



企業にとって、新人教育は優先順位の高い重要な項目であるにも関わらず、深刻な労働力不足により、満足に行き届いていないケースも多いのではないでしょうか。
そこで注目されているのが、AIの活用です。
以前の記事では、営業のロールプレイングをAIで実践できる方法を紹介しました。
この方法は、新人が自分自身でスキルを向上させることを主な目的としています。
今回はさらに踏み込み、新人が学習している過程を蓄積することで、マネージャー層が適切なアドバイスを行えることを目的としたシステムの構築方法を紹介します。
新入社員教育の課題
前回の記事で紹介したAIロープレは、AIを相手に反復練習を行うことで、商談の基本的な「型」を習得するスピードを向上させることができます。
しかし、実際の現場では、「マニュアルにはこう書いてあるけれど、このケースはどう判断すべきか?」「先輩は忙しそうだし、こんな初歩的なことを聞いて手を止めてもいいのだろうか……」といった、マニュアルにない例外と聞くに聞けない社内の空気の狭間で、新人は「日々の孤独」を感じ始めます。
この孤独感の蓄積こそが、配属先による教育格差や、早期離職の引き金となるリスクを秘めています。
一方で、教える側のマネージャー層も、「自身のプレイヤー業務」と「新人の育成」を同時に進行しなくてならず、なかなか教育に手が回らない。
これが、現代のOJT現場で起きている現実なのではないでしょうか。
そこで今回、人間の指導を代替するのではなく、教育を「補完」する「対話型AIメンター」を構築していきます。
「対話型AIメンター」3つの定義
本記事で提案する「対話型AIメンター」は、単なるチャットボットではありません。
以下の3つの役割を1つのインターフェースで統合した、新人のための「専属パートナー」をイメージしています。
1.知識:膨大なマニュアルを検索する
一つ目は、新人の問いに対して「社内の正解」を数秒で提示するコンシェルジュの役割を果たします。
社内に散在する製品仕様書、FAQ、過去の商談事例などを知識として統合し、製品の商品仕様や価格、競合との差など、知りたい情報に対して「あの資料のどこに書いてあったっけ?」と探す時間をゼロにし、新人の自己解決能力を支援します。
これにより、新人が「資料を探す」「先輩の空き時間を待つ」といった非生産的な時間をなくすとともに、マネージャー側も自身のコア業務を中断されることなく、より高度な判断を要する指導に専念できるよう支援します。
2.スキル:顧客の反論に即座に対応する「AIロープレ」
次は、新人がAIに質問することで得た知識を「使える形」にする必要があります。そこで今回も、AIロープレの役割を担ってもらいます。
