



営業担当者は、日々の営業活動の最中、商談の内容や顧客の反応、競合に関する情報などをメモに残しています。
SFA(営業管理システム)などを活用して日々の営業活動を記録していれば、組織のナレッジ(知見)として蓄積することができます。
しかし、一時的な記録としてメモを取り、その後は「個人の中に閉じた情報」になってしまうと、組織全体の成長に活用することはできません。
特に、成績の良い営業担当者のメモは、「成功への洞察」や「失注から得た貴重な教訓」といった経験知になり得ます。
一方、業務を遂行しながら、日々の商談内容のメモを蓄積するの営業担当者にとっては手間であり、データの収集が難しいと感じるケースも多くあります。
そこで本記事では、メモを蓄積することでのメリットにはじまり、AIによる検索・活用を前提とした「営業メモの新しい書き方」と、そのメモを組織全体で活用するための具体的な「ナレッジ蓄積・検索システムの構築方法」を解説します。
メモを蓄積することが組織にもたらすメリット
成績の良い担当者の商談メモを蓄積することは、単なる記録の整理ではなく、営業活動全体を属人化から組織的な学習サイクルへと変革させるための投資だと言えます。
具体的には、ベテラン営業担当者が商談で無意識に行っている「なぜ」「いつ」「どうしたか」というノウハウや、顧客が契約を決断した潜在的な理由を、メモを通じて言語化し、構造化します。
これらの知恵がナレッジベースに蓄積されることで、第三者が再現できる「パターン」となり、経験の浅い担当者でもAIに類似事例を質問することで、過去の成功プロセスに基づいた具体的な行動指針を得ることができます。
ベテラン営業担当者にとっても、自身の成功ロジックを客観視でき、他の担当者が抱える案件の「事実」や「解釈」も参照することができます。
自身が直接関わっていない若手の商談状況についても、構造化されたメモを見ることで、報告を待たずに案件の核心の迅速な理解が可能となります。これにより、指導やフォローアップの精度とスピードが向上します。
また、成功事例の共有以上に重要なのが、失敗(失注)から得られる教訓です。
顧客が競合を選んだ具体的な理由や、商材の致命的な懸念事項が記された失注メモは、製品開発チームやマーケティング戦略チームにとって価値ある情報源となります。
失敗の教訓を組織のデータベースに構造的に集約することで、組織は同じ失敗を繰り返すことを防ぎ、市場のニーズに合わせた製品改善や戦略立案に役立てる学習サイクルを確立できます。
AIがナレッジとして認識するためのメモの条件
個人の経験知を、組織のナレッジとして活用するためには、AIが活用できる「構造化されたデータ資産」として扱う必要があります。
AIが情報を正確に把握し、価値あるナレッジとして抽出するためには、メモ作成時に以下の3つの条件を満たすことが重要です。
1:メタ情報の明確化
メモの本文に入る前に、そのメモが「どのような状況で生まれた情報か」を示すメタ情報(付帯情報)を明確にすることが、AIが情報を分類し、適切な文脈で検索を行うための鍵となります。
以下は、メモに必須となるメタ情報とその重要性、AIを活用した検索における具体的な役割を表した表です。
| メタ情報 | 必須理由 | AI検索時の具体的な役割 |
|---|---|---|
| 日時 | 情報の鮮度と時系列を正確に把握するため。 | 「3ヶ月前の競合の動きを知りたい」など、時間軸に基づく分析を可能にする。 |
