

CES2026レポートの第二弾はエヌビディアだ。
昨年キーノートに登壇したジェンスン・ファンCEOだが、今年はプライベートイベントということで、会場とは異なるホテルで開催された。
ただ、多くのキーノートでジェンスン・ファンは登場し、特にフィジカルAIのテーマではエヌビディアが中心であるという印象を持たざるを得ない状況にもなった。
今回の講演における話題は、その「フィジカルAI」と呼ばれる、ロボティクスや自動運転カーなどで使われるAIの領域の話題と、Vera Rubinと呼ばれる、データセンター用のGPUや周辺のネットワークデバイスなどの2つだ。
フィジカルAIは昨年来エヌビディアが推している領域ではあるが、市場の期待はまだまだデータセンター、すなわち、いわゆる生成AIなど向けのチップの製造や販売状況であるといえる。
しかし、今後数年かけてロボティクスにおける知能向上が進むと見られていて、こちらは具体的な利用例が増えてくることが待たれている。
目次
現実世界を理解し、思考する「フィジカルAI」
NVIDIAが他社と明確に差別化している最大の領域が、デジタルな知能を現実の物理世界へと拡張する「フィジカルAI」だ。
ジェンスン・ファン氏はこれを「ロボティクスにとってのChatGPTが生まれた瞬間」と表現した。
物理法則を学ぶ「3つのコンピューター」
AIが現実世界で活動するには、重力や摩擦、因果関係といった「世界の常識」を理解しなければならない。
そこで、これらを実現するために、NVIDIAは3つの異なるコンピューター・アーキテクチャを統合している。
- トレーニング・インフラ(NVIDIA DGX): 大規模なAIモデルを訓練
- シミュレーション(NVIDIA Omniverse): 物理法則に基づいた仮想空間でAIをテスト・検証
- 推論・実行(NVIDIA DRIVE / Jetson): 車両やロボット内部でリアルタイムに動作
世界基盤モデル「NVIDIA Cosmos」
しかし、これらがあったとしても、実際の世界を訓練しようと思うと、相当な時間とシーンが必要になる。
例えば、大雨が降っている場合、氷で道路が滑る場合、ドライブスルーで注文をして受け取る場合、など、日常生活には様々なシーンが存在する。
これらのすべてを何回もテストすることが現実的に不可能だ。
そこで、こういった物理世界をテストするために生まれたのが、「Cosmos」と呼ばれるオープンな世界基盤モデルだ。
現実世界のデータ収集はコストがかかり困難だが、Cosmosは物理的に正確な「合成データ」を生成することができる。

この合成データを活用することで、現実世界へのシミュレーションを行うことが可能になるのだ。
ロボットや自動運転車は仮想空間で数十億マイルもの試行錯誤を事前に行うことが可能になる。
推論型自動運転AI「Alpamayo(アルパマヨ)」
そして、この技術の集大成として発表されたのが、世界初の思考・推論型自動運転AI「Alpamayo」だ。

Alpamayoは、従来のAIのように単にパターンを認識するのではなく、カメラからの入力から、車の操作までのすべてを訓練されていて、人間のように「なぜその操作を行うのか」を思考し、言葉で説明することができる推論能力を持つという。
現在、アルパマヨのスタックを搭載した新型メルセデス・ベンツCLAは、NCAPで世界最高の安全評価を獲得し、第一四半期に米国で、第二四半期に欧州で順次リリースされているということだ。


また、エンドツーエンドのAIスタックに加え、「NVIDIA Halos」安全システムに基づく従来の安全スタックを並行稼働させることで、絶対的な冗長性と信頼性を確保している。

ジェンスン・ファン氏は、向こう10年で、自動運転が一般的になるとし、その際は、オープンソースとして開発している、Alpamayoが世界の様々な地域での自動運転技術を支えることになるだろう。
これまでは、TeslaやWaymoといった先行して実証実験を行う車が話題となっていたが、今回メルセデスという一般の方にもよく知られているメーカーの車が対応するということで、一気に自動運転の市場がひらけてくる可能性があると感じた。
ロボティクスの未来と産業のデジタルツイン
ここで、Jetsonを搭載し、Omniverseで訓練されたロボットを壇上で紹介した。

LG、キャタピラー、ボストン・ダイナミクス、ユニバーサル・ロボティクスなど、信じられないほど多くのパートナーがロボットを構築しているという。
本当に多くのロボットがエヌビディアの技術に支えられて動いていることがわかる。
AIが大きなテーマとなった今回のCESでも、LGやボストンダイナミクスの人型ロボットが話題となったし、キーノートを務めたシーメンスやキャタピラーなどの企業もエヌビディアの技術を使って物理世界をインテリジェントにしようとしていた。
さらに、フィジカルAIは設計・製造業界も変える。
ケイデンス、シノプシス、そしてシーメンスとの提携によって、チップの設計から工場のライン構築、運用のデジタルツインまで、すべてがエヌビディアの技術で加速される。
今回紹介された小型ロボットなども、コンピュータの中で設計され、コンピュータの中で製造・テストされ、デジタルツイン上で完璧な状態にされるのだ。