AIが具体的な顧客ペルソナになりきり、反論処理や提案の壁打ち相手を務めます。対話後には即座に定量的なスコアリングとフィードバックを提示します。
人間相手では躊躇してしまうような「初歩的なミス」や「不慣れな提案」も、AI相手なら何度でもノーリスクで試行できます。
この「安全な失敗」の積み重ねが、本番の商談における自信へとつながります。
また、指導者の主観に左右されない一貫した評価軸でフィードバックを行うため、配属先や指導担当によって新人のスキルにバラつきが出る「教育格差」を防止します。
3.可視化:スプレッドシートへの経過の蓄積
新人が行った質問やロープレの対話ログは、マネージャーが確認できる状態にすることで、適切な対処を行えるように支援します。
今回は、スプレッドシートにログを蓄積することで、ブラックボックス化しがちな「新人の習熟度と精神状態」を可視化します。
評価者ではないAI相手だからこそ吐露される「実はここが理解できていない」「この作業に不安がある」といった本音のログを蓄積することができ、マネージャーは表面化する前の実質的な課題を把握できます。
また、スプレッドシートに蓄積された「質問トピック」や「壁打ち回数」を分析することで、組織全体の教育課題が浮き彫りになります。
例えば、「全社員が特定の製品仕様で何度も壁打ちしている」ことが判明すれば、それは個人の能力不足ではなく、マニュアルの不備や全体研修の不足であると判断し、ピンポイントで対策を打つことが可能になります。
さらに、「どのタイミングで、どのような内容に悩んでいるか」を時系列で追えるため、マネージャーは「何に悩んでいるのかを聞き出す」手間を省き、最初から解決策を提示する形で介入できます。
つまり、つまずきが深刻化し、離職リスクが高まる前に予防的なコーチングを行うための「アラート」として機能します。
このように、「情報の整理」や「基本知識の定着」といった定型的な教育はAIに任せ、そこから得られたデータを元に、人間であるマネージャーが、より高度で感情的なケアに集中できる環境を構築することが重要です。
「対話型AIメンター」を形にするDify構築術
次に、実際にノーコードAIプラットフォーム「Dify」を活用し、「対話型AIメンター」を構築していきます。
今回のシステムは、ユーザーの入力を受けてからスプレッドシートに記録するまで、以下の5つのプロセスをワークフローとして繋いでいます。


- 事前準備:スプレッドシートを作成してデータの受け皿を作る
- 開始ノード:ユーザー名や学習の難易度を受け取る。
