



現在、プログラミングコードを全く記述しない「ノーコード」や、最小限の記述で効率化を図る「ローコード」のワークフロープラットフォームが、業務改善の現場で普及しています。
これらのプラットフォームは、異なるアプリケーションやAIモデルを「ノード(処理の単位)」として視覚的に繋ぎ合わせ、一連のプロセスを自動化できるのが特徴です。
エンジニアではない担当者が自ら構築できる「手軽さ」と、エンジニアが複雑なロジックを短時間で実装できる「拡張性」を併せ持っているのが強みです。
本記事では、IoTNEWSの生成AI活用ガイドの記事でも多く活用している「Dify」と「n8n」という、2つのノーコード・ローコードツールについて紹介します。
Difyとn8nの主な違い
Difyもn8nも、「ワークフロー構築」という手段は共通していますが、Difyは「LLM(大規模言語モデル)アプリ開発プラットフォーム」、n8nは「汎用的な業務自動化(iPaaS)ツール」という、異なる設計思想と目的を持っています。
Difyは、複雑なRAG(自社データの取り込み)やチャットUIが標準搭載されており、AIアプリの質と使い勝手を高めて構築することができるツールです。
対してn8nは、膨大なSaaS連携と高度なデータ加工が得意で、AIを業務フローのパーツの一つとして組み込むためのツールと言えます。
n8nの方が歴史が長く、テンプレート数や統合数といったエコシステムの規模において数的な優位性が見られます。
GitHubでの注目度(Stars)は両プラットフォーム共に高いですが、Difyは急速にスター数を伸ばし、2023年5月のOSS化から約2年で10万スターに到達したという経緯があります。
なお、GitHubでの注目度が高いということは、世界中の開発者によって日々機能拡張が進んでいることを示しており、安心して導入できる共通のメリットです。
Difyとn8nの機能や設計面での違い
それでは次に両プラットフォームの機能や設計面での違いについて見ていきましょう。
状態管理
状態管理に関しては、Difyは「会話履歴(メモリ)」や「コンテキスト」をシステム側で自動管理する機能が標準で備わっています。
一方、n8nは基本は1回ごとの実行で完結します。会話履歴を持たせたい場合には、メモリノードやデータベースを使って自前で設計する必要があります。
データ構造
Difyのデータ構造は、プロンプトや会話変数の受け渡しに最適化されているテキストやコンテキストが中心です。
