



給与計算担当者は、毎月その計算結果が「本当に正しいか」を検証する業務が発生します。
給与計算ソフトは、設定された数式通りに計算を行う点では完璧です。
しかし、勤怠データの入力ミス、社会保険料の改定漏れ、あるいは手当の支給要件の勘違いといった「入り口」のミスや「判断」の誤りまでを自動で防いでくれるわけではありません。
これらを確認する作業は、時間と集中力を要する上に、非常に属人的な「ブラックボックス」になりがちです。
また、万が一ミスがあれば、従業員との信頼関係を損なうだけでなく、法的リスクにもつながりかねません。
そこで本記事では、ノーコード自動化ツール「n8n」を活用し、「システムが計算の不整合を自動で炙り出し、人間が最終判断する」という、給与監査ワークフローを提案します。
給与監査自動化システムにおける4つのフェーズ
給与計算に監査は、単に計算式が合っているかを確認するだけでなく、人事発令との整合性、変動の妥当性、そして最新の法令への適応といった多層的な検証にあります。
本章では、この検証を実行するシステムを構築するためのフェーズを4つに定義しました。
1.データ集約と正規化(インプット・フェーズ)
まず、Google Driveなどのクラウドストレージを監視し、複数のシステムから出力される給与関連データを自動収集します。
収集対象は、勤怠システムからの「総労働時間」、人事システムからの「基本給・家族構成」、現場提出の「経費・インセンティブExcel」などです。
これらのデータは形式がバラバラであることが多いため、システムが計算可能な状態に項目名を統一し、VLOOKUP関数などを手動で組む手間とミスを排除します。
データはExcelのような装飾や計算式を含まない「CSV形式」をあえて採用することで、システムが数値を純粋かつ正確に読み取れる状態(正規化)を担保します。これにより、手動でのデータ整形に伴うミスを排除します。
