

カスタマーセンターには、「製品への期待」「操作への戸惑い」「叱咤激励」など、顧客からの貴重な声が届いています。
これらの声は、サービスをより良くするための手掛かりとなり得ますが、多くの現場では、日々の応対を記録すること自体がゴールになってしまい、その先の「分析」や「改善」まで手が回っていないのが実情です。
そこには、「記録の仕方が部署や担当者によってバラバラで、集計しようがない」 「自由記述のテキストデータが膨大すぎて、読み込む時間がない」 「システムを改修してデータを構造化するには、膨大なコストと月日がかかる」といった、カスタマーセンター特有の切実な事情があります。
結果として、せっかくの声がExcelやCRMの中に「眠ったまま」の状態になっているケースは少なくありません。
そこで本記事では、分析が進まない障壁を踏まえた上での生成AIの価値に加え、実際に簡易的にできる表計算ソフトを活用した分析や、ボタンひとつで分析を行なってくれるシステムの構築方法を紹介します。
なぜ「既存の記録」の分析が進まないのか
顧客の声(以下、VOC)の分析が停滞してしまう要因は、主に3つの「障壁」があると考えられます。
これらが積み重なることで、カスタマーセンターのデータは「活用できる資産」ではなく、単なる「ログの蓄積」になってしまいます。
表記ゆれと粒度のバラつき
最も大きな壁は、入力される情報の「不揃いさ」です。
同じ「ログインできない」というトラブルでも、ある担当者は「ログイン不可」と書き、別の担当者は「IDエラーにより接続不可」と記録します。
また、一言だけ「操作の質問」と書く人もいれば、経緯を詳細に書き込む人もいます。
このようにデータの粒度や表現が統一されていないため、従来のキーワード検索や単純な集計では、全体像を正しく把握することが困難となります。
「構造化」にかかる膨大なコスト
データを分析可能な状態にするには、一つ一つの応対記録に対して「これは機能不全」「これはUIへの不満」といったタグ(分類ラベル)を付ける「構造化」の作業が必要です。
しかし、これを手作業で行うには、膨大な工数がかかります。
そのため、分析のために専用の分析システムを導入しようとすると、要件定義や予算確保に数ヶ月〜数年かかることも珍しくありません。
結局、日々の業務に追われ、「いつか時間ができたらやろう」と後回しにされてしまうのです。
「とりあえず保管」という思考停止
多くの現場では、CRM(顧客管理システム)やExcelへの入力が「業務報告」としての役割しか果たしていません。
「何件対応したか」という件数の集計はできても、「どのような問い合わせが多いのか」「なぜその問い合わせが起きているのか」というインサイトまで踏み込んだ分析は、個々の担当者の記憶や直感に頼らざるを得ないのが実情です。
結果として、特定部署だけが把握している「深刻な不満」が、全社的な改善案として吸い上げられないという機会損失が発生しています。
これらの障壁は、これまでは「地道な手作業」か「高額な投資」でしか乗り越えられないものでした。
しかし、次章で解説するように、生成AIはこの「バラバラで不揃いなデータ」をそのままの形で受け入れ、価値ある情報へと変換してくれます。
生成AIがもたらす「分析」のパラダイムシフト
次に、生成AIがどのようにして前章で挙げた「バラバラなデータ」の壁を打ち破るのかを解説します。
これまでのデータ分析といえば、「文章の中に『動かない』『エラー』という言葉があれば、一律で『不具合』にカウントする」というように、あらかじめ決められたルールに基づいて機械的に処理する「統計的な手法」が主流でした。