n8nは、あらゆるAPIレスポンスをJSONとして扱い、JavascriptおよびPythonで自由に加工することができます。
RAG(検索拡張生成)
RAGに関しては、Difyの管理画面には「ナレッジ」という専用セクションがあり、そこにPDFやテキストファイルをアップロードするだけで準備が完了します。
本来、AIに資料を読み込ませるには「文章を細かく切り分ける」「AIが理解できる数値データに変換する」「専用のデータベースに保存する」といった工程が必要ですが、Difyはこれらをすべて裏側で自動的に行います。
この機能により、専門知識がなくても高精度なRAGを数分で構築可能です。
ただし、文章を細かく切り分ける「チャンク分割」のロジックなどはブラックボックス化されている部分があり、極端なカスタマイズはしにくいという特徴もあります。
一方n8nは「構築型」のアプローチで、「ファイルを読み込む」「テキストを分割する」「Embeddings APIを呼ぶ」「Pineconeに保存する」といった各工程をノードとして配置し、パイプラインを自作する必要があります。
どのAIモデルを使うか、どのデータベースにデータを溜めるか、文章をどう切り分けるかといった細かいルールをすべて自分で自由に決められるのが強みです。
しかしその反面、構築に手間がかかり、AI専用の保管庫(ベクトルDB)に関する専門知識も必要になります。
ワークフローの起点
ワークフローの起点となるトリガーと実行では、Difyの場合、基本は「ユーザーからのチャット入力」や「APIコール」で開始します。
最近のアップデートで、特定の時間やイベントで起動する「トリガー」機能も強化されていますが、主眼は対話型アプリです。
一方n8nは、「Webhook受信」「スケジュール(Cron)」「Google Sheetsの行追加」「Slackのメッセージ受信」など、数百種類のトリガーを起点に処理を開始できます。
例えば、「フォーム送信があったらCRMに登録しSlackに通知する」といった、システム間の連携に強みがあります。
アウトプットの形
完成した仕組みを「どのような形で利用するか」という点でも、両者には違いがあります。
Difyは、成果物として専用の「Webアプリ(URL)」を自動で生成します。
チャット画面などの操作画面(UI)が最初からセットになっているため、自分で画面を作る手間がかかりません。