2.厳密な照合ロジックの実行(ロジック・フェーズ)
二つ目は、ロジックフェーズです。
このフェーズでは、インプットフェーズで集約したデータに対し、多層的な「監査ルール」を一斉に適用します。
例えば、人事側の「最新等級・基本給」と給与側のデータを直接突き合わせ「等級は上がっているのに基本給が据え置き」といった乖離をあぶり出したり、勤怠実績の「分単位の残業時間」に割増率が正しく適用されているかを再計算したりします。
また、前月の支給実績と比較し、「20%以上の増減」などの極端な変動がないかをスキャンするといったことや、経費精算やインセンティブのデータが重複していないか、入力桁数の間違いがないかといった「ヒューマンエラー」を自動で炙り出す場合も、このフェーズで設定します。
他にも、社会保険料率の改定や、年齢に応じた介護保険料の徴収開始タイミングなど、法改正に伴う「公的な計算基準」が正しく反映されているかをチェックし、適法性を担保することも可能です。
3. 例外リストの自動生成(アウトプット・フェーズ)
全ての照合が終わると、システムは「正常」と判断した膨大なデータをスキップし、確認が必要な項目だけを抽出した「例外リスト」を生成します。
その際、Google Sheetsなどを用い、不整合が見つかった従業員の「従業員番号」「氏名」「エラー理由(例:残業代の計算不一致、社保改定漏れの疑い)」を自動で追記させます。
これにより担当者は、システムが提示した「疑わしいデータ」だけを確認するだけで済み、目視チェックによる精神的・時間的負荷から解放されます。
4. 承認プロセスと監査ログの記録(ガバナンス・フェーズ)
担当者が異常値を精査し、修正または「問題なし」と判断したアクションは、すべてシステム上にログとして保存されます。
