



企業のデジタルトランスフォーメーション(DX)が叫ばれる現代においても、日々の業務に不可欠な書類処理が未だに紙や手入力に依存しているケースも多くあります。
このアナログな業務プロセスが非効率性を生み、業務効率を低下させる大きな原因となっています。
こうした書類処理を自動化するために一役を買うのが、「AI-OCR」という技術です。
本記事では、AI-OCRの基本定義や種類、選定時のチェックポイントに加え、DifyプラットフォームによるAI-OCRシステムの具体的な構築ステップなどを紹介します。
紙ベースの非効率性とAI-OCR活用の必要性
多くの組織では、未だに紙帳ベースの書類処理が根強く残っており、これが企業活動を支えるバックオフィス部門や営業部門の生産性を押し下げています。
総務・経理部門における非効率性の課題
総務部門では、部署からの備品発注書や、業者からの納品書や請求書など、日々、様々な種類の紙帳が集約されます。
これらの内容は、人手で読み取り、在庫管理システムや会計システムへ転記・入力します。
こうした事務処理作業には膨大な時間がかかるほか、大量のデータを手入力する過程で、誤字や転記ミスが発生しやすいという課題もあります。
これが、在庫の過不足や経費処理の遅延、さらには取引先とのトラブルに繋がることもあります。
経理部門における請求書や経費精算の処理も同様で、紙の情報を基幹システムに打ち込むアナログな仕組みが、経理業務全体のボトルネックとなっています。
営業・その他の部門におけるコア業務への集中阻害
営業部門は、売上に直結するビジネス活動に集中すべきですが、間接業務に時間を奪われがちです。
例えば、顧客から受け取る注文書や契約書は、非定型なレイアウトや手書き文字を含むことがあり、これをSFA(営業管理システム)やCRM(顧客管理システム)といったシステムへ登録する作業が大きな作業負担となります。
また、契約情報を迅速にデジタル化できないことにより、商品やサービスの提供開始が遅れ、顧客満足度の低下や機会損失に繋がる可能性もあります。
このように、紙ベースの業務は「人手による入力時間の浪費」「ミスの多発」「コア業務への集中阻害」という複数の課題を抱えており、企業全体の生産性を押し下げています。
これらの課題を解決する一つの手段として、AIを組み込んだAI-OCR(光学的文字認識)技術があります。
AI-OCRは、単に文字を読み取れるだけでなく、ディープラーニングなどの技術を活用して、複雑なフォーマットや認識が難しい手書き文字からも、必要な情報を高精度で抽出する仕組みを持っています。
AI-OCRとは?その定義と基本機能
AI-OCRとは、AIを組み込んだOptical Character Recognition(光学的文字認識)の略称です。
画像データとして取り込んだ手書きや印刷された文字を、AIが解析し、デジタルなテキストデータとして自動で認識・抽出する仕組みのことです。
AI-OCRの中核には、ディープラーニング(深層学習)といった人工知能技術が用いられています。
これにより、複雑な文字の形やレイアウトを、人間のように分析し、判断することが可能となります。