URLを共有するだけで、誰でもすぐにAIアプリとして使い始めることができます。
一方、n8nの成果物は、目に見える画面ではなく、裏側で黙々と動く「処理プロセス」そのものです。
そのため、n8n単体ではユーザーが操作する画面を持ちません。あくまで「特定の条件を満たした時に自動で動く」か、あるいは外部システムから呼び出すための「窓口(APIエンドポイント)」として機能します。
なお、n8nにもWebサイトにチャット窓を設置する機能はありますが、DifyのようにWebアプリそのものを公開・管理する機能とは性質が異なります。
機能や設計面での違いのまとめ
最適な用途としては、Difyはチャットボット、社内AIアシスタント、RAG検索ツールでの用途に適しており、 n8nは業務自動化、システム間連携、ETL処理に適しています。
開発スタイルに関しては、DifyはAIアプリの「仕様」を定義する感覚で、n8nはデータの「流れ」と「処理」を記述する感覚です。
RAG構築に関しては、Difyはファイルをアップロードするだけなのに対し、n8nはノードを組み合わせてパイプラインを自作する必要があります。
最終的なエンドユーザーへの提供は、Difyは自動生成されるWebアプリを共有するのに対し、n8nは別のアプリや自社システムを通じて機能を提供する形になります。
結論、人間が使う「AIアプリ」を作りたいならDifyのアーキテクチャが適しており、システムが裏で動く「自動処理」を作りたいなら n8nのアーキテクチャが適しています。
そのため、n8nでデータを収集し、その要約処理だけをDifyで実行するように呼び出すなど、両者を連携させて互いの強みを活かす構成も一般的です。
実際のワークフローでの比較検証
次に、n8nとDifyを活用し、「ニュースの内容をAIが要約する」というシステムを構築することで、二つの違いについて紹介します。
一見するとシンプルな自動化ですが、そこには以下の3つの要素があります。
- 情報の取得: Webサイトから必要なデータを取り出す
- 情報の処理: AIに命令を出し、要約を作成する
- 成果の出力: 完成した要約を適切な場所に届ける(スプレッドシート、メール、チャットなど)
同じ目的を達成するために、それぞれのツールがどのような「思想」で設計されているのか、その構築プロセスと手触りの違いを比較します。
n8nでの構築
今回のシステムにおけるn8nの強みは、外部アプリの更新を検知して自動起動する「トリガー機能」が充実している点です。