- 知識取得(RAG):製品マニュアルから必要な情報を検索する。
- LLMノード:検索結果に基づき、メンターまたは顧客として回答を生成する。
- パラメータ抽出:AIの回答から「スコア」や「要約」をデータとして切り出す。
- HTTPリクエスト:抽出したデータを、GAS(Google Apps Script)経由でスプレッドシートに送信する。
1.事前準備:ログを蓄積する「器」を整える
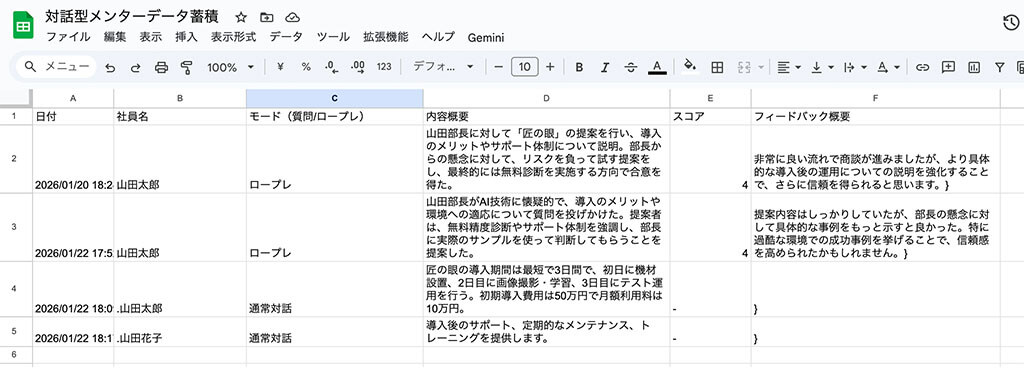
まずは、AIが抽出したデータを確実に受け止めるためのスプレッドシートを準備します。
ここでの項目名は、後にDifyの「パラメータ抽出」で定義する名前と一致させておくことで、管理がスムーズになります。
【スプレッドシートの設定例】
| 日付 | 社員名 | モード | 内容概要 | スコア | フィードバック概要 |
|---|---|---|---|---|---|
| 2026/01/22 | 山田 太郎 | ロープレ | 製品の価格交渉 | 4 | 導入メリットの説明は完璧。クロージングがやや弱い。 |
| 2026/01/22 | 佐藤 花子 | 質問回答 | セキュリティ要件の確認 | – | ISMSの定義について正しく理解できた。 |
そして、Difyからの信号を受け取ってシートに書き込むためのGAS(Google Apps Script)を記述します。


上図のようにスクリプトを用意することで、Difyで構築したAIメンターとスプレッドシートを連携させることができます。
スプレッドシートとGASの準備ができたら、いよいよDify本体の設定に入ります。
2.開始ノードの設定
まず最初に行うのが、対話の入り口となる「開始ノード」のカスタマイズです。
開始ノードは、ユーザーがAIメンターと対話を始める際に「どのような情報をあらかじめ渡すか」を定義する場所です。
ここで設定した変数は、後のLLMの回答や、最終的なスプレッドシートへの記録に使用されます。
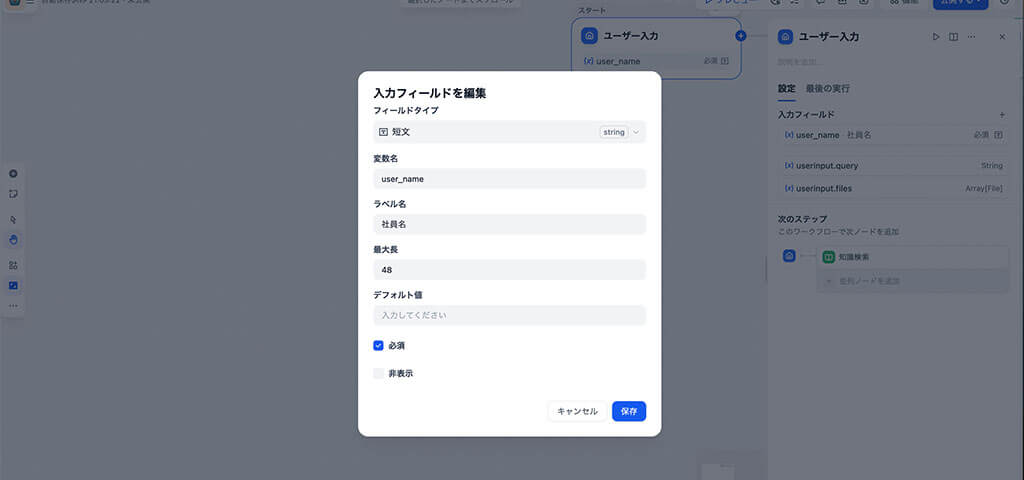
まずは、開始ノードをクリックし、右側の設定パネルから以下の変数を追加します。
user_name(テキスト)
役割: 利用する社員の名前を取得します。
目的: スプレッドシートに誰が利用したかを記録することができます。

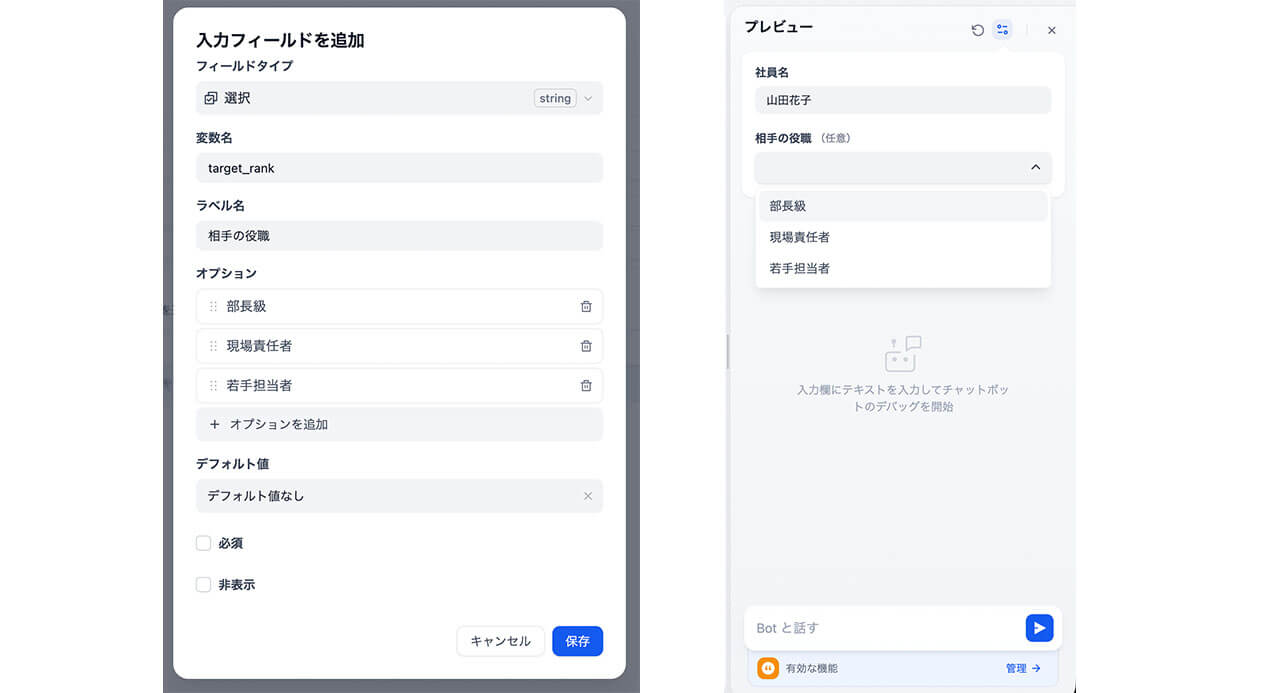
また、「難易度」や「モード」の選択肢を追加する場合も、開始ノードで設定します。
