



入力データから連続値を予測する回帰モデルは、センサデータや時系列予測などで活用されているが、運用環境が学習環境と異なると、モデルの精度が低下するという課題がある。
通常は、運用環境でのデータを学習に追加する方法が取られるが、これにはコストやデータ収集の困難さが伴う。
こうした中、日本電信電話株式会社(以下、NTT)は、深層学習において、数値予測モデル(回帰モデル)を、学習時と運用時(テスト時)の環境変化に自律的に適応させるAIアルゴリズム「テスト時適応技術」を開発した。
「テスト時適応技術」は、運用環境の教師なしデータのみを用いて回帰モデルが自律的に適応する技術だ。
この技術により、モデルは運用環境のデータを使って精度低下を防ぎ、データ分析やMLOps(AIの運用管理)のコスト削減が可能になる。
今回の研究では、回帰モデルの特徴ベクトルが高次元空間の一部に集中していることを発見し、未知の運用環境の特徴分布を、学習環境の特徴分布に整合させる手法を提案した。
また、特徴空間のほとんどの次元はモデルの出力への寄与が小さいことから、特徴ベクトルが集中している部分空間の分布を優先的に整合させることにより、回帰モデルにおける適応性能が大きく向上することを実験的に示した。
この方法により、運用環境で得られる教師なしデータを使って、学習時の特徴分布と運用時の特徴分布を一致させることが可能だ。
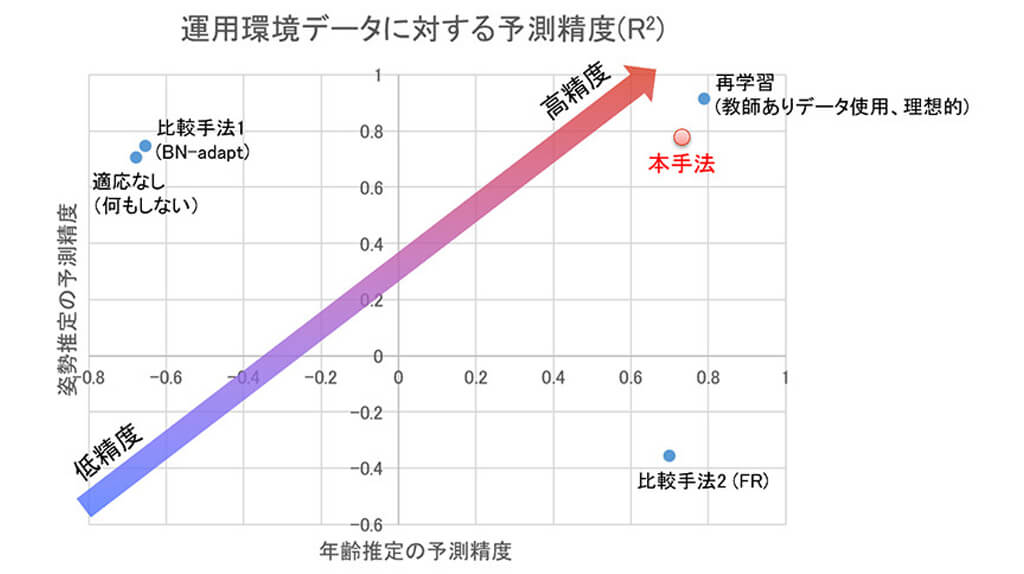
実験では、Webカメラの画像から頭部の姿勢(角度)を推定するタスクと、顔画像から年齢を推定するタスクで予測精度を比較した。
その結果、適応を行わない場合や、分類モデル向けに設計された適応手法を単純に回帰へ適用した手法では、精度が大きく低下したまま回復しなかったり、かえって精度が悪化したりするケースが見受けられた。
一方で、今回の手法は安定して精度向上が実現できており、教師ありデータを用いて再学習した場合に近い性能を達成したケースも見られた。

また、年齢推定の例では、ノイズのない画像に対し適応前のモデルは正解に近い予測値を出力できている。
一方、ノイズの乗った画像に対し、適応前のモデルは不正確な予測値を出力しているが、適応後のモデルは正解に近い出力ができている。

左:学習環境を想定したノイズのない画像:適用前のモデルは正解に近い年齢を予測できている。
右:運用環境を想定したノイズの乗った画像:適応前のモデルの予測は大きく正解から外れているが、同技術による適応後のモデルは正解に近い年齢を予測できている。
これにより、モデル学習時と運用時の環境変化による精度低下を防ぐことができ、MLOpsやデータ分析AIの高度化など、AI技術の研究開発に貢献すると期待されている。
また、マルチモーダル基盤モデルにおける画像や数値データにおける天候変化・センサ劣化など環境変化に対して、回帰タスク以外のタスクにも応用できると考えられている。
なお、今回の成果は、2025年4月24日から28日までシンガポールで開催される深層学習分野における国際会議「International Conference on Learning Representations 2025」において発表される予定だ。