



ブレインズテクノロジー株式会社は9月14日、同社が2014年から展開している異常検知ソリューション「Impulse(インパルス)」の最新版をリリースした。
最新版のImpulseでは、専門家(データサイエンティスト)の力を借りずに異常検知モデルを自動構築できる独自の機能をさらに拡充するとともに、AIの判定根拠の可視化など、AIとユーザーが「対話」しながらモデルの構築を行える機能を組み込んだ。「Impulse」の新機能について、同社の取締役CPO榎並利晃氏と工場長/CTOの中澤宣貴氏に話を聞いた。
※写真左:ブレインズテクノロジー株式会社取締役CPO 榎並利晃氏、写真右:同社工場長/CTO 中澤宣貴氏
「Impulse」の3つの新機能
製造業では、人間の代わりにAIが設備や製品の異常を見つけだすことで、労働力不足を補うことができると期待されている。しかし実際には、データの分類やクレンジング、最適なアルゴリズムの選択など、AIの学習モデルを構築し、運用するまでには多大な労力がかかる。人間の経験や知恵をAIで自動化しようとしているのに、その自動化のための経験や知恵が必要とされるという課題がある。


そうした課題を解決するため、ブレインズテクノロジーでは、異常検知に特化した学習モデルの自動構築技術を発明し、特許を取得している(※特許第6315528号:「異常検知モデル構築装置、異常検知モデル構築方法及びプログラム」)。
この技術により、データサイエンティストの力を借りなくとも顧客がスムースに学習モデルの構築を進められることが「Impulse」の特徴だ。Impulseは、予兆検知ソリューション市場調査(ミック経済研究所)における解析サービス部門で、2019年度、2020年度ともにトップシェアを占めている。
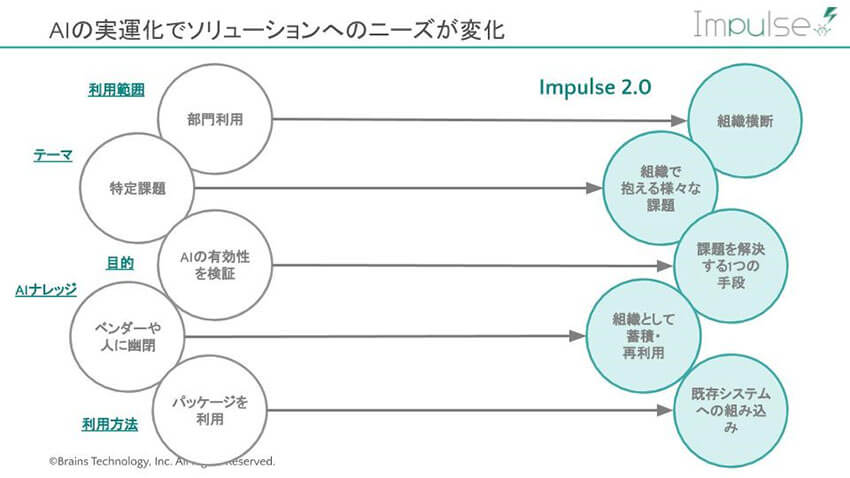
同社は「Impulse」を2014年にリリースして以降、100社、12,000を超える機械学習のモデル運用を支えてきた(PoCを含めると数百社を超える)。その中で同社が培ってきた経験やノウハウを組みこみ、顧客からのニーズにより応える形でメジャーバージョンアップしたのが、「Impulse 2.0」である。
具体的には、次の3つの新機能が加わった。1つ目は、ユーザーが自らアプリをカスタマイズできる機能だ。旧バージョンでは既定のパッケージアプリとしての利用が標準だったが、「Impulse 2.0」からはユーザーがSDKやAPIを介してImpulseが提供するAI機能を利用し、カスタマイズできるしくみを搭載したのだ。
その背景について榎並氏は、「PoCの段階では、簡単に使えるパッケージの方がニーズはあります。しかし運用する段階になると、実際の業務にあった画面開発や既設システムとのインテグレーションが求められます。Impulse 2.0では、そうした運用を行うお客様向けに、自由度が高くかつ簡単にカスタマイズいただけるような機能を搭載しています」と説明する。
2つ目は、「AutoML」の機能拡充だ。AutoMLは、ユーザーが自ら学習モデルの構築を進められるという、Impulseが強みとするしくみだ。ただし、従来は学習プロセスの中で自動化された領域は限られていた。「Impulse 2.0」からは全フローにおいて、自動化される。