例えば、「練習したい相手の属性」を「選択(Select)」形式で追加します。
これにより、「部長」「現場責任者」「若手担当者」といった様々な立場の顧客との商談を練習することができるようになります。

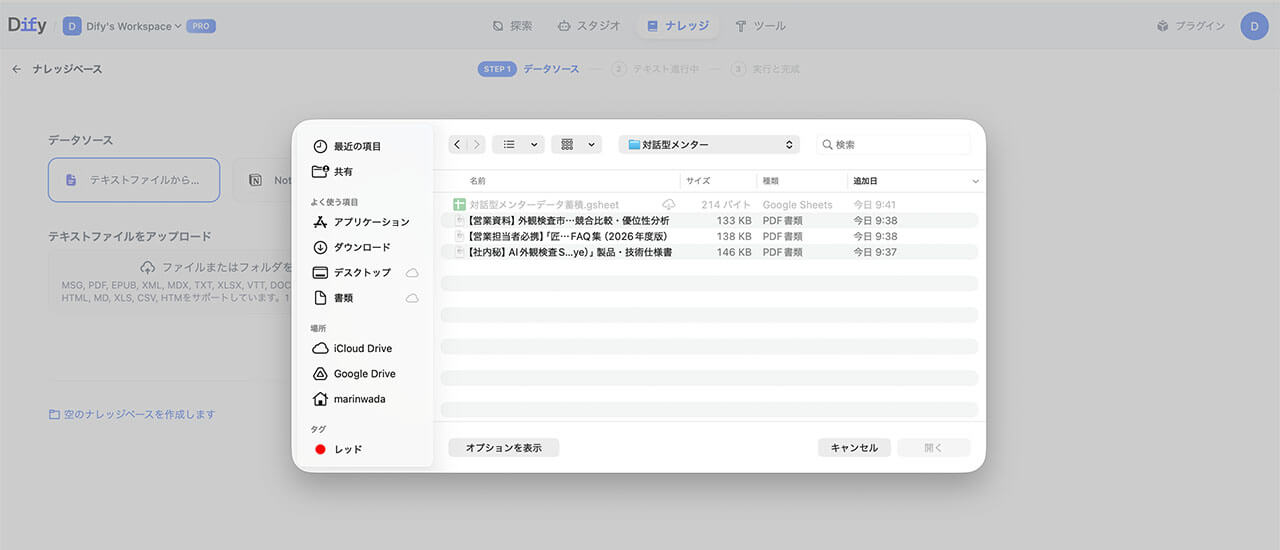
3.知識取得(RAG)ノードの設定
知識取得(RAG)ノードの役割は、膨大な社内資料の中から、ユーザーの質問に対して自社のマニュアルに基づいた答えの断片を瞬時に探し出すことです。
まず、あらかじめDifyの「ナレッジ」メニューで、製品の仕様書やFAQ、競合比較表などをアップロードしておき、このデータをRAGノードに紐付けます。

この知識検索の変数を、次の「LLMノード」の指示文に埋め込むことで、AIはアップロードされた情報の内容を踏まえた回答ができるようになります。
4.LLMノードの設定
次は、開始ノードで受け取った「ユーザーの意図」と、RAGで取得した「社内知識」を掛け合わせ、最適な回答を生成してもらうためにLLMノードの設定を行います。
まず、コンテキストに知識検索ノードの結果を選択し、指示文(システムプロンプト)でRAGから取得した情報を参照するように設定します。
そして、一つのノード内で「教育者(メンター)」と「ロープレ相手(顧客)」を演じ分けさせるために、以下のような指示を書き込みます。
【プロンプトの構成例】
あなたは製造業向けSaaS「匠の眼」の熟練OJT担当者です。
開始ノードの {{#user_name#}} さんに対して指導を行います。【動作ルール】
1. 質問されたら{{#context#}}の内容に基づき、専門用語を避けて回答してください。{{#context#}}以外の内容は書かず、わからない場合はわからないと書いてください。2. 「ロープレ」を依頼されたら、ユーザーが選択した相手の役職に合わせ、以下のスタンスを徹底してください。
– 「部長級」が選択された場合:- 視点:経営・全社最適。コスト対効果(ROI)や「いつまでに投資回収できるか」を厳しく問う。
– 口調:重みのある言葉遣い。「現場が混乱しないか」「会社全体として何が変わるのか」といった大局的な質問を好む。– 「現場責任者」が選択された場合: – 視点:運用効率・実現性。「現場の作業員が使いこなせるか」「既存の設備と干渉しないか」といった実務的な懸念をぶつける。
– 口調:具体的で現実的。技術的な裏付けや、導入後のサポート体制を細かく確認する。– 「若手担当者」が選択された場合:- 視点:機能・使い勝手。UIの分かりやすさや、自分の業務がどれだけ楽になるかに興味を持つ。