これにより、「誰が、いつ、どの数値を承認したか」がデジタル証跡として残るため、将来的な会計監査や労働基準監督署の調査に対しても、高い透明性を持った給与支払い体制を証明することができます。
n8nを活用したシステム構築方法
では実際に、システムの具体的な構築ステップを解説します。
今回は、「n8n」というワークフロー自動化ツールを活用し、Googleドライブ上の給与・勤怠データを自動照合することで、不整合(異常値)を抽出するというシステムを構築します。
「n8n」は、異なるアプリやサービス同士を「ノード」と呼ばれるアイコンで繋ぎ合わせ、業務を自動化するツールです。
AIノードを組み込むことで、AIエージェントとしての運用も可能ですが、今回は「設定した計算式やルールに則って正確にデータを制御・統合する」ツールとして活用しています。
ワークフローの全体像
まず、具体的な設定に入る前に、今回構築したワークフローの全体的な流れを整理します。
このシステムは、大きく分けて「検知・取得」「解析・正規化」「照合・仕分け」「出力」の4つのプロセスで構成されています。
このプロセスに対し、「Google ドライブトリガー(検知)」「ファイルをダウンロード(取得)」「ファイルから抽出(解析)」「もし(照合・仕分け)」「シートに行を追加する(出力)」というノードで繋ぎ合わせています。

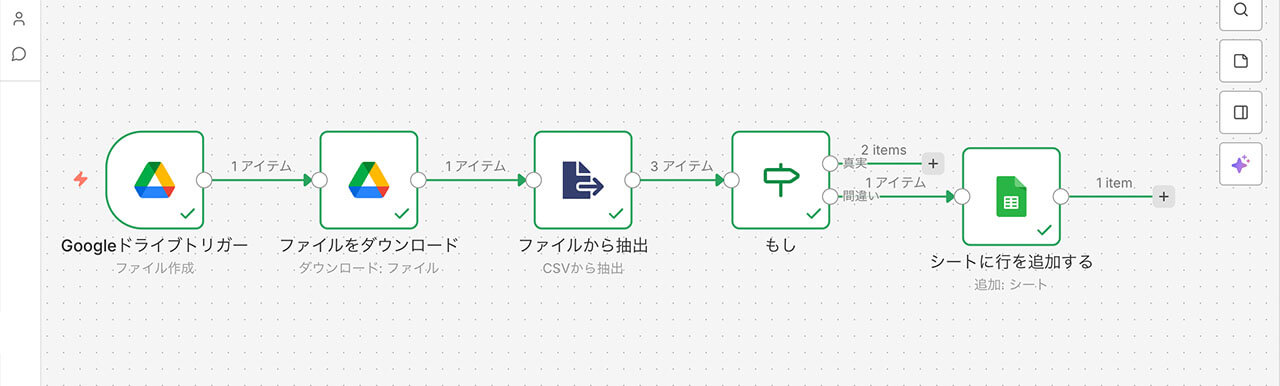
このように、左から右へとデータが流れる過程で、「人間が1件ずつ照合する」という作業を肩代わりする仕組みになっています。
それでは、各ステップの詳細な設定を見ていきましょう。
検知・取得(インプット)