しかし自動化とはいっても、ユーザーはAIと「対話」しながら進めていけるフローになっている。例えばアルゴリズム選択では、「最適なアルゴリズムは3つ考えられますが、どれがいいですか」というようにAIが推薦し、ユーザーが選択できる。また、AIがなぜその画像を異常と判定したかなどの根拠を可視化し、説明する機能もある。ユーザーが悩んでしまうポイントや対応策までを包括した「自動化」なのだ。
最後に3つ目は、過去の学習履歴を再利用して高速にモデルを構築する機能だ。複数のタスク(時系列解析や外観検査)に対して、「ユーザーがどのように学習するべきかを学習する」しくみが搭載されている。この機能により、顧客は類似案件での苦労や工夫を社内で共有し、横展開することが可能となる。
以上が、「Impulse 2.0」の3つの新機能の概要だ。次に、それぞれの詳細について、工場長の中澤氏に解説していただいた(聞き手:IoTNEWS 小泉耕二)。
現場が使いこなせる「自由かつ簡単」なAIを追求
IoTNEWS 小泉耕二(以下、小泉): まず、「Impulse 2.0」のカスタマイズ機能について教えてください。
ブレインズテクノロジー 中澤宣貴氏(以下、中澤): 弊社のお客様の多くは、AI活用のフェーズがPoCから運用に移行しつつあります。運用段階で重要なことは、お客様自身が知恵やノウハウを社内で蓄積し、横展開できるようなしくみです。そうでないと、たとえPoCがうまくいったとしても、結局は「人がやればいいじゃないか」という話になってしまいます。
特に製造業のお客様では、AIを用いた異常検知を「生産技術の一つのノウハウ」として自ら獲得していきたいという思いを持っている方が多いです。「Python」などのプログラミング言語を使って自分たちでコードを書きたいというお話もいただきます。
ただ、スクラッチによる独自開発は自由度が高い反面、手間もかかります。「Impulse 2.0」ではそうしたトレードオフを考慮して、お客様の方で「自由かつ簡単に」カスタマイズができるようなアーキテクチャに変更しています。
たとえば、弊社のお客様であるアイシン・エィ・ダブリュ様では、PoCに弊社の標準アプリをご利用いただきました。ただ、アイシン・エィ・ダブリュ様の場合は「こういう形の加工物の異常であれば原因は●●かもしれない」といった知見を社内でお持ちでした。運用段階ではそうしたドメイン知識も組みこみ、全体として使いやすいアプリ環境をお届けしました。すでに、10~20ラインで使用していただいています。

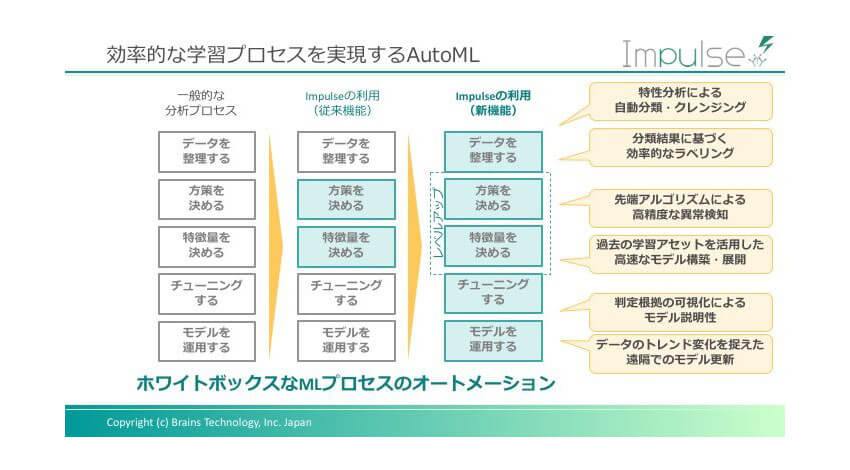
中澤: 「Impulse 2.0」の2つ目の新機能は、「AutoML」です。「Auto」とあるように機械学習の個々のプロセスを手組ではなくて自動で実行できるのですが、ポイントは、AIが選択肢を提案したり、判定の根拠を説明したり、お客様とAIの「対話式」のしくみになっていることです。
小泉: 例えば、最初のプロセスである「データを整理する」では、どういうことができるのでしょう。