そこで、n8nでのワークフロー構築では、スプレッドシートを監視し、URLが追加されたら自動的に処理を開始する「バックグラウンド実行」という形式を採用しました。
AIを動かすという目的の前に、まず外部アプリからデータを取得し、それをAIが読み取れる形へ変換して、さらに次のアプリへ受け渡すという一連の「接続工程」を、すべて自分自身で定義していきます。
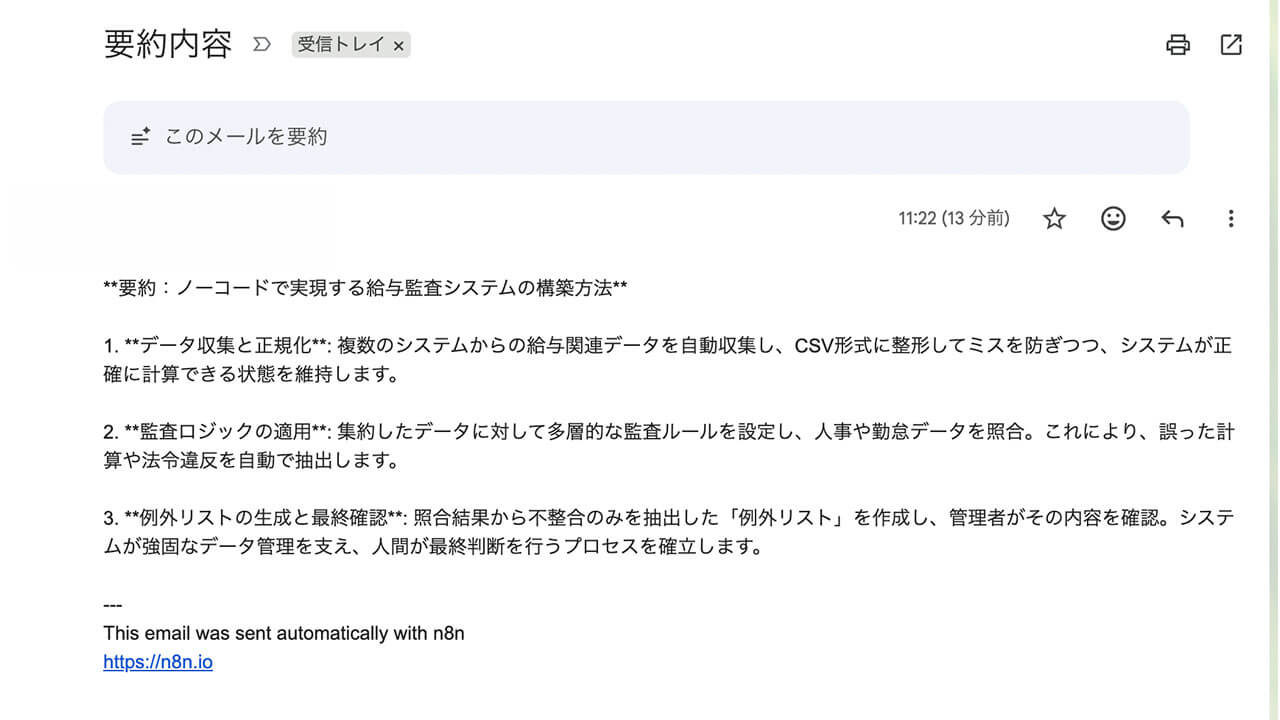
ワークフローの全体像
今回のワークフローは、スプレッドシートの監視から始まり、Web情報の取得、AIによる処理を経て、最終的にシートへの保存とメール送信へと繋げています。

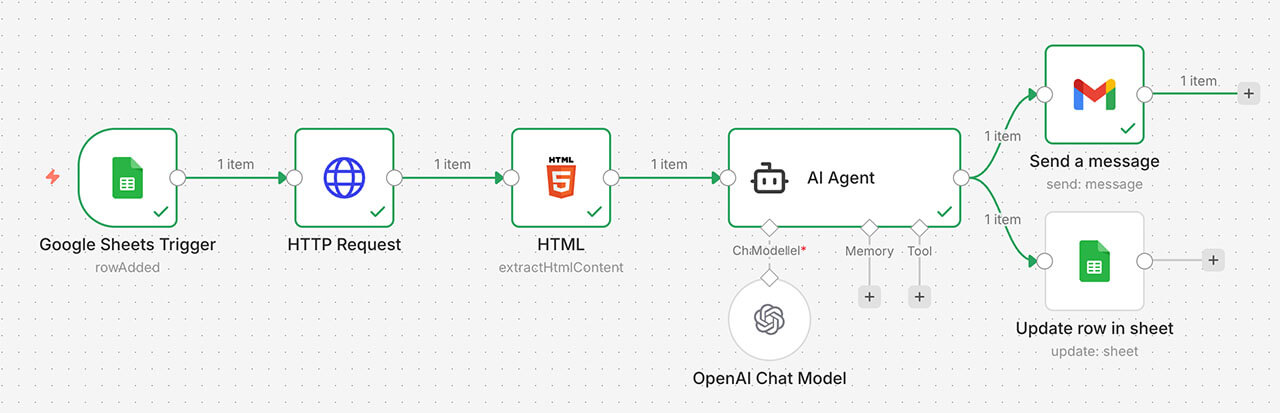
このワークフローは、大きく分けて以下の4つのステップで構成されています。
- URLの検知: スプレッドシートを監視し、新しいURL(原材料)を拾い上げる。
- Web情報の抽出: サイトのHTMLコードを取得し、そこから「本文」だけを削り出す。
- AI要約: 抽出した本文をLLMに渡し、3つのポイントにまとめる。
- 成果の出力: 完成した要約をスプレッドシートの指定したセルに書き戻し、同時にGmailで自分のスマホへ届ける。
なお、AIの役割は、この一連のワークフローにおいてあくまで一部として位置付けられます。
手順
では、具体的な手順を説明します。
一番はじめのトリガーでは、Googleスプレッドシートを監視し、新しい行(URL)がないかを確認させます。
今回は、「毎日決まった時間に、その日追加された新しい行を確認する」というスケジュール実行形式を採用しました。

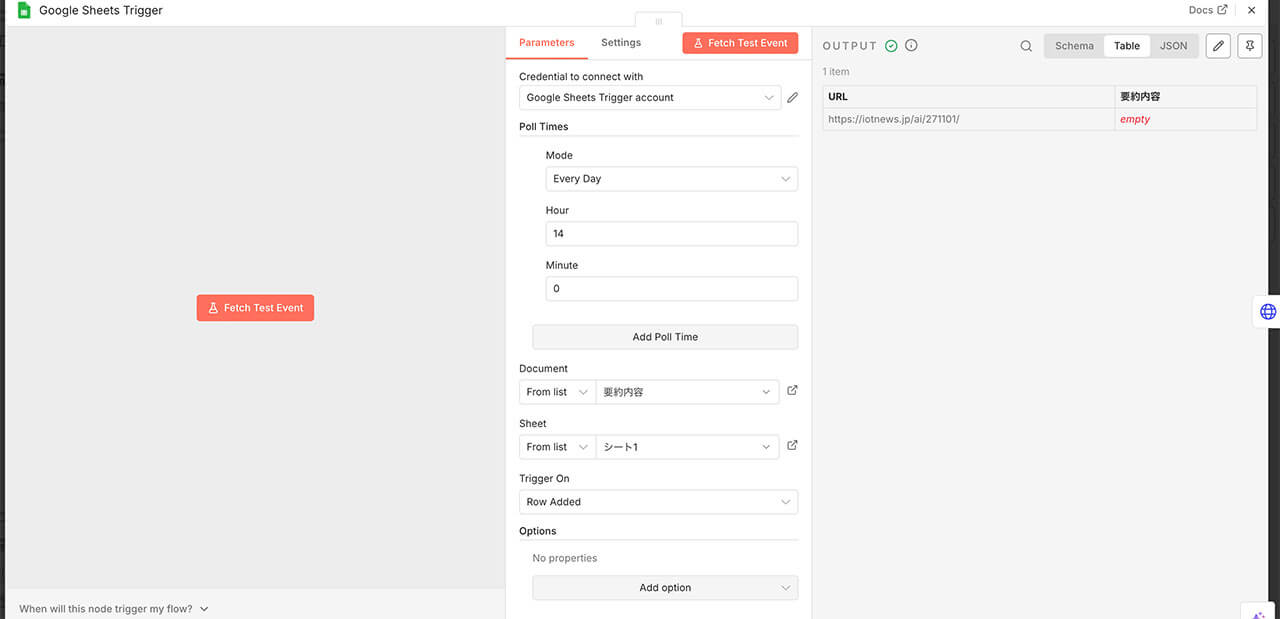
その他にも、設定次第で「新しい行が追加された瞬間にリアルタイムで起動」させることも可能です。
用途に合わせて、バッチ処理(一括処理)か即時処理かを柔軟に設定することができます。
次に、Googleスプレッドシートに追加されたURLの情報から、記事本文だけを自動で抜き出します。
しかしn8nには、「記事を自動で読み取る」という機能がありません。
そのため、サイトの全データを取ってきた後、そこに含まれる大量の広告、メニュー、ランキングといった「本文以外のノイズ」を削ぎ落とす必要がありました。