まず、クラウドストレージ(今回はGoogle Drive)へのファイル保存をトリガーに、後続の処理が動き出す「プッシュ型」の仕組みを構築します。
一つ目のノードは「Google Drive Triggerノード」で、指定したフォルダに新しいファイル(CSV)がアップロードされたことを検知し、ワークフローを起動させます。
これにより、担当者が最新の給与・勤怠データを指定のフォルダにアップロードすることで、ツールを操作することなく自動でチェックが始まる体制が整います。

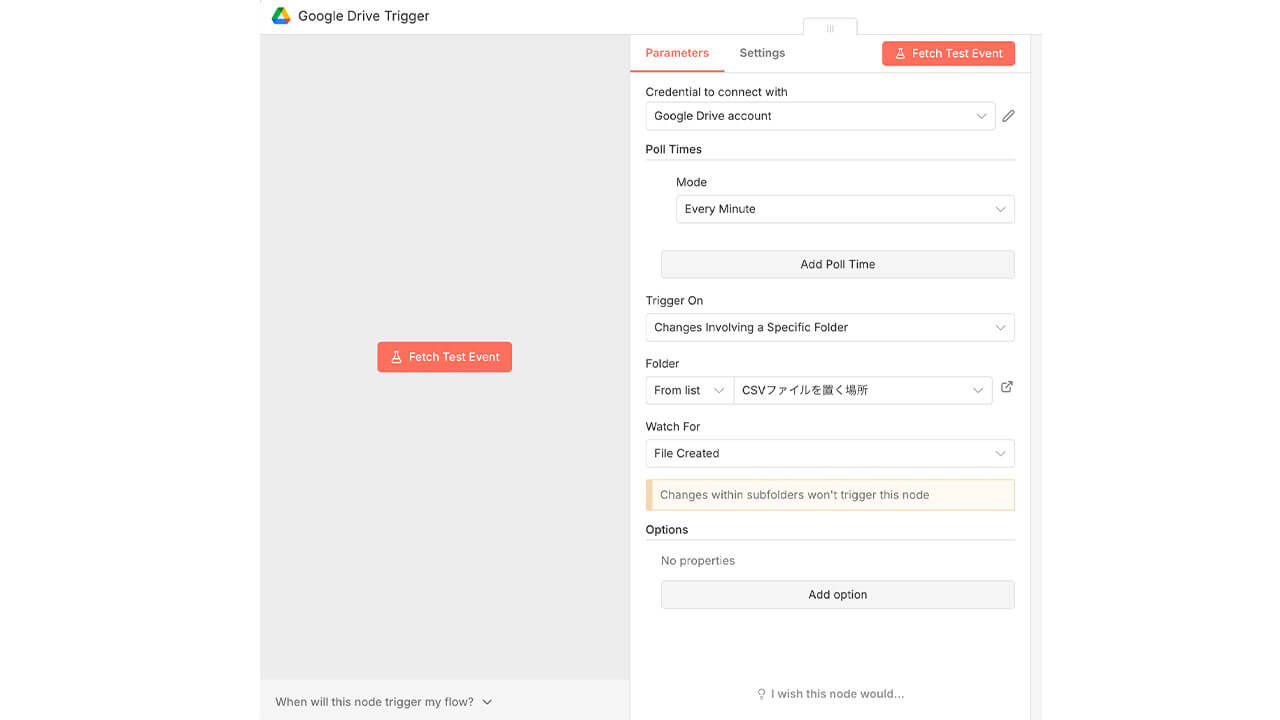
具体的な設定画面では、まず接続するGoogleアカウントを選択し、監視のタイミング(Poll Times)を「Every Minute(毎分)」などに設定します。
次に、監視対象(Trigger On)を「Changes Involving a Specific Folder」とし、対象のフォルダを指定します。
さらに、実行のきっかけ(Watch For)を「File Created」に設定することで、新しいファイルが置かれたときのみ動作するように限定します。
そして、トリガーが検知した最新ファイルの「ID(識別番号)」を、二つ目の「Google Drive Downloadノード」が取得し、対象のファイルをダウンロードします。
この際、トリガーノードから渡された「File ID」を動的に指定することで、常に最新のファイルだけを確実にダウンロードすることが可能です。
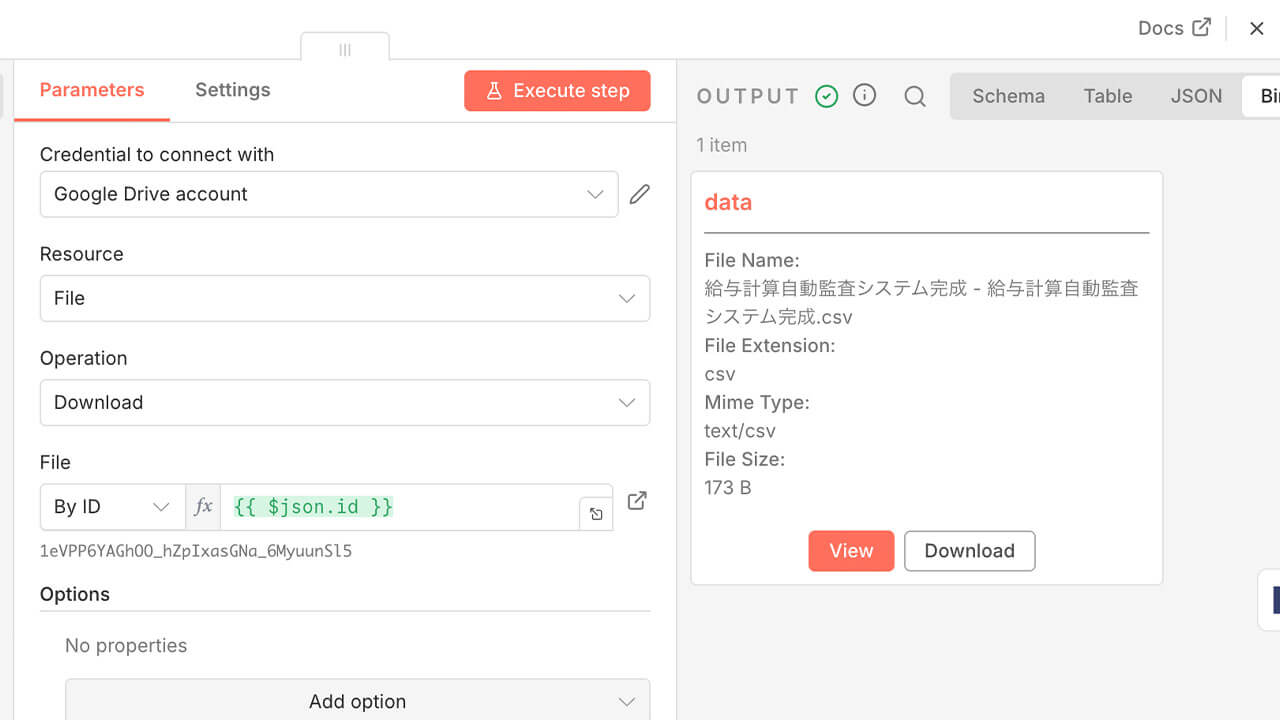
ここでは、Operationを「Download」に設定し、対象ファイル(File)を「By ID」で指定します。
上図の右側の出力結果(OUTPUT)を見ると分かる通り、これにより給与データがシステム内にバイナリデータとして取り込まれ、解析の準備が整います。