しかし、生成AIの登場により、カスタマーセンターに眠る「生の文章(非構造化データ)」の扱い方は変わりました。
生成AIが分析プロセスにもたらす変革には、主に3つのポイントがあります。
「文脈」を理解し、表記ゆれを飲み込む
生成AIの最大の特徴は、言葉の「意味」や「文脈」を理解できることです。
従来のシステムでは「ログインできない」と「サインイン不可」は別物として扱われ、人間が事前に「これらは同じ意味である」と定義する必要がありました。
しかし生成AIは、文言が違っても「接続に関するトラブルである」と柔軟に解釈します。
これにより、担当者ごとに書き方がバラバラなExcelデータであっても、事前の整理なしにそのまま分析にかけることが可能になりました。
膨大なテキストを「一瞬で要約・分類」する
数千件、数万件におよぶ応対記録を人間が読み込むには、膨大な時間と精神的なエネルギーを要します。
生成AIを使えば、それらの記録を瞬時にスキャンし、「何についての不満が多いのか」を重要度順にリストアップしたり、ポジティブ・ネガティブといった「感情分析」を自動で行ったりすることができます。
「なんとなく操作性が悪いという声が多い気がする」という現場の肌感覚を、具体的な根拠へと変換することができます。
「仮説」を一緒に立てるパートナーになる
生成AIは単に分類するだけではありません。
「最近、Aという製品で『使いにくい』という声が増えているようだけど、具体的にどの操作ステップでつまずいているか分析して」 といった問いかけに対し、AIは膨大な記録の中から共通のボトルネックを探し出し、改善案のヒントを提示してくれます。
分析の専門知識がなくても、対話を通じて「顧客の不満の核心」にあたりをつけることができます。
表計算ソフトで簡易的に分析する
では実際に、生成AIを使って具体的にどのように分析を進めていくのか、そのステップを詳しく見ていきましょう。
まずは、表計算ソフトであるGoogleスプレッドシートやExcelに搭載されている生成AIを活用することで、VOCを簡易的に分析する方法を解説します。なお、この方法は、Googleのサブスクリプションに契約することで利用することができます。
前述したように、生成AIは文章の意味を読み解いて分類することはできますが、「どの列が日付で、どの列が顧客の声か」という構造がバラバラだと、情報の紐付けを間違えてしまいます。
特に、データ量が膨大になってくると、生成AIが全ての情報を等しく処理しようとして膨大な計算リソースを消費し、結果として分析の焦点がぼやけたり、処理が途中で止まるエラーを引き起こしたりする可能性があります。
そこで、表計算ソフトに担当者が記入する際、生成AIが分析しやすいデータ構造に整える必要があります。
具体的には、1行目(ヘッダー)に、以下のように項目を分け、これに沿って入力してもらうようにします。
| 項目名 | 生成AIにとっての役割 |
|---|---|
| ID | 各問い合わせを識別するための背番号。重複を防ぎます。 |
| Date Time | 発生時期の特定。アップデート前後などの「傾向の変化」を分析するのに不可欠です。 |
| Customer ID | 特定の顧客が何度も不満を抱いていないか、ロイヤリティへの影響を測ります。 |
| Category | 「操作方法」「不具合」など。生成AIが定量的な集計(グラフ化など)をする際の基準になります。 |