エージェント型AIを加速させる次世代プラットフォーム「Vera Rubin」の近況
テクノロジーとしての面白みがあるのがフィジカルAIだとして、実需用として興味があるのは、今後、貪欲な生成AIニーズがおさまることを知らないのか?そして、そのニーズに対応できるのか?という点だ。
ビッグテックはじめ、多くの企業で今まさに取り組んでいる生成AIへの対応だが、期待が高かった一方で「単なるバブルだったのではないか?」という懸念を言う人もいる。
しかし、AIの需要は凄まじいものがあり、毎年そのモデルサイズは10倍に、AIが考えることに使われるトークンは5倍に、そしてコストは1/10倍になっているという。
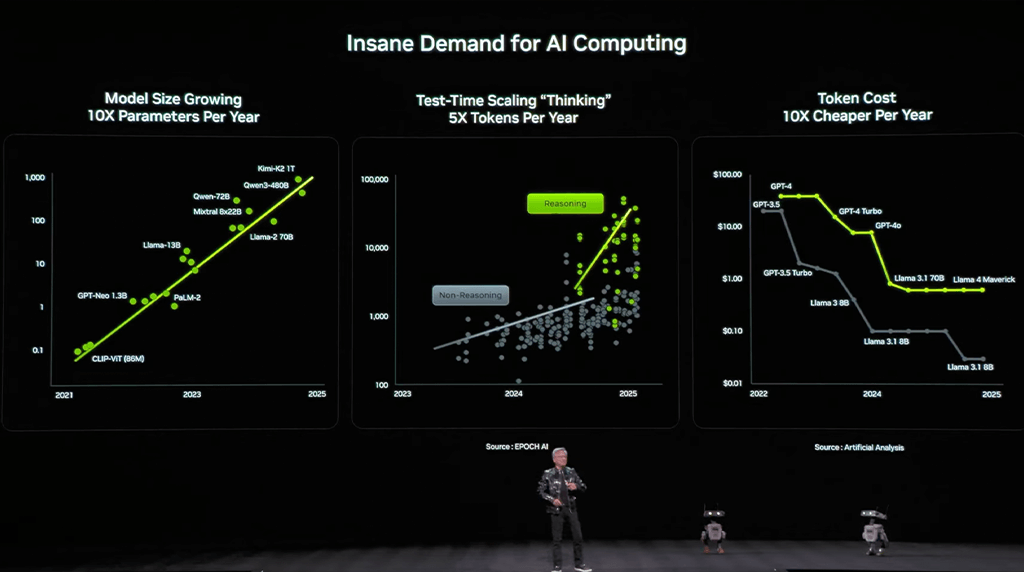
ジェンセン・ファンCEOによると、AIの進化は「単発の回答」から、時間をかけて思考する「推論」へと移行したことで、計算需要は爆発的に増加していまるのだという。
そして、これに応えるのが、最新プラットフォーム「Vera Rubin」なのだ。
エヌビディアは、昨年、現行のGrace Blackwellの後継となる、Vera Rubinを発表していた。その際、Rubinは2026年にはリリースするというマイルストーンを示していて、年が開けて初めの講演でジェンセン・ファンCEOがこの計画がどうなっていると発言されるのかが注目されていた。
それに関して、今回の講演では、「すでに製造が開始されている」ことを発表した。
6つのチップによる「極限の協調設計」
Vera Rubinは、CPU、GPU、スイッチなど6つの異なるチップが最初から一つのシステムとして動作するように「極限の協調設計」がされている。
Vera CPU
前世代比で電力効率を維持しつつ、性能を2倍に向上。88個の物理コア(176スレッド)を搭載した、AIファクトリー向けに最適化されたCPU。

Rubin GPU
Blackwellの1.6倍のトランジスタを搭載しながら、推論性能は5倍に達する。これを支える「MV-FP4 Tensorコア」は、プロセッサ内部で精度を動的に調整し、スループットを最大化する。

ネットワーク(NVLink, Spectrum-X)
毎秒3.6TBの帯域幅を持つ第6世代NVLinkや、シリコンフォトニクス技術をチップに直結したSpectrum-Xスイッチにより、インターネット全体の帯域幅を超えるデータ転送を実現。


ストレージ(Dynamo KVキャッシュ)
エージェント型AIが長時間の対話や調査を行う際、最大のボトルネックとなるのがキャッシュの容量だ。NVIDIAは「BlueField-4 DPU」を活用し、新たなストレージ層を構築した。

イーサーネットスイッチ
シリコンフォトニクス技術を使い、新しく開発されたSpectrum-Xは、200Gビット/秒の通信を512ポートで実現する。

配線のないトレイ
これまで、GPUのトレイにはボード間を繋ぐケーブルがあったが、今回からケーブルレスのトレイとなった。
スピードを考えるとこの構成が最も早くなることはいうまでもない。