| 話者・役職 | 発言が誰によってなされたか(発言の重み)を判断するため。 | 「先方の部長の発言のみを抽出したい」など、権限に基づく戦略的な情報抽出に役立つ。 |
| 顧客名・商材 | どのプロジェクト・顧客に関する情報かを特定し、横断的なナレッジ化を行うため。 | 「A社の案件における共通の懸念点」など、具体的なターゲットに基づく検索を実現する。 |
| フェーズ | 商談のどの段階(初期ヒアリング、価格交渉など)の議論かという文脈を明確にするため。 | 「クロージングフェーズで成功した切り返し」など、営業プロセスに特化した実践的なナレッジを抽出する。 |
特に重要なのが、「どのフェーズで行われた議論か」という情報です。
このフェーズ情報が付いていることで、AIは「初期ヒアリングで最も盛り上がった話題」や「価格交渉で使われた常套句」など、営業プロセスに特化した具体的なナレッジを抽出できるようになります。
2:本文の構造化
メモの本文を単なる会話の羅列にするのではなく、情報を明確な構造に分けて記述することが、AIによる正確な分析を可能にします。
ここで推奨するのが、以下の3要素への分離です。
顧客の発言・要求といった事実
商談で実際に顧客が発言した客観的な情報を記録します。「〜と推測される」「〜かもしれない」といった個人の主観を排除し、正確なニーズ分析の土台とします。
例えば、「納期は最低でも3ヶ月以内にしてほしい。」 「競合B社の製品のUXは評価している。」といった発言がこれにあたります。
営業担当者の推測や真意
次に、事実に基づき、営業担当者が感じた推測や顧客の真意を記録します。
これは、ベテランの洞察や経験が最も反映される部分であり、AIが文脈と背景を理解するために非常に重要です。
例えば、「納期を強く要求したのは、社内の既存システム更改が迫っているためと推測される。」 「B社のUXを評価しつつも、価格交渉を重ねてきたのは、最終的な決定権が価格を重視する層にある可能性がある。」といったメモです。
次の行動
その商談で得た情報に基づき、ナレッジを行動に結びつけるための具体的なステップを記録します。
例えば、「来週火曜日までに、競合B社の価格に対する優位性を具体的に示す資料を作成し、部長にレビューを依頼する。」といったように、具体的なアクションを記述します。
この構造化により、AIは「顧客の客観的なニーズ(事実)」と「営業担当者の深い洞察(解釈)」を明確に区別して学習・検索できるようになるほか、その後のアクションを経て正しい成果につながったかを検証するデータとなります。
3:曖昧な表現の排除
さらに、AIによるナレッジ検索の精度を高めるためには、メモから抽象的で曖昧な表現を排除する必要があります。
「あの競合」や「先方の部長」といった抽象的な表現は、AIにとって情報価値がゼロです。
例えば、「先方の部長は、以前のサービスについて少し不満があったようだ。」というメモであると、誰が何に対して不満があったのかが分かりません。
抽象的なメモでもAIは文脈を捉えようとしますが、推測や解釈のプロセスで齟齬が生まれる可能性があり、その分、情報が不確実になります。
そこで、「山田部長は、旧システムAのレスポンス速度について具体的な不満点(1.5秒の遅延)を指摘した。」というふうに、感情的な表現や定性的な評価を、可能な限り数字や具体的な事象に置き換えることで、AIは定量的な比較や検索を行えるようになります。
AI議事録ツールの活用
このように、メモにメタ情報を付与し、本文を構造化することで、AIのナレッジとして活用することができます。