解析・正規化(データ整理)
しかし、ダウンロードされたバイナリデータは、まだシステムにとっては「ただのデータの塊」です。
そこで、「ファイルから抽出ノード」を配置し、中身を1行ずつのリスト形式に展開することで、システムが「名前」や「基本給」といった項目ごとに内容を読み取れる状態に整理します。
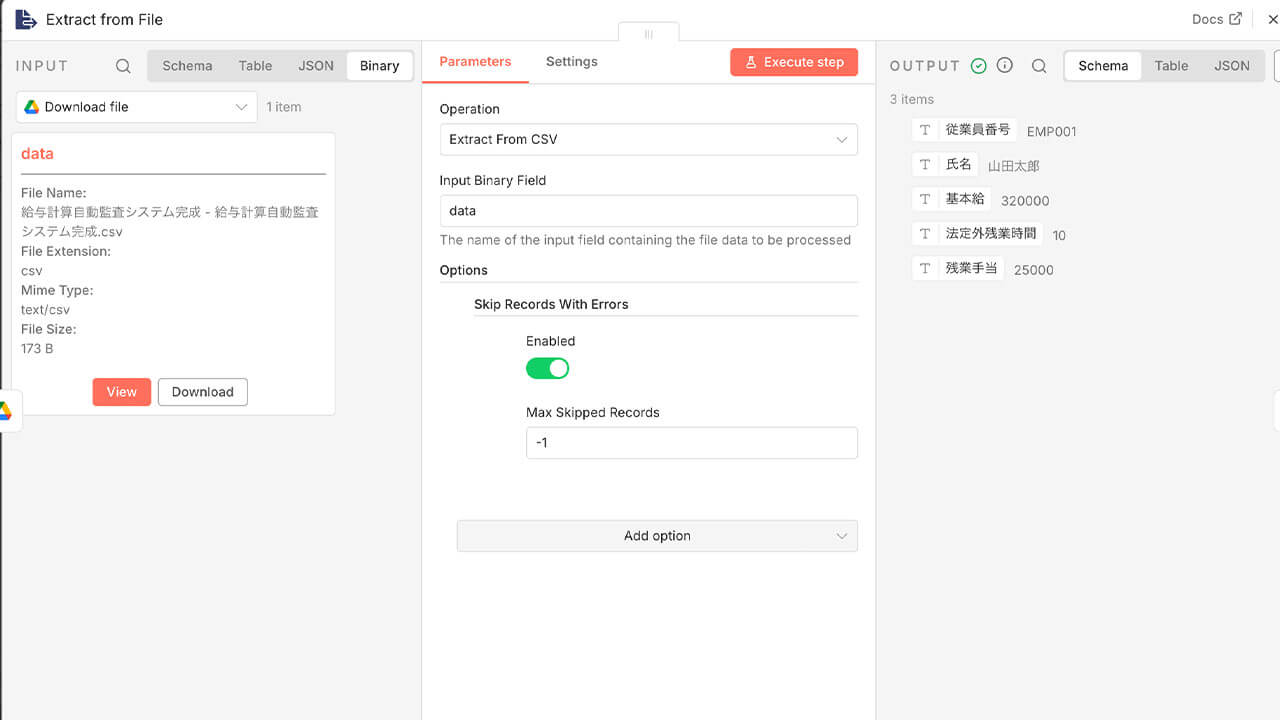
ここでは、Operationを「Extract From CSV」に設定し、直前のステップで取得したバイナリデータ(data)を読み込ませることで、「従業員番号」「基本給」といった項目が構造化されたデータとして抽出されます。
また、計算の正確さを守るため、あえて装飾のない「CSV形式(カンマ区切りのデータ)」を使用します。
Excelファイルのようにセルの中に色や計算式が混ざっていないため、システムが純粋に数値だけを確実に読み取ることができ、計算ミスやエラーを未然に防ぐことができます。
照合・仕分け(ロジック)
次に、If(条件分岐)ノードにより、全従業員のデータを一瞬で検証する自動照合プロセスを実装します。
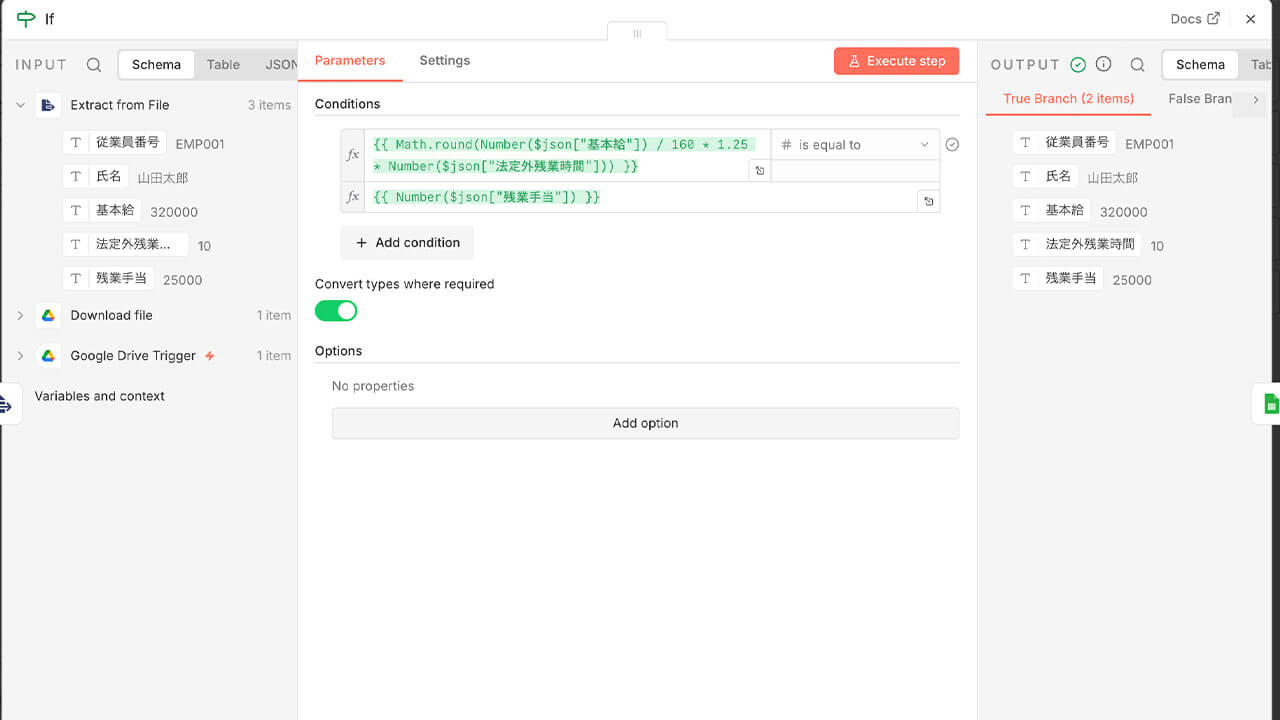
ここでは、「月間所定労働時間」を160時間とし、時給を1.25倍に設定して、理論上の「残業代」を算出します。この計算を人間が電卓を叩く代わりに行わせるため、以下の検証ロジックを組み込みます。
検証ロジック(例): {{ Math.round(Number($json[“基本給”]) / 160 * 1.25 * Number($json[“法定外残業時間”])) }}