– 口調:丁寧だが、上司への説明のしやすさを気にする。「部長を説得できる資料はあるか」といった相談を持ちかけることもある。3. ロープレ中は、あなたは「顧客」として振る舞い、ユーザーの提案に対して厳しい質問や反論(コスト、精度、現場の手間など)を投げてください。
4. ロープレまたは対話で「終了」というコメントが出たら、そこまでの内容をひとまとまりとして、以下のJSON形式でデータを出力し、最後に「[LOG_TRIGGER]」と付けてください。
– mode: 「質問回答」または「ロープレ」
– summary: 会話の要約
– score: 5点満点の採点
– feedback: 改善アドバイス
質問をされたら知識検索ノードのナレッジを元に回答し、「ロープレ」を依頼されたらユーザーが選択した相手の役職に合わせてロープレを実施するという内容を書くことで、必要の応じた役割を果たしてくれます。
5.「パラメータ抽出」ノードの設定
LLMノードで設定したプロンプトでは、「JSON形式でデータを出力」という指定をしています。これは、スプレッドシートの「点数」や「要約」といった項目に振り分けるためです。
しかし、まれに一つの長い文章(非構造化データ)として出力されてしまうことがありました。
そこで「パラメータ抽出」ノードにより、LLMが生成した長い会話文の中から「スコア」「要約」「改善点」などの特定の情報だけを「構造化データ(変数)」として抜き出します。
これにより、スプレッドシートの各セルにぴったりの情報を流し込めるようになります。
以下のように、AIに抜き出してほしい情報を設定します。ここでの項目名は、スプレッドシートの列と対応させるのがコツです。
| 変数名 | データ型 | 抽出内容の指示(Description) |
|---|---|---|
mode |
String | 現在の会話が「質問回答」か「ロープレ」かを判別して出力してください。 |
summary |
String | ユーザーとAIのやり取りの内容を、30文字程度で簡潔に要約してください。 |
score |
Number | ロープレの場合、新人の対応を1〜5の5段階で採点してください(質問回答時は0)。 |
feedback |
String | 新人が次に改善すべきポイントや、褒めるべき点を1つだけ具体的に抽出してください。 |
6.HTTPリクエストによる自動記録
最後に、抽出されたデータを外部へ飛ばす仕組みを構築します。
HTTPリクエストノードは、Dify内部で処理されたデータを外部のシステム(今回はGoogle Apps Script経由のスプレッドシート)へ書き出すための「送信ボタン」の役割を果たします。