しかし、商談中にこれを意識しながらメモを取るのは難易度が高く、商談後に営業担当者が手動でこれらの作業を行えば新たな負担となってしまいます。
そこで、AI議事録ツールを活用することで、メモの必須条件を満たしつつ、営業担当者の負担を削減することができます。
本章では、AI議事録ツールがどのような役割を果たすのかを紹介します。
自動メタ情報付与による営業負荷の軽減
商談時の「いつ」「誰が」「どの案件で」といったメタ情報の付与は、AI議事録ツールが自動化できる重要な機能の一つです。
AI議事録ツールは、商談が行われたシステム時刻を自動で正確に記録します。
また、音声から話者分離を行い、「誰が何を話したか」を正確に文字起こしデータに紐付けるツールもあります。
これにより、手動での記録の手間がなくなり、「日時」「話者」のメタ情報が自動で満たされます。
さらに、SFAやCRMといった営業支援システムとさせることで、文字起こしデータを案件名、顧客名、商談フェーズといったSFAのデータに自動で紐づけることができます。
この連携により、メモが個人のファイルに「孤立化」することなく、組織のデータベースに構造的に紐づけられます。
この紐付けを行うことで、後にナレッジ検索(RAG)を行う際に、AIが「どのフェーズの案件か」という文脈を理解するための基盤を構築することができます。
AIによる自動要約と構造化
二つ目は、文字起こし後のデータ整理です。AI議事録ツールは、音声認識された会話の膨大なテキストデータから、AIがナレッジとして最も価値のある部分を抽出し、あらかじめ設定された構造に自動で整形します。
AIが音声認識された会話のテキストデータを受け取ると、以下のプロセスを通じて構造化データを自動で作成します。
まず、AIは会話のトーン、キーワードの出現頻度、質問と回答の関係性といった要素を分析し、「顧客ニーズ」「競合への評価」「懸念事項」など、ナレッジとして最も価値のある重要ポイントを特定します。
次に、特定されたポイントを、AIがあらかじめ学習したパターン認識に基づいて要素ごとに分離し、分類します。
例えば、「事実」「解釈/所感」「次のアクション」を抽出してと事前に定義した場合、顧客の具体的な発言や要求は「事実」として分離され、営業担当者が聞き取った内容から推測される懸念事項や顧客の真意は「解釈/所感」の雛形に当てはめられます。
最後に、会話の中で触れられた「いつまでに」「誰が」といったタスクや期日の言及は、「次のアクション」として抽出・整理されます。
そして、AIが一定のプロンプトとルールに従って構造化することで、全社のメモが統一されたフォーマット(JSONやCSVなどの構造化データ)で出力されます。
この均質で構造化されたデータが、後の「ナレッジ検索」の品質を保証し、高品質なインプットを実現します。
AI議事録ツールを活用することで、メモの蓄積という業務を効率化し、組織のナレッジベース構築を支援します。
関連記事:AI議事録ツールに関してより詳しく知りたい方は、こちらの記事も参考にしてください。
生成AIで無駄な会議をなくす?議事録にAI活用し「生産的な議論と問題解決の場」へと変革するヒントを紹介
Difyでナレッジ蓄積・検索システムを構築構築してみた
前章で紹介したAI議事録ツールには、ナレッジを蓄積して検索までできる製品もありますが、構造をより深く理解するために、今回もノーコード・ローコードプラットフォーム「Dify」で実際にシステムを構築してみました。