AIに「本文」だけを届けるための、「データの雑味取り」を行うために、「サイトの全データを取ってくる(HTTP Request)」という工程と、その膨大なデータから「記事本文の場所を指定して抜き出す(HTML Extract)」という工程を組み合わせました。
そして、AIエージェントノードで、データの「住所」を正確に指定し、最終ノードへと繋いでいきます。
下図のように、左側のINPUT欄には、「HTML」「HTTP Request」「Google Sheets Trigger」と、これまでの全工程で発生したデータが階層状に並んでいます。

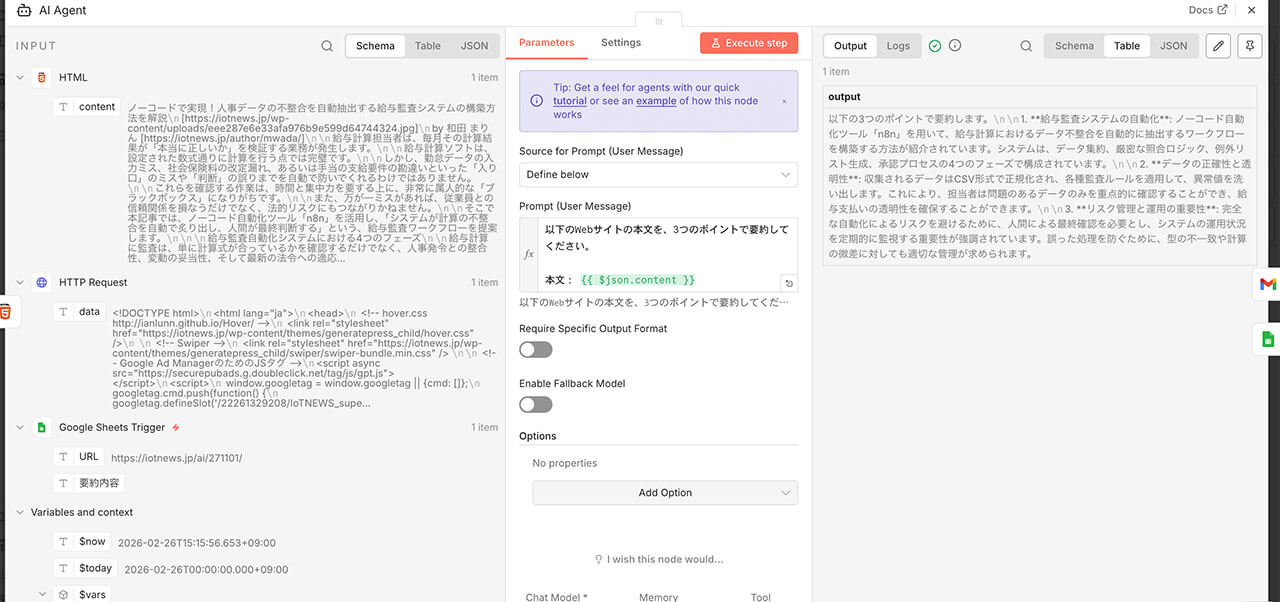
もしここで、間違えて「HTTP Request」の生のデータを渡してしまうと、AIは本文以外の大量の「広告コード」まで要約しようとしてエラーを引き起こします。
そこで、AIエージェントの設定画面にある「Prompt(User Message)」の欄に、「本文:{{ $json.content }}」 と入力します。
これにより、画面左側の「膨大なデータツリー(INPUT欄)」の中から、HTML抽出ノードが作り出した「content」という変数を正確に見つけ出し、AIに渡すことができます。
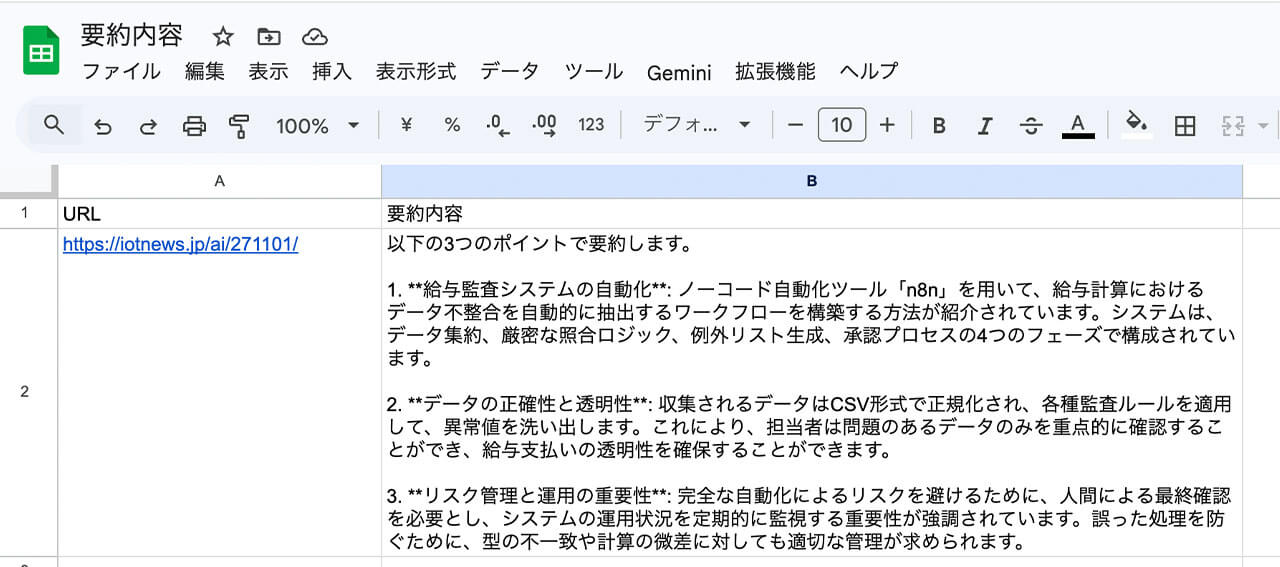
最後に、AIエージェントが生成した要約という「成果物」を、元のスプレッドシートの正しい位置へ戻し、同時に指定したメールアドレスに通知として飛ばすための設定を行います。
スプレッドシートへの書き戻しの設定では、読み込み時に取得した「row_number(行番号)」を変数として指定し、AIの回答テキストを「要約」列に紐付けます。
これにより、バラバラに届いたURLの要約が、元のシートの該当する行に収まります。

一方、AIエージェントの出力をそのままメール本文に流し込む設定では、Gmailノードを使います。
設定画面では、本文の箇所に「{{ $json.output }}」と書くことで、AIが生成した要約文がマッピングされます。
これにより、ワークフローが完了した瞬間に、要約内容が指定したメールアドレスに届く仕組みが完成します。

Difyでの構築
一方、Difyの構築では、n8nのような「スプレッドシートの常時監視(全自動)」ではなく、「チャット欄にURLを貼ると要約が返ってくる(対話型)」という形式を採用しました。