中澤: ここでは、特性分析によって加工物の画像データを分類したり、クレンジング(データの除去)したりします。この工程を人が行うと、多大な労力がかかります。たとえばデータの除去では、まず画像データを読みこみ、分布の状態から明らかに撮像に失敗したと思われる画像を自動でとりのぞきます。
AIの学習モデルをつくってからでもいいのですが、事前に不要なデータを切り取った方が、ばらつきが減り、学習がスムースにいきます。
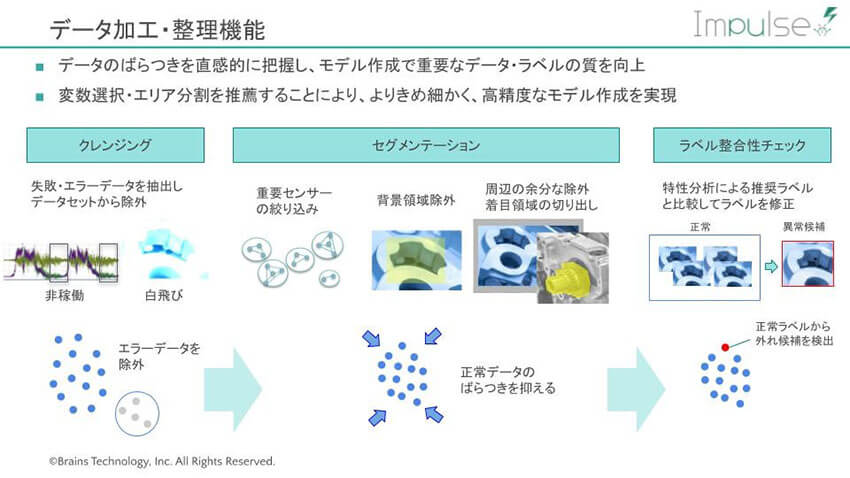
小泉: 複雑な加工物の場合、撮像に失敗した画像データを選ぶのは簡単ではないと思うのですが、そういう場合はどうするのでしょう。
中澤: 実際には、いくつかのモデルで分布を計算して、撮像失敗したデータを推奨します。たとえば、何らかの理由で、カメラの角度が変わってしまった、ということがあります。そうすると、データのばらつきがまた違ってきますので、違うモデルを使って異なる推奨をすることになります。
また、画像はセンサーで収集したデータなどと違い、一つのデータの中に多くの情報が含まれています。ですから、画像1枚をまるごと一つのデータとしてとらえた方がいいのか、着目するエリアを分割した方がいいのかを選ぶ必要があります。それを推薦するしくみがAutoMLには搭載されています。
小泉: コンピューター(AI)はそれをどう判定するのですか。
中澤: たとえば、加工物の傷の程度を見るときに、「つるつるの面」と「ざらざらの面」ではあれば、それは別々に見た方がいいわけです。人間も自然にそのようなことを考慮し、判断しているはずです。異常のばらつきの変動幅が違うものをいっしょくたに見ようとすると、モデルのばらつきが大きくなってしまいます。
それなら、同じ1枚の画像でも初めから領域を分けて解析した方がよいのです。コンピューターはそうしたいくつかのパターンを自ら試し、最もばらつきの少ないものを推薦するわけです。


小泉: なるほど、それができると非常に便利ですね。変種変量生産が進むと、製品の全体はほぼ同じに見えるけど、ねじ穴のサイズだけが少し違う、といったものがたくさん出てきますよね。少し違う製品をつくるたびにまったく違うものとして毎回学習しなければならないとなると大変です。
でも、データ整理の段階で、画像の中の違いをある程度無視していいところと、しっかり見なければならないところを自動で判別してくれるのであれば、だいぶ楽になると思います。
中澤: まさに、そうしたことに対応した機能です。続くアルゴリズム選定の工程でも、読みこんだデータをもとにAIが最適なアルゴリズムをいくつか推薦します。理想的には、異常データがなくても、正常と異常の境界がはっきり別れればよいのですが、そううまくはいきません。
そういう場合は、異常データをいただくか、あるいは分析のレベルを多段階で分けて、後段にいくほどこまかい部分に着目して正常と異常を判定していく、というケースもあります。
小泉: なるほど。これは要するに、AIシステムの開発で最も労力がかかるといわれている、「アノテーション」(データの人為的な分類)の作業が省略できるということですよね。
中澤: そういうことになります。
「学習の仕方を学習するAI」で、現場のノウハウを横展開