設定画面の「Conditions」にこの数式を入力し、比較対象(Value 2)には、CSVから抽出された実際の「残業手当」の値を指定します。そして、比較演算子を「is equal to(等しい)」に設定します。
この理論上の計算結果と、実際に支給されている「残業手当」を比較することで、n8nが計算の一致する「真実(True)」ルートと、不整合が生じている「間違い(False)」ルートに、全件データを自動的に仕分けます。
このようにIfノードを用いることで、「正常なものはそのまま通し、確認が必要な例外だけを抽出する」という例外管理の仕組みを構築することができます。
出力(アウトプット)
最後に、照合ロジックで「間違い(False)」ルートへと振り分けられた不整合データのみを抽出し、管理者が確認すべき「例外リスト」として自動出力します。
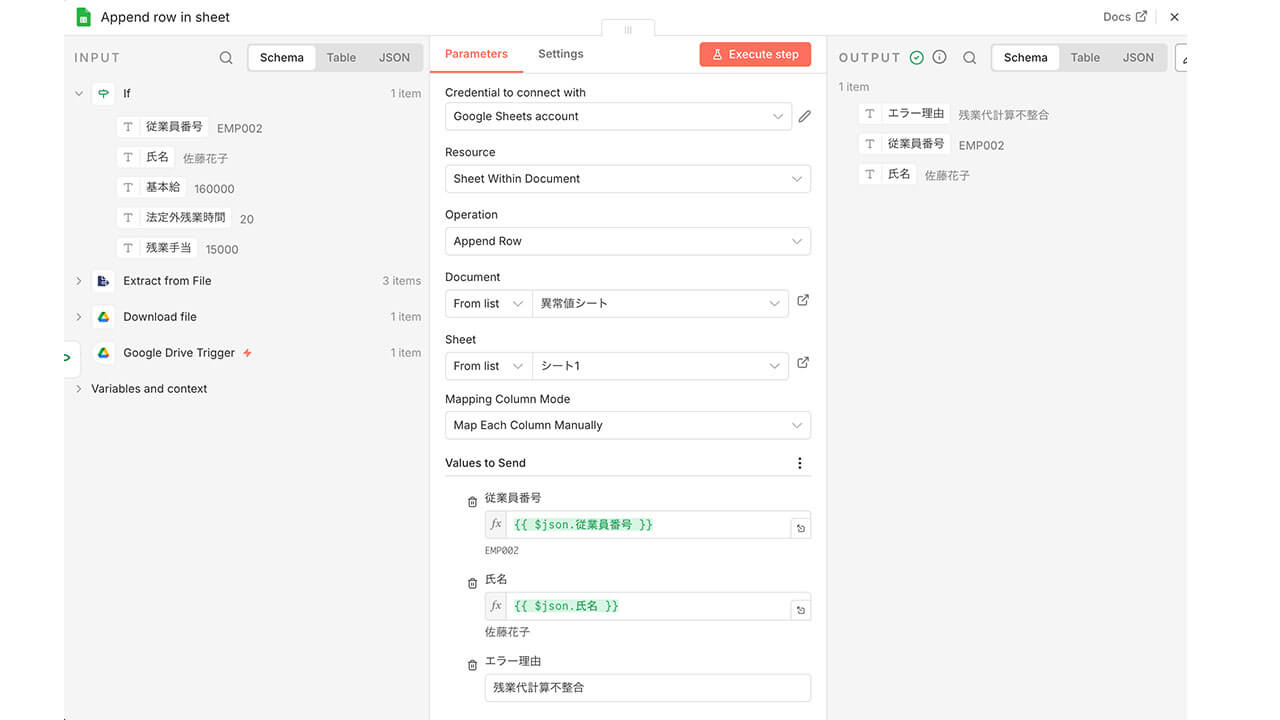
あらかじめ出力先となるスプレッドシートを作成しておき、Google Sheetsに行を追加するノードの設定画面で、異常が見つかった従業員の「従業員番号」「氏名」「エラー理由」を自動で追記(Append)するよう指定します。
これにより、「不整合」と判定されたデータのみが、その理由と共に自動的に記録されています。

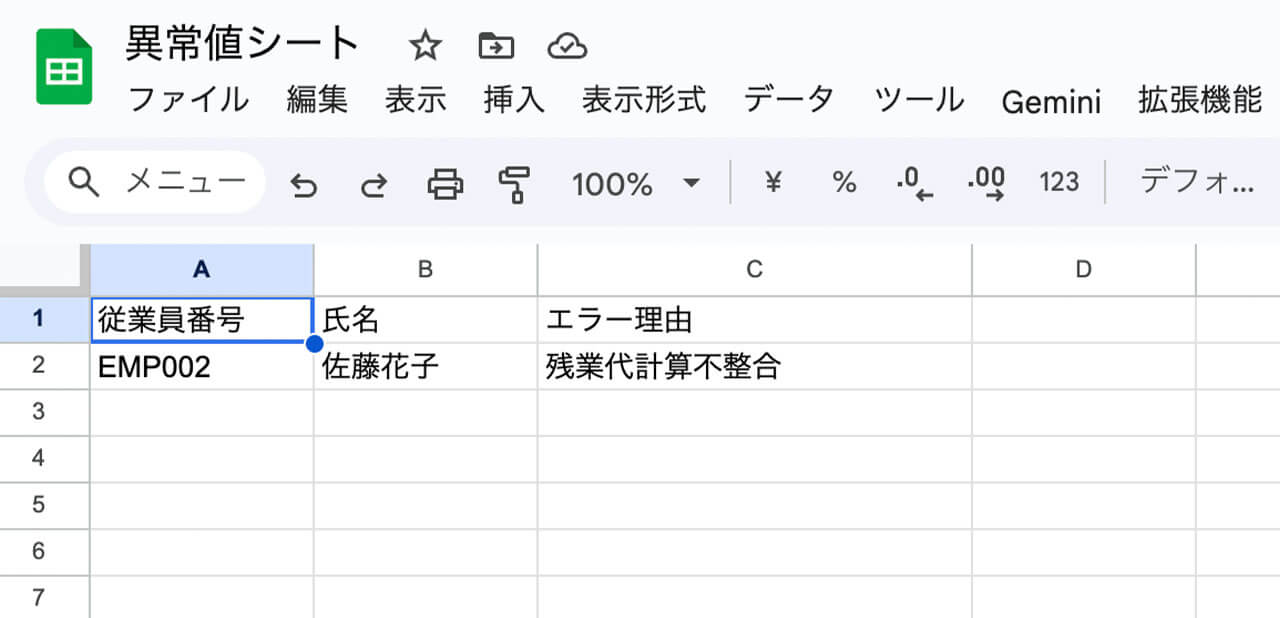
ここでの「不整合(異常データ)」とは、単なる計算ミスだけでなく、入力時の誤字や、本来支払われるべき残業代が不足している「未払い」の可能性などを指します。
システムがこれらを自動検知することで、担当者は全件をチェックする手間から解放され、「疑わしいデータ」のみに集中して確認作業を行うことが可能になります。
なお、今回は「残業代」に絞った照合を行いましたが、このワークフローは拡張することも可能です。