AI-OCRの処理フローと仕組み
AI-OCRは、以下の基本的な仕組みで動作し、紙の情報を価値あるデータに変換します。
① 画像データの取り込み
紙の請求書や発注書をスキャナーや複合機で読み込み、JPEGやPDFなどの画像データとして取り込みます。
② 文字の読み取りと認識
AI-OCRエンジンが、画像内のどこに文字があるかを特定します。
そして、ディープラーニングモデルが、その文字一つ一つを解析し、対応するテキストデータに変換します。
手書き文字や異なるフォントが混在していたとしても、AIが文脈や文字の形状を学習しているため、高い精度で読み取ることができます。
データの整理と構造化
AI-OCRは、単にテキスト化するだけでなく、抽出した文字が何を意味するかを理解します。
例えば、「日付」「金額」「品名」といった項目を識別し、意味のあるデータとして整理します。
この段階で、データはシステムに登録しやすいCSVやJSONなどの形式に変換されます。
自動連携と分析
整理されたデータは、APIを通じてバックオフィスシステムに自動的に送信され、次の業務プロセス(例:在庫数の更新、支払い処理の開始)を起動する機能を果たします。
蓄積された大量のデータは、分析のベースとして活用され、発注傾向やコスト管理の最適化などに役立ちます。
さらに、IoTデバイスのデータと連携すれば、広範な機能を持つシステム構築も視野に入ってきます。
従来のOCRとの違いを比較
AI-OCRを注目を集めたのは、単に文字を認識するだけでなく、従来のOCR(Optical Character Recognition)が抱えていた限界を、ディープラーニングという人工知能の力でブレークスルーした点にあります。
従来のOCRの限界
従来のOCR技術は、optical character recognitionの定義が示すように、光学的情報から文字を認識する仕組みでした。
しかし、その基本は「テンプレートベース」や「ルールベース」であり、活字や定型フォーマットの文字認識には対応できましたが、手書き文字や、傾き、汚れ、かすれなどがある画像、特に品質が落ちやすいFAXで送られた文字は読み取れませんでした。
また、請求書や注文書など、レイアウトやデザインが異なる非定型な書類に対しては、その都度、読み取り範囲や設定を人手で調整する必要があり、非常に作業負荷が高く、比較的導入が難しいという課題がありました。
こうした中登場したAI-OCRは、ディープラーニングを用いた学習能力を持つことで、従来の課題を一掃しました。
AI-OCRが実現した決定的な違い
AI-OCRは、大量のデータから様々な手書き文字のパターンを学習します。その結果、崩れた手書き文字や、枠からはみ出した文字でも、文脈や形状を分析して正確に認識することが可能になりました。
また、レイアウトが異なる取引先ごとの注文書や請求書であっても、AIが自動で「これは合計金額」「これは発注日」といった意味を理解し、必要な項目を特定して抽出します。
これにより、テンプレート設定の作業がほぼ不要となりました。
また、AI-OCRの最大の特徴は、利用するごとに精度が向上していく仕組みです。