Difyにも最近のアップデートで、Webhookやスケジュールなどの「トリガー機能」が追加されました。
しかし、n8nのように「スプレッドシートの行追加」といったSaaSごとの細かなネイティブトリガーが標準で豊富に用意されているわけではありません。
もしDifyだけでn8nと同じ「スプレッドシートの更新を検知して動く自動化」を実現しようとすると、外部からDifyのAPIを叩くための別のプログラムを自前で用意するか、結局はn8nのようなiPaaS(連携ツール)を介してDifyを呼び出す設定が必要になります。
そのため、今回はあえて人間がURLを投入する形にすることで、要約の精度を確認しながら進められる「AIアシスタント」としての利便性を検証しました。
ワークフローの全体像
Difyのキャンバスは、n8nに比べてシンプルでスッキリとしています。
Web情報の取得や整形といった工程を「ツール」に任せられるため、短い工程でAIまでデータを届けることができます。

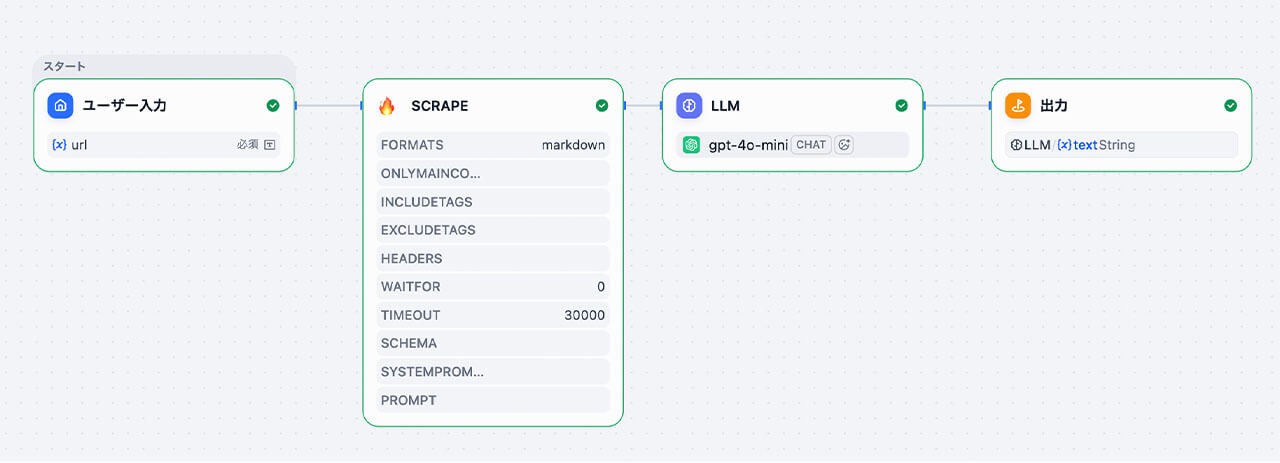
このワークフローは、以下の4つのノードで構成されています。
- 開始(開始ノード): 外部から入力されるURLを受け取る「入り口」を作る。
- Web情報の抽出(Firecrawl): 強力な外部ツールを呼び出し、URLから「本文だけ」を一瞬で抜き出す。
- AI要約(LLMノード): 抽出された綺麗なテキストを受け取り、指示通りに要約する。
- 終了(終了ノード): 要約結果を出力し、次のアクション(スプレッドシートへの書き戻し等)へ繋げる。
n8nではAIが「一連のワークフローにおける一部」でしたが、DifyではAIがシステムの「中心」に位置しています。
手順
では、具体的な手順を説明します。
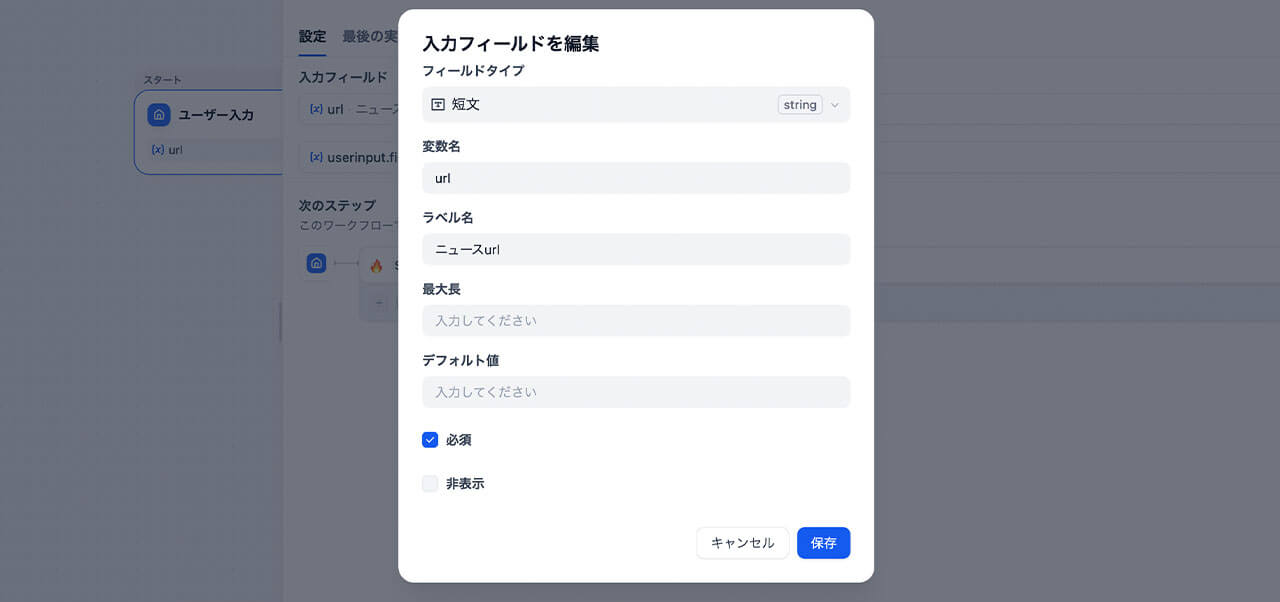
一番はじめの「開始ノード」では、このアプリが受け取る変数を定義します。今回は「URL」という変数をあらかじめ作っておくことで、後続のノードが迷わずにそのデータを使えるようになります。
次に、Webサイトの情報を、AIが理解しやすいMarkdown形式に変換して抽出することに特化した外部サービス「Firecrawl」というツールを組み込みます。
n8nでは広告やメニューなどの「ノイズ」を削るために複数のノードを組み合わせて「雑味取り」を自作しましたが、DifyではFirecrawlを連携させることでこれを完了することができます。