例えば、Ifノードを更に追加して「深夜手当の計算不一致」や「社会保険料の控除額チェック」などの条件を連結させることで、より多角的な監査システムへと進化させることができるでしょう。
一つの大きなプログラムを作るのではなく、判定条件(ノード)をパズルのように組み合わせることができるのが、ノーコードならではの設計思想です。
運用におけるリスク管理と対策
システムが完成し、自動で動くようになると、つい「すべてお任せ」にしたくなります。
しかし、給与という極めて重要なデータを扱う以上、想定外の事態に備えた「守り」の設計が不可欠です。
そこで最後に、システムを安全に使い続けるためのリスク管理のポイントを整理します。
「型」の不一致によるエラーを防ぐ
システムは「数値」と「文字」を厳密に区別します。
CSVから読み込んだ数字が、システム上で「文字」として認識されてしまうと、正しい計算ができずに全員がエラー判定されてしまうリスクがあります。
そこで、数式の中で Number関数を使い、強制的に数値として扱う処理(型変換)を徹底します。
また、n8nのIfノードにある「必要に応じて型を変換する(Convert types where required)」設定を有効にしておくことで、データの形式に左右されない強固なロジックを維持します。
計算結果の「わずかなズレ」への許容
割り算を含む計算では、小数点以下の端数が発生します。理論上の計算結果が25,000.0001で、支給額が25,000 だった場合、人間は「一致」と判断しますが、システムは「不一致」とみなしてしまいます。
そこで、Math.round(四捨五入)などの関数を活用し、計算結果を整数に整えることで、1円未満のわずかな差異による誤判定を防ぎます。
会社の規定に合わせて、切り捨てや切り上げを使い分けることが重要です。