中澤: またAutoMLでは、「チューニング」のプロセスにも対話式を取り入れています。チューニングは、できあがった学習モデルを試し、その正答率を上げるために修正していく工程です。
2014年以降さまざまな案件を進めてきた経験から、チューニングのノウハウが弊社のエンジニアの中に蓄積されてきています。Impulse 2.0ではそうしたノウハウをAutoMLに組みこむことで、例えば「こういうデータならこういうクレンジングをした方がいいですよ」といった提案をチューニング時にすることができます。
また、モデルの正答率だけで決めるのではなく、「これくらいのレベルの傷なら許容できる」というお客様のポリシーも考慮しながら、チューニングを実行することができるのです。
小泉: AutoMLでは、全体でどれくらいのコスト(時間)を削減できますか。
中澤: ケースバイケースですが、一般的な分析プロセスを、AutoMLを使わずに行うときと比較すると、最低でも半分以下には削減できるはずです。あるお客様では、半年かけて行っていたことがAutoMLを使うことで「1晩でできた」ということもありました。
小泉: それはすごいですね。
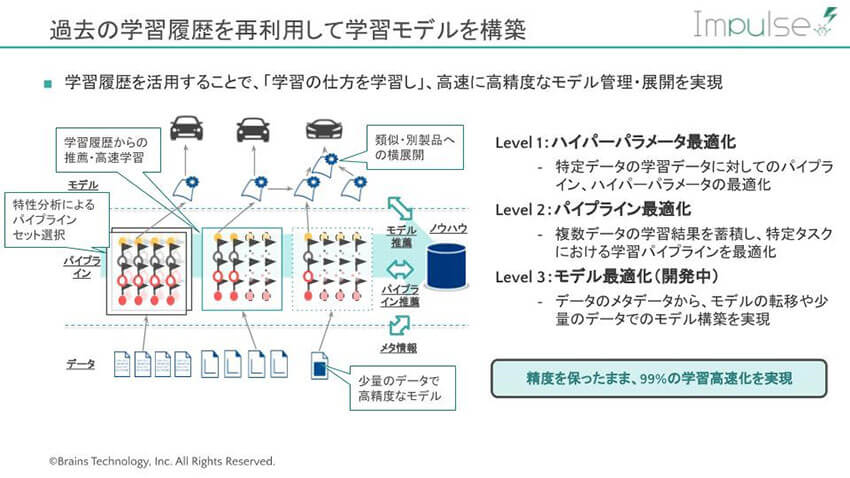
中澤: Impulse 2.0の3つ目の新機能は、過去の学習履歴を再利用して学習モデルを構築する機能です。すでに別の類似したタスクで採用した前処理の方法などを読みこみ、互いに競わせて、最適な方策を推薦するしくみです。言いかえれば、複数のタスク(時系列解析や外観検査)に対して、「ユーザーがどのように学習するべきかを学習する」のです。
先ほどご説明したAutoMLの機能を使うことで、学習モデルの構築はかなりスムースに行うことができるようになります。とはいえ、タスクが変わるたびに毎回ゼロからモデルを構築するのは大変です。
そこで、この機能が活躍します。お客様は、既にある学習モデルをベースに、類似した新しいタスクのモデル構築を高速で行うことができるようになります。
小泉: 現場のノウハウをAIが学習し、さらに横展開までしてくれると。とてもありがたい機能ですね。
全体を通してお話をうかがっていて、とても感慨深いです。世の中ではAIが注目されていながらも、結局は人間が労力をかけ、試行錯誤でつくっているケースが多いなと感じていました。でも本来は、そうした労働から人間を解放してくれるのがAIの役割ですよね。そういう意味でImpulse 2.0は、本来のあるべきAIの姿を体現しているように思いました。
中澤: ありがとうございます。Impulse 2.0の特徴は、まさにそういう部分にあります。アルゴリズム選択などはこれまでエンジニアが血眼になって行ってきました。しかし、AIの力を最大限発揮するには、そうした工程すらも自動化していかなければなりません。
小泉: 本日は貴重なお話をありがとうございました。
-------------------------------
【無料セミナー情報】
この「Impulse 2.0」の機能詳細を解説するオンラインセミナーは、
2020年10月16日 (金) 15:00~16:00 に開催される。
→申込みはこちら<https://info.brains-tech.co.jp/impulsewebinar-v2>