具体的には、設定画面で「本文だけを抽出する」というオプションを選択することで、AIが最も処理しやすいMarkdown形式のテキストを抽出することができます。
そして、LLMノードの設定では、プロンプトの設定画面であらかじめ定義しておいたFirecrawlが抜いてきた本文という変数を選択します。
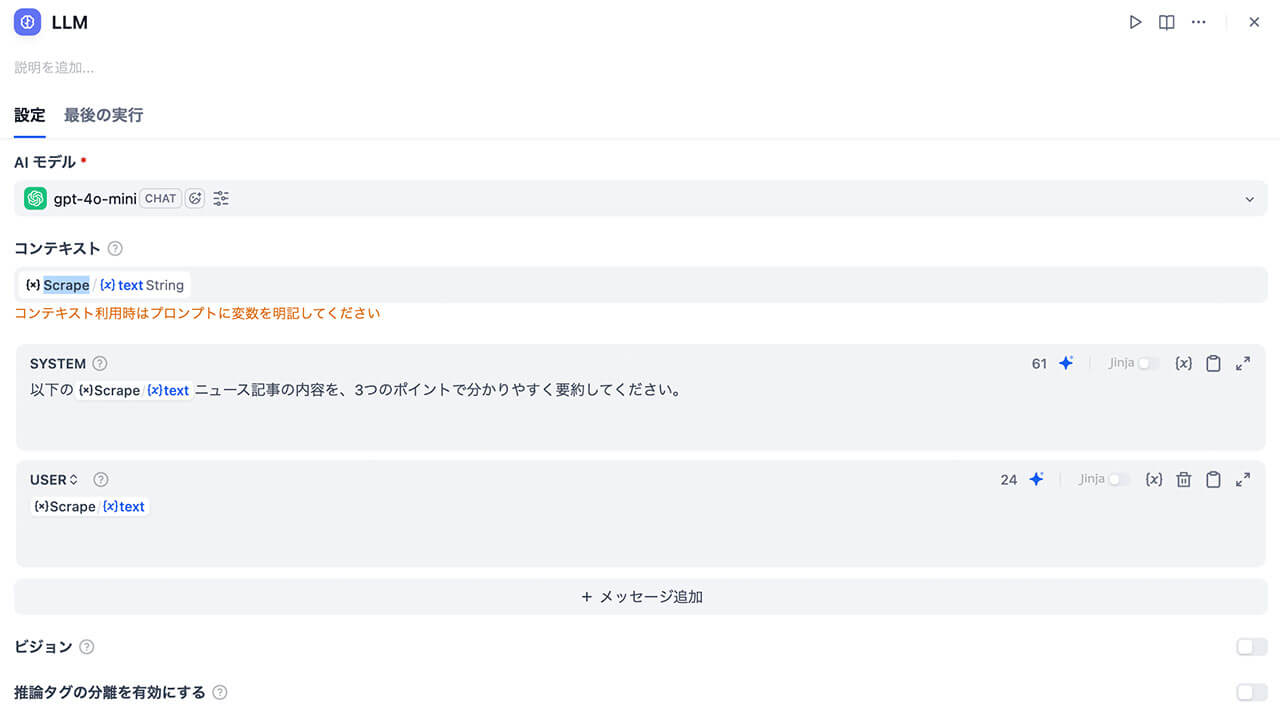
これにより、Firecrawlが整形した記事本文がそのままAIに渡されます。
最後に、AIが生成した要約結果を出力させます。
今回は最も基本的な「チャット画面上に要約結果を表示する」という形式で完結させました。
ユーザーがURLを投げると、その場ですぐにAIの回答を確認できる、対話型のツールとしての構築です。
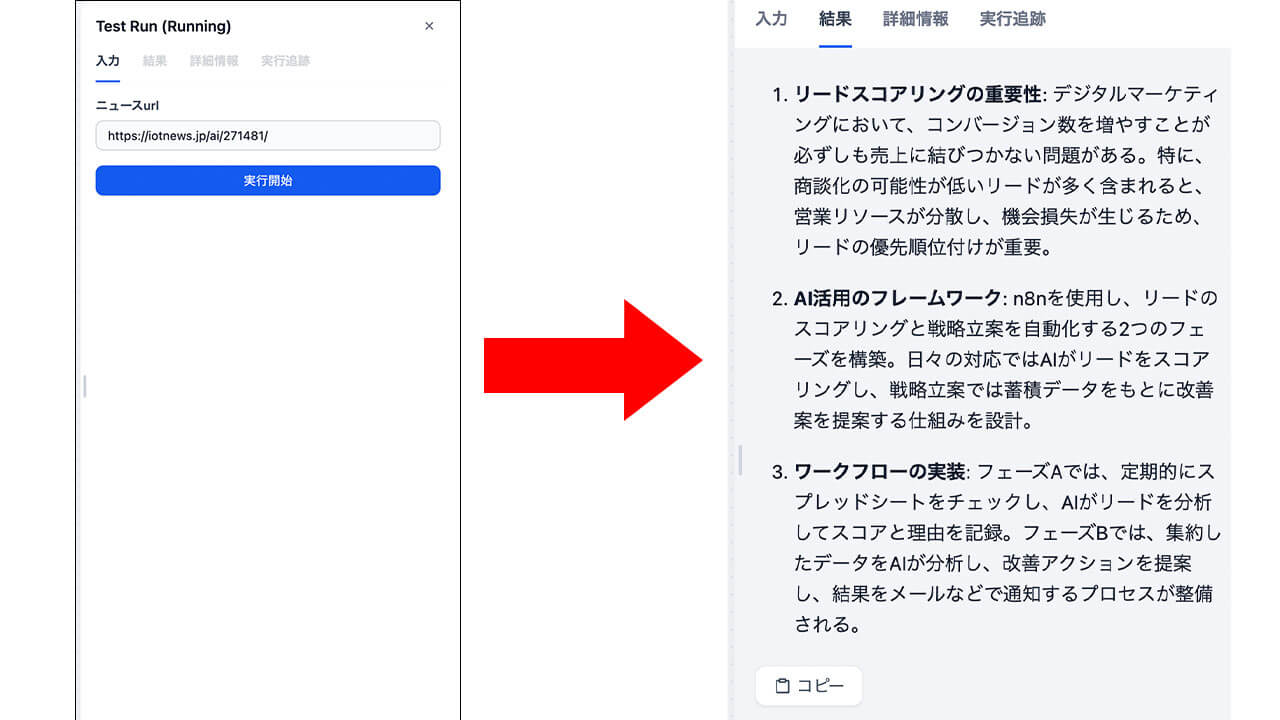
n8nのように「スプレッドシートへの保存」や「Gmailでの送信」まで行いたい場合は、Difyの外部公開APIを利用します。
別の連携ツール(n8nやMakeなど)からDifyを呼び出し、得られた要約結果を次のアプリへと受け渡すことで、さらに高度な自動化へと拡張することが可能です。
比較検証のまとめ
このように、同じ「ニュース要約」という目的でも、n8nとDifyではそのアプローチが異なることが分かりました。
今回の構築を通して見えてきた「違い」を整理します。
トリガーの立ち位置
一つ目の違いは、システムが動き出す「きっかけ(トリガー)」と、その立ち位置です。
n8nの場合、トリガーはスプレッドシートの更新を監視し、新しいURLがある場合に処理を行うというものです。
つまり、「人が介在しない自動化」を構築するのに適しています。
一方Difyは、人間がURLを投げ込み、それに対してAIが即座に答えを返すという自動化です。
つまり、ユーザーとのやり取りを通じて価値を発揮する「AIアシスタント」としての側面が強いのが特徴です。
構築のスタイルの違い
n8nでの構築は、「接続」を構築するイメージです。データが流れる道を一本ずつ物理的に繋いでいくような感覚で、全体の流れを隅々まで自分で制御することに重きが置かれています。全体の工程を正しく動かす仕組み作りに意識を集中させており、AIはその工程の中にある「部品の一つ」という扱いです。
それに対してDifyは、「AIを中心に据えた設計」というスタイルです。