今回は、手書きやAI議事録ツールなどで書き出した商談のメモをアップロードすることで、「事実」「解釈」「次の行動」の3つの項目別に要約を行い、その情報を蓄積して検索することができる仕様としました。
このシステムの構築方法は、三段階のプロセスで構成されています。
ステージ1:LLMによる知見の構造化
まずは、非均質な商談のメモから「経験知」を抽出し、情報形式へとデータを変換します。
具体的には、DifyのワークフローのLLMノードでシステムプロンプトを設定することで、入力された長文のメモに対し、以下の構造化処理を実行させます。
【システムプロンプト】
【実行指示】
あなたは入力された内容から、重要な知見を抽出する専門家AIです。
1. 入力されたテキストを分析し、以下の構造を持つ「議事録メモ」を**Markdown形式の日本語テキスト**で出力してください。
2. **メタ情報**、**事実**、**解釈**、**次の行動**の各項目を必ず埋めてください。
3. 余分なコメントや説明は一切加えないでください。
—
### 議事録メモ
* **顧客名:** [議事録から抽出]
* **製品名:** [議事録から抽出]
* **営業フェーズ:** [議事録から抽出]
* **日付:** [議事録から抽出 YYYY-MM-DD]#### 1. 事実 (Fact)
[会議で発言された客観的な事柄を記述]#### 2. 解釈と洞察 (Interpretation & Insights)
[事実に基づき、顧客の真のニーズや懸念、営業上の示唆を記述]#### 3. 次の行動 (Next Action)
[誰が、何を、いつまでに行うべきか、具体的な行動を記述]
—
【構造化された要素の目的と役割】
| 構造化された要素 | 目的と意味 |
|---|---|
| 【メタ情報】 | 顧客名、営業フェーズ、日付といった属性情報を抽出します。これはステージ II でRAGの検索フィルタとして利用され、検索精度を高めます(例:「〇〇社とのクロージングのメモだけを検索」)。 |
| 事実 (Fact) | 会議で発言された客観的な事柄(例:競合製品の具体的な弱点、顧客の予算発言)のみを記録します。 |
| 解釈と洞察 (Interpretation) | 営業担当者がその事実から得た示唆、顧客の真のニーズ、市場の分析といった主観的な知見を分離します。これが組織知の最も価値ある部分となります。 |
| 次の行動 | 次に誰が、何を、いつまでに行うべきかという、行動を促す具体的なタスクを抽出します。 |
なお、出力形式は、言葉や文章の意味をコンピュータが理解できる「数値の列(配列)」に変換したJSON形式であれば、厳格な検索・処理が可能ですが、今回はJSON形式ではエラーが発生してしまったため、LLMが処理を得意とするMarkdown形式での出力としました。
ステージ2:構造化データの資産化
ステージ1でLLMによって均質で構造化されたMarkdown形式のデータが手に入りましたが、このデータはまだ単なるファイルに過ぎません。
そこでステージ2では、ファイルを「組織知」として検索・活用できるデジタル資産に変換していきます。
この資産化を実現するのが、Difyのナレッジベース(データセット)機能です。
これは、LLMが外部知識を参照するための基盤、すなわちRAG(検索拡張生成)のエンジンとなります。
まず、ステージ1で作成された文章をテキストファイルとして保存し、Difyのナレッジベースへアップロードします。
