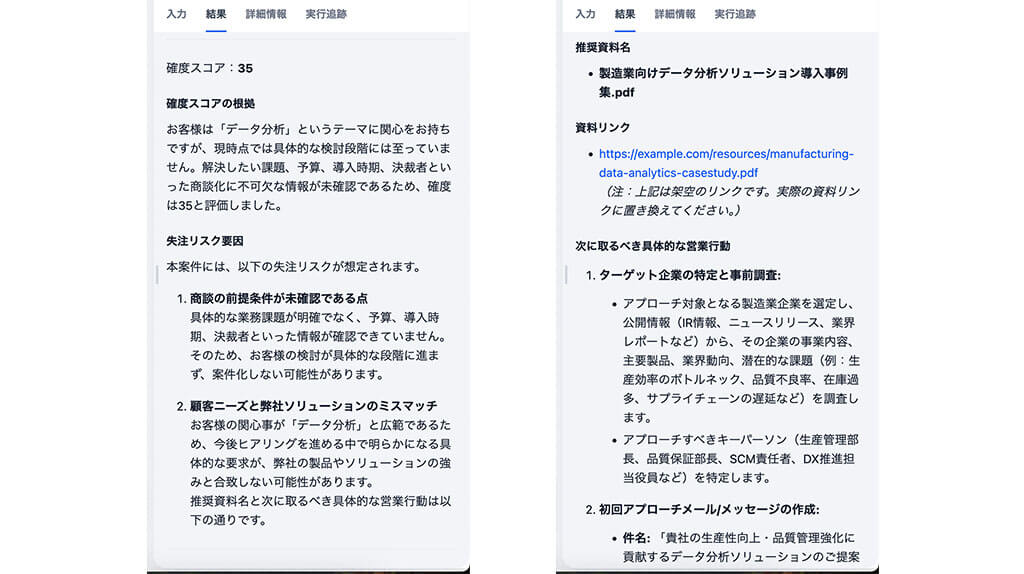
ステップ5:最終レポートの提示
最後のステップでは、生成されたJSON形式のコア情報を、営業担当者がすぐに理解できる自然言語のレポートに変換し、提示させます。
2つのLLMの出力を終了ノードに結合することで、確度とリスクを説明するレポートと、推奨アクションと資料を提示するレポートの2つのレポートを並列で生成してくれます。
まとめ
本記事では、社内に点在するデータをAIで分析し、実務に使えるBIとして活用するための具体的な方法を、Difyワークフローの構築を通じて解説しました。
今回構築したワークフローの成功は、データが点在していても、データを整理してAPI(構造化)とRAG(非構造化)を活用することで、価値ある洞察を生み出せることを示しています。
しかし、今回構築したものは簡易的なモックに過ぎません。
さらには、顧客フィードバックや財務システムからのROIデータなど、新たな構造化・非構造化データソースを知識やツールとして追加したり、iPaaSツールによりリードがCRMに登録された瞬間にDifyワークフローが自動で起動する仕組みを構築したり、競合他社の分析やリソース配分の最適化など、より複雑な推論を組み込んだりすることで、AI分析基盤を拡張していくことが可能です。