Webサイトの読み取りなどの付随する作業はツール(道具)としてAIに持たせ、自分自身は「AIにどの道具を使い、どのような手順で思考させるか」という、AIの動かし方の設計に集中できます。
AIを単なる部品ではなく、システムの「頭脳」として活用させるための設計になっています。
情報の取り扱いの違い
Webサイトから情報を抽出する際、n8nではサイトの構造を自分で解析し、広告などの不要なコードを手作業で削ぎ落とす「下準備」の工程が必要でした。
一方、DifyではFirecrawlなどの外部ツールを活用することで、最初からAIが理解しやすい「綺麗なデータ」として情報を扱うことができます。
つまり、変換作業を自力で構築するか、ツールに任せられるかという違いがあります。
変数の管理の違い
n8nでは、ワークフローが進むにつれて積み上がる膨大な実行履歴の中から、使いたいデータの「住所」を正確に探し出す緻密な作業が求められます。
一方Difyでは、あらかじめ定義された必要な変数を呼び出すことができます。
自動化がカバーする範囲の違い
n8nが得意とするのは、「業務プロセス全体の自動化」です。
スプレッドシート、メール、Slackといった複数のアプリを複雑に横断し、入り口から出口まで「一本の長い自動化ライン」をミスなく完結させることに長けています。
一方、Difyは、「AI回答の高品質化」と「スピーディーなシステム構築」が特徴です。
高度な要約や的確な判断を行う「賢いAIエンジンそのもの」を磨き上げることに特化しています。
また、チャット画面などのUIもセットで提供されるため、専門的な開発なしで簡易的にAIシステムを立ち上げることができます。
作り上げたシステムを、そのままWebアプリとして、あるいは他のシステムから呼び出して活用するためのプラットフォームです。
まとめ
今回の検証を通して、どちらか一方が優れているのではなく、「全自動のインフラ(n8n)」と「高機能なAIエンジン(Dify)」という、役割の違いが明確になりました。
「Difyとn8nの機能や設計面での違い」の章でも解説した通り、互いの強みを活かす構成が一般的なのもご理解いただけたと思います。
つまり、n8nでスプレッドシートの更新を監視し、要約処理のコア部分だけをDifyのAPIに任せるという「ハイブリッドな連携」が求められているということです。
それぞれのツールの特性を理解し、自分のやりたい自動化に合わせて構築することが重要です。