

現場が使いこなせる「自由かつ簡単」なAIを追求
IoTNEWS 小泉耕二(以下、小泉): まず、「Impulse 2.0」のカスタマイズ機能について教えてください。
ブレインズテクノロジー 中澤宣貴氏(以下、中澤): 弊社のお客様の多くは、AI活用のフェーズがPoCから運用に移行しつつあります。運用段階で重要なことは、お客様自身が知恵やノウハウを社内で蓄積し、横展開できるようなしくみです。そうでないと、たとえPoCがうまくいったとしても、結局は「人がやればいいじゃないか」という話になってしまいます。
特に製造業のお客様では、AIを用いた異常検知を「生産技術の一つのノウハウ」として自ら獲得していきたいという思いを持っている方が多いです。「Python」などのプログラミング言語を使って自分たちでコードを書きたいというお話もいただきます。
ただ、スクラッチによる独自開発は自由度が高い反面、手間もかかります。「Impulse 2.0」ではそうしたトレードオフを考慮して、お客様の方で「自由かつ簡単に」カスタマイズができるようなアーキテクチャに変更しています。
たとえば、弊社のお客様であるアイシン・エィ・ダブリュ様では、PoCに弊社の標準アプリをご利用いただきました。ただ、アイシン・エィ・ダブリュ様の場合は「こういう形の加工物の異常であれば原因は●●かもしれない」といった知見を社内でお持ちでした。運用段階ではそうしたドメイン知識も組みこみ、全体として使いやすいアプリ環境をお届けしました。すでに、10~20ラインで使用していただいています。
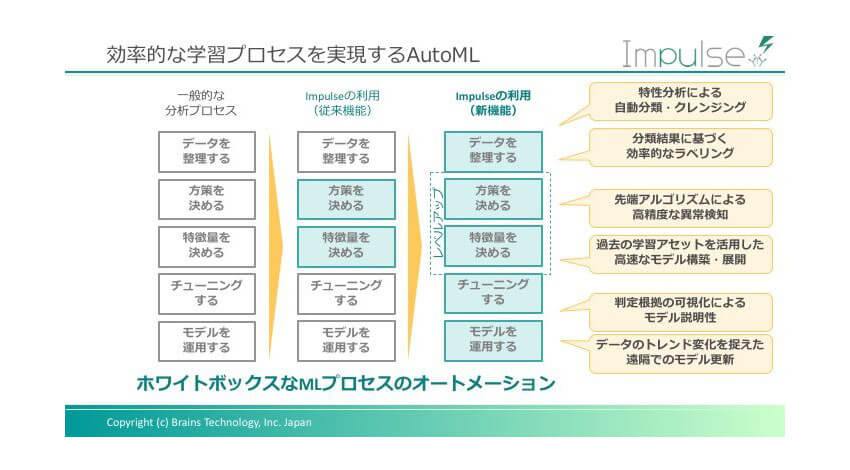
中澤: 「Impulse 2.0」の2つ目の新機能は、「AutoML」です。「Auto」とあるように機械学習の個々のプロセスを手組ではなくて自動で実行できるのですが、ポイントは、AIが選択肢を提案したり、判定の根拠を説明したり、お客様とAIの「対話式」のしくみになっていることです。
小泉: 例えば、最初のプロセスである「データを整理する」では、どういうことができるのでしょう。
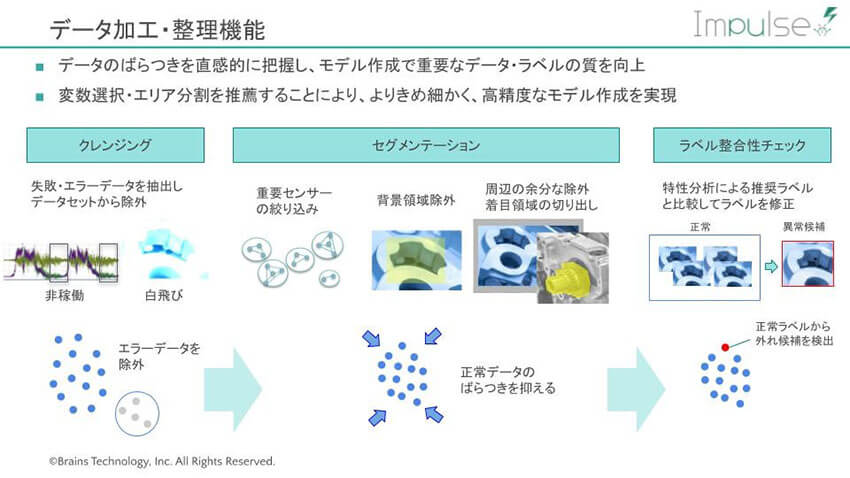
中澤: ここでは、特性分析によって加工物の画像データを分類したり、クレンジング(データの除去)したりします。この工程を人が行うと、多大な労力がかかります。たとえばデータの除去では、まず画像データを読みこみ、分布の状態から明らかに撮像に失敗したと思われる画像を自動でとりのぞきます。
AIの学習モデルをつくってからでもいいのですが、事前に不要なデータを切り取った方が、ばらつきが減り、学習がスムースにいきます。
小泉: 複雑な加工物の場合、撮像に失敗した画像データを選ぶのは簡単ではないと思うのですが、そういう場合はどうするのでしょう。
中澤: 実際には、いくつかのモデルで分布を計算して、撮像失敗したデータを推奨します。たとえば、何らかの理由で、カメラの角度が変わってしまった、ということがあります。そうすると、データのばらつきがまた違ってきますので、違うモデルを使って異なる推奨をすることになります。
また、画像はセンサーで収集したデータなどと違い、一つのデータの中に多くの情報が含まれています。ですから、画像1枚をまるごと一つのデータとしてとらえた方がいいのか、着目するエリアを分割した方がいいのかを選ぶ必要があります。それを推薦するしくみがAutoMLには搭載されています。
小泉: コンピューター(AI)はそれをどう判定するのですか。
中澤: たとえば、加工物の傷の程度を見るときに、「つるつるの面」と「ざらざらの面」ではあれば、それは別々に見た方がいいわけです。人間も自然にそのようなことを考慮し、判断しているはずです。異常のばらつきの変動幅が違うものをいっしょくたに見ようとすると、モデルのばらつきが大きくなってしまいます。
それなら、同じ1枚の画像でも初めから領域を分けて解析した方がよいのです。コンピューターはそうしたいくつかのパターンを自ら試し、最もばらつきの少ないものを推薦するわけです。