AIが間違って認識した箇所をオペレーターが修正すると、その修正履歴をディープラーニングモデルが学習し、次回以降の同様のパターンの認識精度を高めます。
これは、従来のOCRのように人手による再設定やカスタマイズではなく、AI自身が成長し続けることを意味します。
AI-OCRの種類
AI-OCRの導入を検討する際、まず知っておくべきことは、その種類が大きく「汎用型」と「業務特化型」の二つに分けられることです。
自社の作業内容や目的に合わせて、どちらの特徴を持つシステムが最適かを選ぶことが、導入成功の鍵となります。
汎用型AI-OCR
汎用型AI-OCRは、一般的な文字認識機能を持ち、事前に特定の定型フォーマットに限定されず、さまざまな文書タイプに対応できる柔軟性を備えています。
ユーザーが読み取りたい項目を自由に設定し、カスタマイズすることが可能です。
そのため、処理する文書の種類が各種にわたり、少量多品目の書類を扱う企業に適しています。
特定の定型業務だけでなく、会社全体のデジタル化の基本インフラとして活用したい場合に有効です。
業務特化型AI-OCR
一方、業務特化型AI-OCRは、会計処理や建設業、医療など、特定の業界やビジネスプロセスに最適化されているのが特徴です。
請求書、領収書、注文書など、特定の定型文書の読み取り精度や項目抽出率が極めて高く設計されています。
そのため、特定の部門や作業で、大量の定型文書を扱う場合に効率を発揮します。
選定時の重要チェックポイント
自社のニーズに合わせて、汎用型か特化型かを判断した後、具体的な製品を選ぶための検査項目を確認します。
機能性の検査と業務への適応力
AI-OCRの導入時間や作業負荷を削減するため、読み取りたい項目(品名、単価、手書きの署名など)を、利用者が簡単に設定できる機能が備わっているかを確認する必要があります。
また、多種多様な紙帳(請求書、注文書、領収書など)の種類をAIが自動で判断し、適切な処理フローへ振り分けられる機能があるか、FAX画像や手書き文字といった品質の低いデータでの認識精度が十分高いか、認識精度が低い場合に担当者が簡単にデータ修正を行えるインターフェースが用意されているかなどを確認しましょう。
コストとパフォーマンス
AI-OCRのコストは、多くの場合、従量課金ベースとなります。
そのため、月間処理枚数や、読み取りに失敗した場合の課金仕組み、初期設定費用など、全てのコスト構造を明確にチェックします。
そして、AI-OCRが削減する人手による入力時間や、ヒューマンエラーによるコストを定量的に算出し、導入コストと比較して、投資に見合うだけの効果が得られるかを確認します。
導入後のサポートと最適化
導入はゴールではなくスタートです。継続的に利用し、DXを推進するためにはサポート体制が欠かせません。
そのため、トラブル発生時に迅速に対応してくれる時間帯や、技術サポートのレベルを確認します。
また、AIが利用者の修正履歴をディープラーニングで学習し、精度を継続的に向上させる仕組みが用意されているか、Difyのような外部のワークフローツールやIoTデバイスなどの将来的な拡張連携が容易に可能かどうかを確認します。