メソッドは「POST」を選択し、事前にGASで「デプロイ」した際に発行されたウェブアプリのURLを貼り付けます。
そして、パラメータ抽出ノードで切り出した変数を、GASが受け取れる「JSON形式」にまとめます。
設定画面の「Body」セクションを「JSON」に切り替え、以下のように記述します。
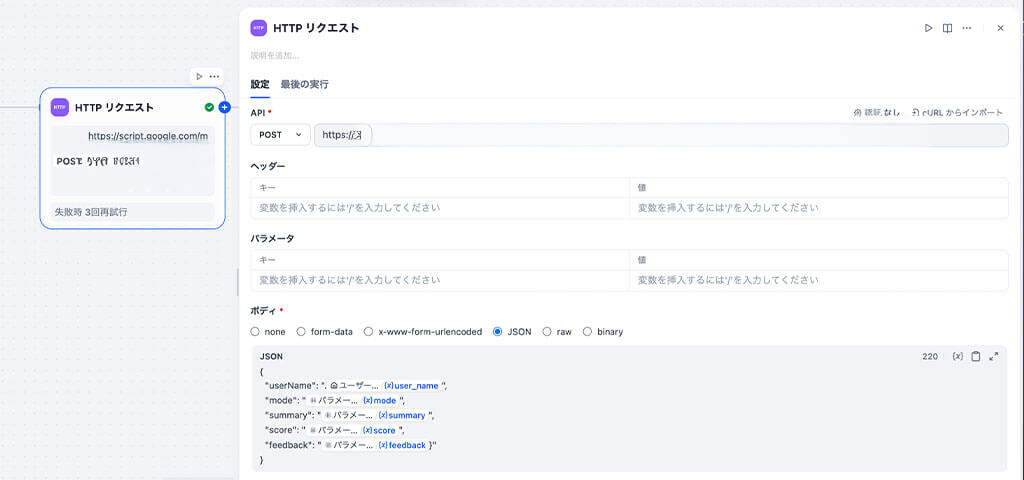
これにより、AIとの会話が終わるたびに、スプレッドシートに「新人の成長ログ」が1行ずつ自動で書き込まれていく仕組みを構築することができます。

「対話型AIメンター」を設計する際のポイント
最後に、「対話型AIメンター」を設計する上でのポイントを紹介します。
指導方針の言語化(プロンプト設計)
AIメンターの振る舞いを決定づけるのがLLMノードにおける「システムプロンプト」です。
単一のキャラクターを固定する手法から、学習者のニーズに合わせて柔軟に変化させる手法まで、目的や教育フェーズに応じた複数の設計アプローチが存在します。
① 特定キャラクター固定型(高度なシミュレーション)
今回は、相手の役職として三つのタイプの顧客を選択できるようにしましが、具体的な属性や性格、課題を持つ特定のキャラクターをAIに深く設定する手法もあります。
例えば、「年齢」「役職」「性格(頑固、論理的など)」「抱えている悩み」「AIアレルギーがある」など、背景情報まで詳細に書き込みます。
学習者は「実在しそうな手強い相手」と対峙することで、マニュアル通りの回答が通用しない現場のリアルを体験できます。
この手法は、攻略すべきターゲットが明確で、かつ商談の難易度が高い業種や企業において、高い効果を発揮することが期待できます。
特定のキャラクターを設定することで、エースはどうやって攻略したかというベテランの暗黙知をAIに反映できるほか、このキャラクターに合格をもらえれば、実際の現場に出ても大丈夫という、社内の基準として機能させることが可能になります。
② ユーザー選択・可変型(パーソナライズ学習)
今回筆者が構築した、学習者がその日の学習目的や自身の習熟度に合わせて、AIの役割や難易度を選択できるようにする設計です。
開始ノードで選択された変数に基づき、AIのトーンや反論の鋭さを動的に変化させます。
この手法は、「扱う商材が多岐にわたる」あるいは「顧客の属性が幅広く、画一的な対応では通用しない」環境に適しています。
また、性別、年齢、年収、ライフスタイルがバラバラな個人顧客を相手にする業種や、新人の習熟度の差が大きい場合にも適しています。