「人間による最終確認」をプロセスに組み込む
自動化の目的は、人間を排除することではなく、人間が「最終判断」に集中できる環境を作ることです。
万が一、システム側の数式設定ミスやデータの不備があった場合、自動ですべてが完結する仕組みだと、誤ったまま処理が進むリスクがあります。
そこで、システムの役割を「異常のあぶり出し」に限定します。
出力されたスプレッドシートを見て、担当者が「なぜこの不整合が起きたのか」を確認した上で、給与確定の判断を下すという運用フローを構築することが重要です。
ワークフローの有効化と監視
n8nを「Active(有効)」にすると、画面を閉じていても自動で処理が実行されます。
これは便利である反面、気づかないうちにエラーで処理が止まってしまうリスクもあります。
そこで運用開始後は、定期的にn8nの「実行履歴」を確認する、あるいは、エラーが発生した際にのみSlackやメールで管理者に通知が届くような「エラー通知ノード」をワークフローの最後に追加することも有効でしょう。
まとめ
給与計算という業務は、毎月、膨大な数字と向き合いながら目視チェックに追われ、担当者の心身に大きな負荷をかけてきました。
今回ご紹介した給与監査の自動化は、システムが正確なロジックに基づいて全件をスキャンし、人間は「異常」と判断された箇所にだけ労力を投入することができます。
この「例外管理型」の体制へと移行することで、担当者の役割は「数字を合わせる作業者」から、給与制度の正当性を担保する「管理・監督者」へと進化します。
まずは、今回構築したような「給与と勤怠の自動照合」などスモールスタートし、徐々に人事マスタや法令チェックへと範囲を広げていくのが良いでしょう。
本記事が、あなたの会社のバックオフィスがよりスマートで、より信頼される存在へと進化するための一歩となれば幸いです。