小泉: なるほど、それができると非常に便利ですね。変種変量生産が進むと、製品の全体はほぼ同じに見えるけど、ねじ穴のサイズだけが少し違う、といったものがたくさん出てきますよね。少し違う製品をつくるたびにまったく違うものとして毎回学習しなければならないとなると大変です。
でも、データ整理の段階で、画像の中の違いをある程度無視していいところと、しっかり見なければならないところを自動で判別してくれるのであれば、だいぶ楽になると思います。
中澤: まさに、そうしたことに対応した機能です。続くアルゴリズム選定の工程でも、読みこんだデータをもとにAIが最適なアルゴリズムをいくつか推薦します。理想的には、異常データがなくても、正常と異常の境界がはっきり別れればよいのですが、そううまくはいきません。
そういう場合は、異常データをいただくか、あるいは分析のレベルを多段階で分けて、後段にいくほどこまかい部分に着目して正常と異常を判定していく、というケースもあります。
小泉: なるほど。これは要するに、AIシステムの開発で最も労力がかかるといわれている、「アノテーション」(データの人為的な分類)の作業が省略できるということですよね。
中澤: そういうことになります。

技術・科学系ライター。修士(応用化学)。石油メーカー勤務を経て、2017年よりライターとして活動。科学雑誌などにも寄稿している。

