構造化されたナレッジの投入
AIメンターの指導方針を綿密に設計したとしても、参照するデータ(ナレッジ)が乱雑であれば、回答の精度は低下してしまいます。
そのため、「AIが検索しやすい形に、人間が情報をあらかじめ仕分けしておく」ことが重要です。
一般的な製品マニュアルや社内規定(PDF)は、人間が通読することを前提に作られています。
しかし、AIのRAG(検索拡張生成)は、情報を「断片(チャンク)」として検索します。
ページを跨いだ表や、文脈が複雑な文章をそのまま読み込ませると、AIは「情報の繋がり」を見失い、誤った回答や「分かりません」という回答を出す原因になります。
そこで、AIが最も効率的に情報を引き出せる整理のコツを3つのカテゴリで紹介します。
1.スペック・事実:数値と条件の明確化
製品の仕様、価格、動作環境などは、曖昧さを排除したリスト形式で整理します。
例えば、「対応OSはWindows 10以降です」と書くよりも、「項目:対応OS / 内容:Windows 10, 11 / 備考:Macは非対応」のように、項目と内容を1対1で結びつけることで、AIの検索精度が向上します。
2.反論処理・FAQ:「問い」と「答え」のセット化
営業現場で最も必要とされる「顧客の懸念に対する切り返し」は、一問一答の形式でナレッジ化します。
例えば、 「価格が高いと言われたら、ROI(投資対効果)を説明する」という抽象的な指示ではなく、「質問(高い):導入費用がネックだ / 回答:1年で人件費削減により回収できる試算を提示し、無料診断を提案する」という具体的なスクリプトを登録します。
3.事例・成功パターン:「状況」と「解決策」の紐付け
「過去にどのような課題をどう解決したか」という定性的な情報は、タグ付けして整理します。
例えば、「業界:金属加工 / 課題:ベテランの引退 / 解決策:匠の眼による検品自動化」といった属性情報を文頭に置くことで、新人が「金属加工のお客様の事例を教えて」と聞いた際に、AIが迷わず最適な事例を引用できるようになります。
また、この「構造化されたナレッジ」の構築は、一度作って終わりにするのではなく、「価格が変わった」「新機能が追加された」といった際も、構造化されたリストの一部を書き換えてアップロードし直すことが重要です。
その際、別々のアプリケーション同士をプログラミングなしで繋ぐiPaaS(Makeなど)を活用し、「Googleドライブの特定フォルダにファイルを置くだけで、Difyの知識が自動更新される仕組み」を構築します。