特に、データ連携や自動化を目的とする場合は、APIの柔軟性が重要になります。
これらのチェックポイントを総合的に評価し、自社の業務フローに最も最適で、かつコストに見合うAI-OCR製品を選定することが、成功の秘訣です。
DifyによるAI-OCRシステムの具体的な構築ステップ
これまで解説したAI-OCRの機能と仕組みを、ノーコード・ローコードプラットフォームであるDifyを活用することで、専門知識がなくとも構築することができます。
本記事では、FAXやスキャンされたPDFで届く非定型な契約書をSFAへ手動で転記する作業を効率化するため、DifyとGemini VLMを活用した簡易的なAI-OCRシステムを構築してみました。
OCR層とLLM処理層の統合(Gemini VLMの役割)
DifyでAI-OCRシステムを構築する場合、Google Cloud Vision APIなどの高精度な外部OCRサービスをDifyのツール機能として組み込むこともできますが、今回は、画像とテキストの両方を同時に理解できる「Gemini VLM」を活用した簡易なシステム構成にしました。
具体的には、テキスト抽出を行うOCR層と、データ分析・整理の役割を担うLLM処理層の両方をGemini VLMが担います。
Gemini VLMにより、通常は必要となる外部OCRツールとの連携やCode実行ノードなどの中間処理を必要とせず、画像認識とテキスト抽出、抽出したテキストの分析・整理を一括で行います。
これにより、ユーザーが契約書の画像をDifyにアップロードすることでLLMノードが起動し、画像ファイルを直接読み取って文字(テキスト)データに変換します。
そして、SYSTEMプロンプトとJSONスキーマに基づき、抽出したテキストを分析・整理し、営業データとして意味のある構造化JSONデータに変換します。

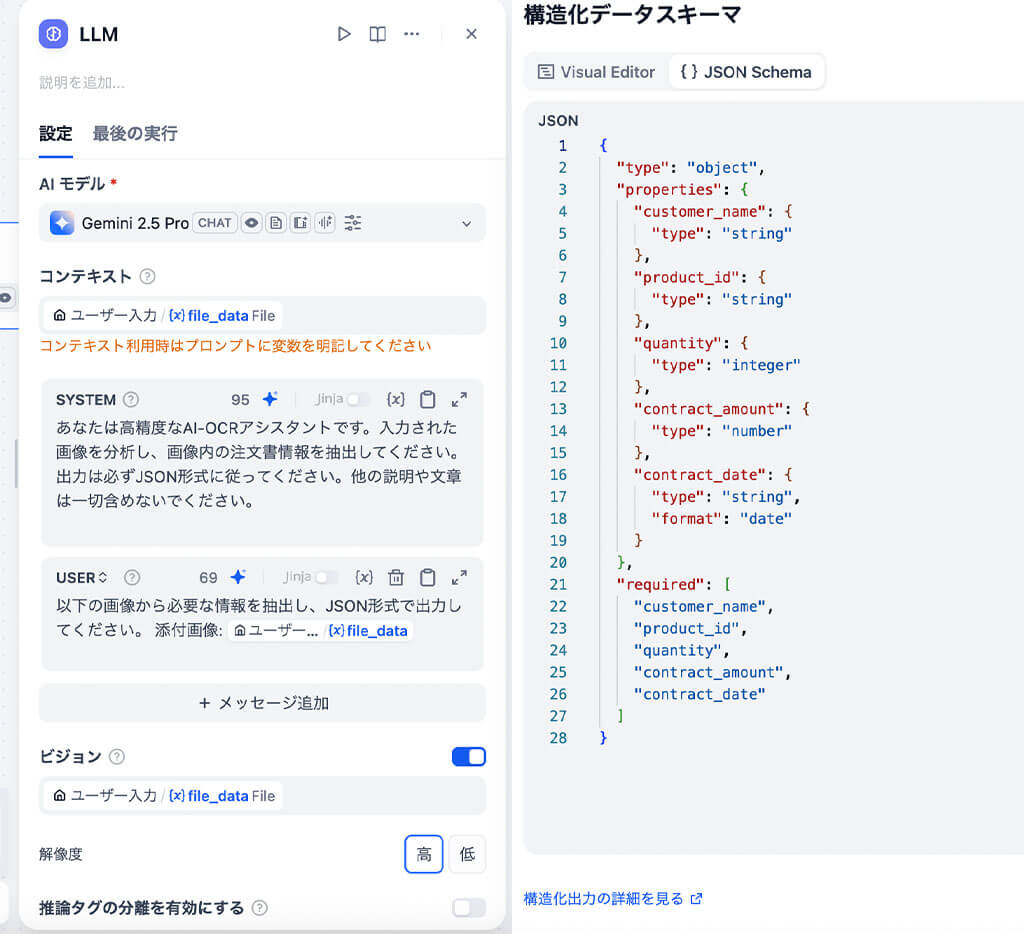
アウトプットの定義
構造化されたJSONデータは、本来はHTTPリクエストノードを通じて、自社のSFAシステムなどへ自動で送信します。
今回はSFAシステムが存在しないため、「出力ノード」 を使用し、架空の購買契約書からテキストを抽出し、構造化されたデータが正しく生成されたことを画面上に表示することでシミュレーションしています。



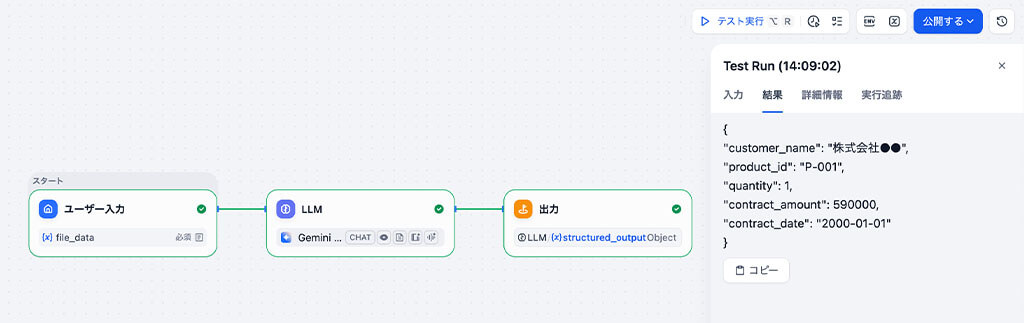
まとめ
このように、Gemini VLMを活用することで、シンプルな構成で画像のテキスト読み取りと、SFAに登録可能な整形済みのJSONデータ生成を行うことができます。
一方、外部OCRサービスを活用する方法では、OCR後の構造化ロジックを自前で組む必要があり、システム構築の複雑性が増しますが、毎月数万枚、数十万枚といった大量のバッチ処理する場合でも非常に速く、安定した処理を実行してくれます。
まずは、簡易的なPoCをほぼコストゼロで実施し効果を実感した後に、処理量を増やすために拡張するなど、段階的なDX推進が可能になります。