このトレイの中に様々な新しいチップが格納され、それ同士が繋がり、データセンターに格納されるのだ。
トレイへの収納作業もBlackwellの時は2時間以上かかっていたのが、Rubinだと5分で完了するとのことだ。
KVキャッシュ
実際に、AIと様々なやりとりをする中で、やり取りの記憶を残して欲しいと思うことがある。
しかし、これを完全に行おうとすると処理がパンクしてしまい、AIが処理を上手く捌けないという問題が起きる。
こういった経験はよくあることだが、これに対応するために、新しいKVキャッシュをBluefield4を活用した「ラック内KVキャッシュストレージ」を導入しした。
各Bluefield4の背後には150テラバイトの文脈メモリが接続されており、システム全体で各GPUに追加の16テラバイトのメモリが割り当てられる。
GPU単体では約1テラバイトの内部メモリしか持たないのだが、この補助記憶装置により、16倍の拡張が実現するということだ。

実際のデータセンターに設置される際は、上の写真のように、1152個のGPUが16個のラックに格納され、各ラックには、72個のRubinが入るのだということだ。
この機構によって、電力は約6%低減され、また、GPUやCPUなど書く演算チップ間のデータ秘匿性も実現され、企業での利用においても安心して使える。
圧倒的な経済性と効率を見せるパフォーマンス
今回のVera Rubinの発表を見ていると、単にGPUがスピードアップしたというよりは、AIが動くための環境全体を刷新したイメージを持った方が多いのではないだろうか。
ジェンスン・ファン氏によると、そうでもしない限り、AIの需要には対応できないから、ということなのだが、それをこの短期間で実現したエヌビディアの力が恐ろしい。
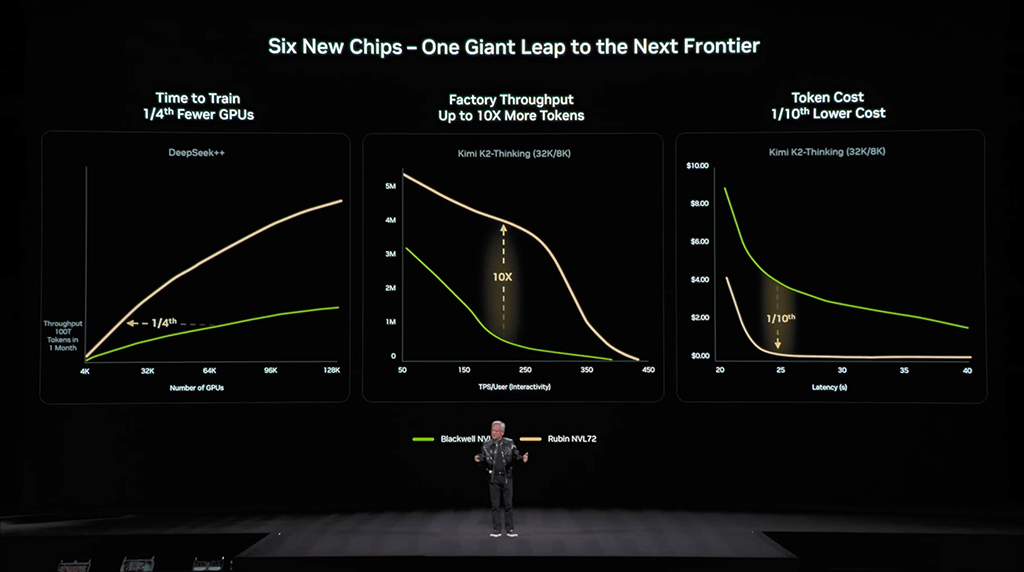
こうやって組み上がったシステムにより、Vera Rubinは、Blackwell世代と比較して、MoE(Mixture of Experts)モデルの訓練に必要なGPU数を4分の1に削減し、AIファクトリーのスループットは10倍に、トークン生成コストを10分の1にまで引き下げるのだ。

エヌビディアが切り拓く「知能の民主化」
エヌビディアの差別化は、チップ単体ではなく、「チップ、インフラ、モデル、シミュレーション、アプリケーション」の5層すべてを垂直統合しつつ、それらをオープンに提供している点にある。
Physical AI Open Datasetの公開や、アルパマヨ・モデルのオープンソース化により、あらゆる企業や研究者がNVIDIAの強力な基盤を利用できるようになってきた。
今後もしばらくはエヌビディア一強の時代が続くと思わざるを得ない講演だった。

無料メルマガ会員に登録しませんか?

IoTNEWS代表
1973年生まれ。株式会社アールジーン代表取締役。
フジテレビ Live News α コメンテーター。J-WAVE TOKYO MORNING RADIO 記事解説。など。
大阪大学でニューロコンピューティングを学び、アクセンチュアなどのグローバルコンサルティングファームより現職。
著書に、「2時間でわかる図解IoTビジネス入門(あさ出版)」「顧客ともっとつながる(日経BP)」、YouTubeチャンネルに「小泉耕二の未来大学」がある。

