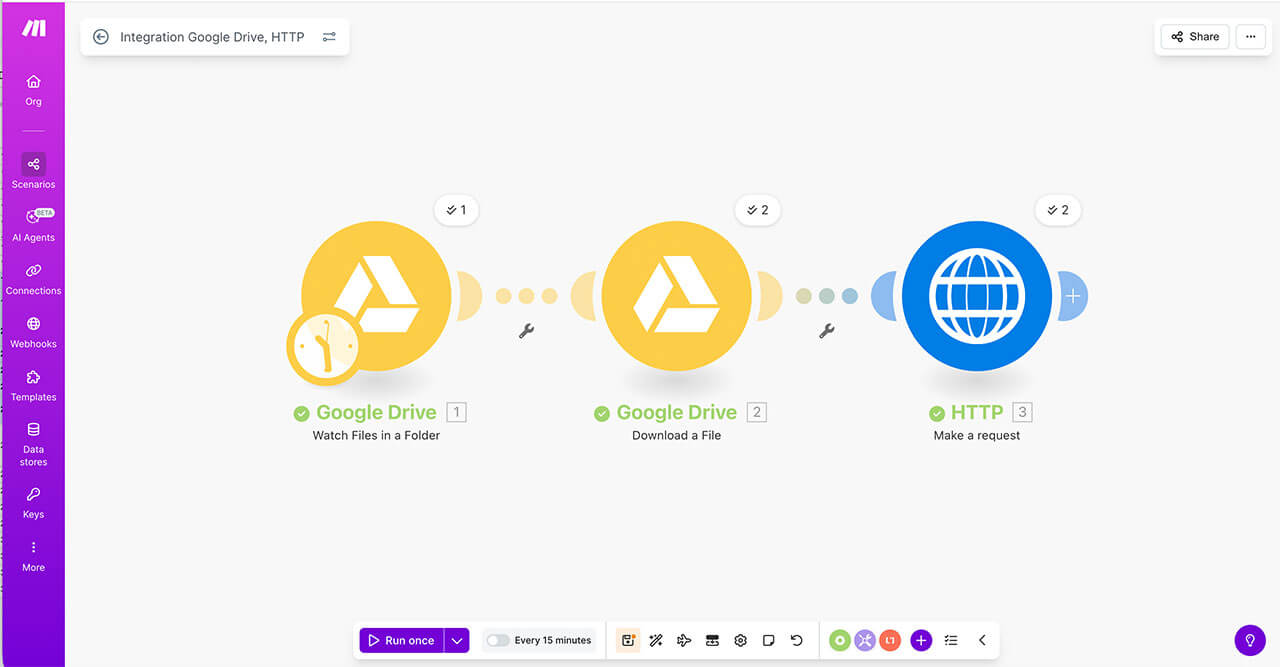
これにより、担当者は変更された内容が記述されたPDFを共有フォルダに保存するだけで、iPaaSが自動で追加を検知し、API経由でDifyのナレッジへ反映してくれます。なお、iPaaSは「1時間ごと」など、システムが共有フォルダをチェックする時間をあらかじめ設定することができます。
このように、情報を整理するプロセス自体が、自社の営業ノウハウや製品の強みを再定義することに繋がり、人間にとっても使いやすい「ナレッジベース」となります。
「スコアリング」の多角化:評価の解像度を高める
今回の構築例ではシンプルな「5点満点」の採点としましたが、もし自社独自の評価指標やチェックリストがある場合は、LLMノードの「指示(プロンプト)」に評価基準を具体的に書き込むことで、評価の解像度を高めることができます。
例えば、自社の営業スタイルに合わせて「傾聴力」「提案のロジック」「クロージングの有無」といった独自の評価項目がある場合、プロンプト内で以下のように定義します。
【プロンプトへの指示例】
以下の自社評価基準に基づき、それぞれの項目を5段階で評価してください。
[評価項目A]:マニュアルのルールを逸脱していないか
[評価項目B]:顧客の課題を深く掘り起こせているか
[評価項目C]:……(以下、自社の基準を列挙)」
このようにLLMノードで多角的な採点を行わせるよう指示した上で、「パラメータ抽出」ノードを使ってそれらの数値を個別のデータとして切り出します。
これをスプレッドシートに蓄積することで、「知識の正確性は高いが、顧客への共感度が低い」といった個人のスキルバランスが可視化されます。
これにより、評価の解像度を高め、マネージャーの介入を最適化することができるでしょう。
例えば、蓄積されたデータに基づき、「Aさんは提案のロジックは完璧だから、次は[評価項目B]の深掘りを強化しよう」といった、個人の特性に合わせた具体的なコーチングが可能になります。
まとめ
このようなシステムを構築することで、マネージャーは新人に対して「最近どう?」という抽象的な問いかけではなく、「昨日のロープレ、価格交渉で苦戦してたみたいだね。一緒に作戦を練ろうか」という、極めて解像度の高いフォローが可能になります。
また、「新人の8割が、競合比較のフェーズでスコアが低い」「特定の製品仕様について何度も繰り返し質問している」といった全体の傾向を可視化することもできます。
データに基づき、研修プログラムや資料をピンポイントで改善することで、教育全体の生産性を底上げし、標準化の促進が期待できます。