Difyはアップロードされたドキュメントに対し、RAG機能の中核となる処理を自動で実行します。
具体的には、議事録メモ全体を、LLMが一度に処理できるサイズの意味的なブロック(チャンク)に分割します。

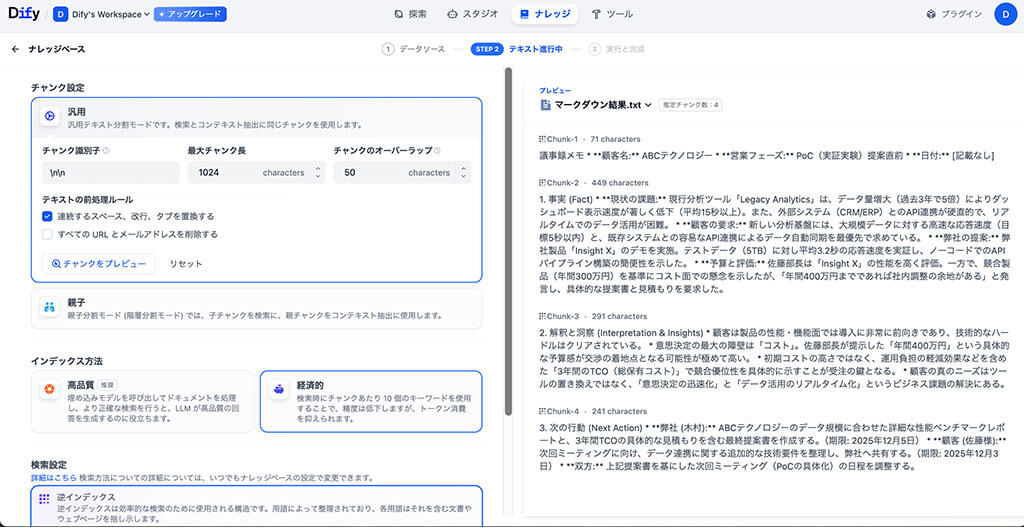
この際、\n\n(ダブル改行)を識別子として設定することで、「事実」や「解釈」といったセクション単位で情報が切り分けられます。
そして、分割された各チャンクは、埋め込みモデルによってベクトル(数値の配列)に変換されます。
このベクトルは、ドキュメントの意味的な位置を示す地図のようなもので、ベクトルインデックスに登録されます。
このベクトルインデックスが完成することで、ユーザーが質問すると、その質問もベクトルに変換され、ベクトルインデックス内の意味的に最も近い「解釈と洞察」のチャンク(ベクトル)が瞬時に特定されます。
こうすることで、全社の営業メモがDify上の単一のナレッジベースに集約され、担当者や部署が異なっても、最新かつ均質な情報にアクセスできる環境が確立されます。
ステージ3:組織知の活用
最後のステージでは、ステージ2で構築されたナレッジ資産を、対話型のインターフェースを通じて活用できるようにします。
この活用フェーズは、Difyのチャットボットアプリケーション機能を用いて構築されます。
これは、ワークフローのような複雑なノード接続を必要とせず、RAG機能を設定として有効化できる、エンドユーザー向けのインターフェースです。
アプリケーションを作成後、その設定画面で先ほど「利用可能」となったナレッジベース(データセット)を接続・有効化します。
これにより、ユーザーがチャットボットに質問を投げかけると、LLMは自動的に接続されたナレッジベースに対して検索(RAG)を実行するため、LLMの回答は「過去の営業メモ」という現実の、根拠あるデータに裏打ちされます。
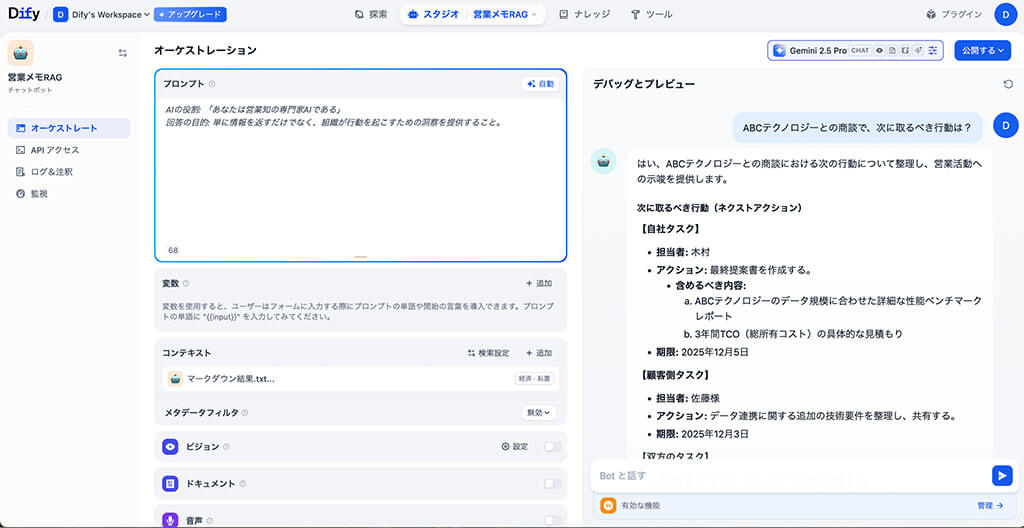
また、チャットボットアプリのシステムプロンプトでは、AIに対して厳格な役割と出力を指示します。
【システムプロンプトの内容】
AIの役割: 「あなたは営業知の専門家AIである」
回答の目的: 単に情報を返すだけでなく、組織が行動を起こすための洞察を提供すること。
この指示により、チャットボットはナレッジベースから得た情報を統合し、実務的な構造を持つ回答を出力します。
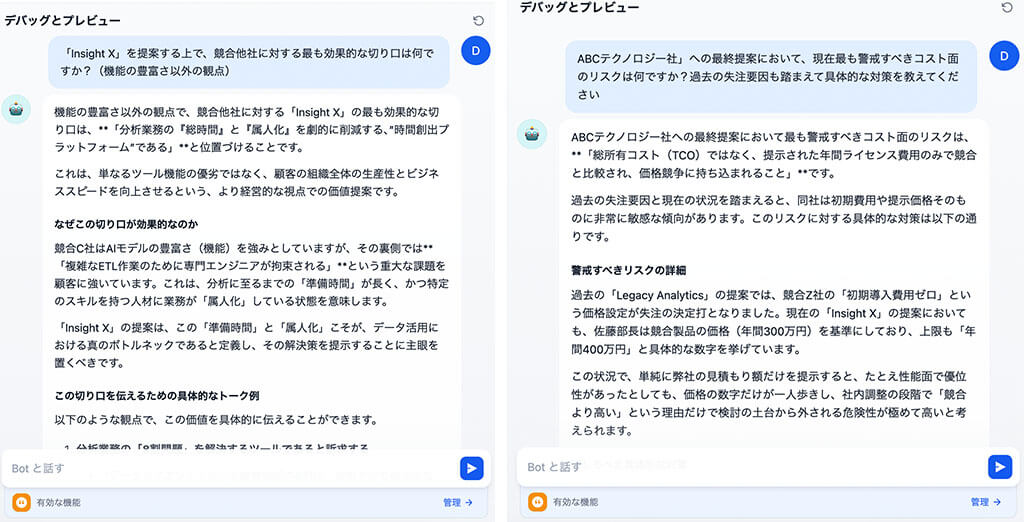
今回は、5つの仮の会議メモをコンテキストとしてアップロードし、「ABCテクノロジー社への最終提案において、現在最も警戒すべきコスト面のリスクは何か?過去の失注要因も踏まえて具体的な対策を教えて。」「nsight Xを提案する上で、競合他社に対する最も効果的な切り口は何?」と質問しました。
すると、必要なメモを検索した上で、事実の提示や具体的なトーク例などを提案してくれました。

まとめ
このように、商談の洞察や教訓のメモ内容をAIが分析できるように整えて蓄積していくことで、進捗状況や成功パターンの把握に加え、フェーズごとの対応策や具体的なトーク例などを提示してくれます。
Difyなどのノーコード・ローコードプラットフォームを活用し、簡易的に構築したシステムでメモを蓄積することでのメリットを感じた上で、さらなる拡張やSFAの導入の検討などを行うことで、現場主導の積極的なメモの蓄積とデータ活用を支援するでしょう。