| Agent Name | 担当者ごとの負荷や、対応品質の偏りを分析する指標になります。 |
| Priority | 緊急度の判定。生成AIが「最優先で改善すべき課題」を絞り込む際に参照します。 |
| Description | 最も重要です。 顧客の生の声(VOC)をそのまま入力します。生成AIはこの文章から真の課題を読み取ります。 |
ある程度データが溜まったら、サイドパネルにあるGeminiアイコンをクリックすることで、チャット欄が表示されます。このチャット欄に、直接対話形式で分析を依頼することで、簡易なレポートを生成してくれます。
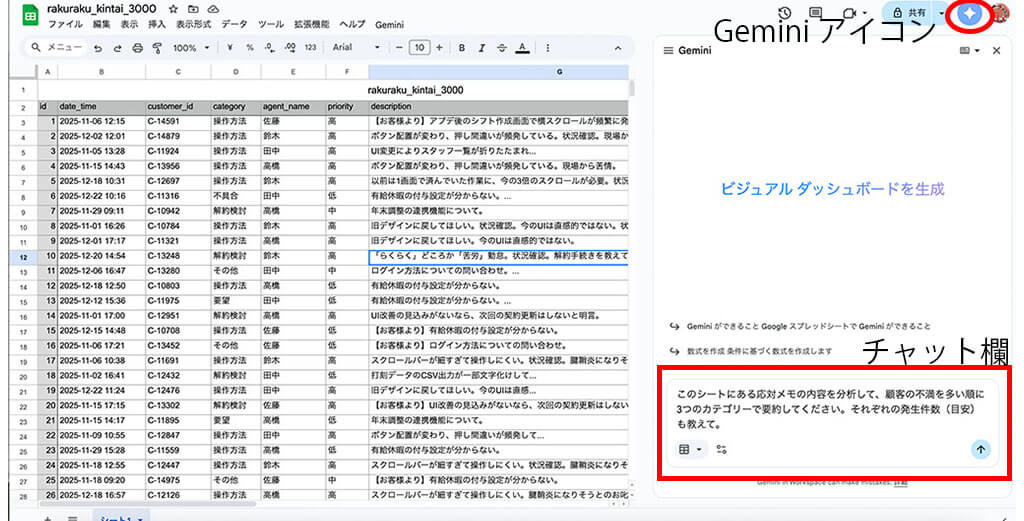
例えば、「このシートにある応対メモを分析して、顧客の不満を多い順に3つのカテゴリーで要約して。それぞれの発生件数も教えて。」と入力すると、表や自然言語で分析結果を示してくれます。
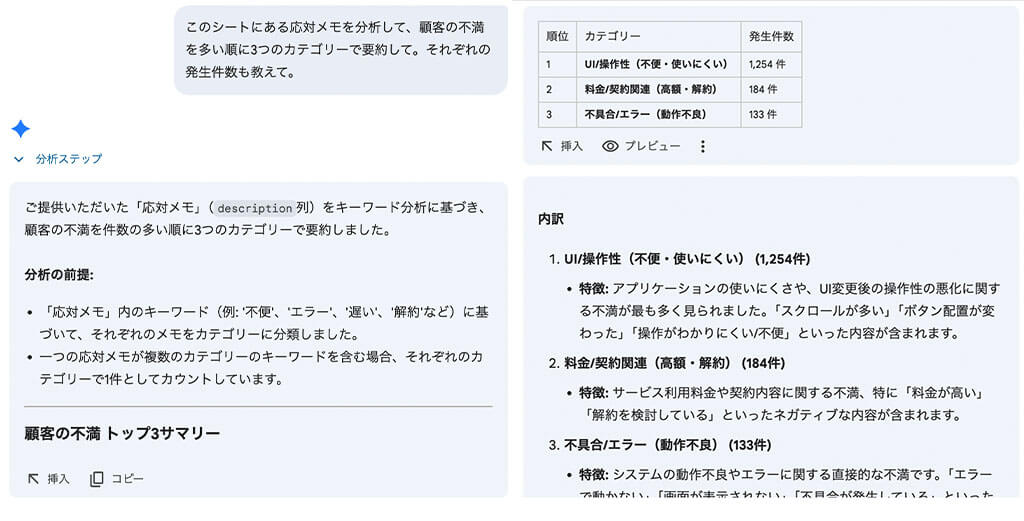
この結果を受け、さらに「1位の不満において、特にどのキーワードに関連する声が一番多いか、さらに細かく内訳を教えて」と指示すると、キーワードごとの内訳を分析してくれます。

ボタンひとつで分析を行なってくれるシステムの構築
次に、ノーコード・ローコードで生成AIアプリケーション開発ができる「Dify」を活用し、ボタンを押すだけで同様の分析を行なってくれるシステムを構築してみます。
Difyでのワークフロー構築
まず、Difyのワークフローを新規作成し、4つのノードを連結させて構築します。

始まりは、「ユーザー入力」ノードから始まり、「BATCH GET」ノードによりGoogleスプレッドシートと連携します。「BATCH GET」ノードは、指定したスプレッドシートの範囲を、生成AIが処理可能なテキスト形式で一括取得します。
取得したデータは「LLM」ノードへと渡され、専門のアナリストとして分析を行ってもらいます。
生成AIがデータを正確に読み解くためには、LLMノードへの「指示書(プロンプト)」設定が重要になります。
具体的には、「BATCH GET」ノードで取得した変数を生成AIが参照できるよう「コンテキスト設定」で紐付けた上で、システムプロンプトに具体的な役割と指示を書き込みます。
[プロンプト内容]あなたはプロのデータアナリストです。
変数 {{text}}に格納された大量の応対記録を読み取り、以下の4つのステップで分析を完結させてください。1. 【全体傾向の要約】
全件の中から「不満」に関連する声を抽出し、「UI・操作性」「不具合」「要望」の3カテゴリで件数(目安)を集計してください。2. 【アップデート影響の特定】
11月のアップデートに関連する「画面の使いにくさ」「スクロール量」「ボタン配置」への不満が、全不満の中でどの程度の割合を占めているか特定してください。3. 【具体的な不満内容の抽出】
特に深刻、または頻出している顧客の生の声を3つ、原文のニュアンスを維持してピックアップしてください。4. 【改善アクション案】
分析結果に基づき、開発チームが来週から着手すべき具体的な製品改善案を2点提案してください。# 制約事項
– 出力はスプレッドシートへの貼り付けを想定し、箇条書きで簡潔にまとめてください。
– 専門用語は避け、現場の担当者が理解しやすい言葉を使ってください。
最後に、生成AIが生成したレポートを「終了(出力)」ノードを通じて、再びGoogleスプレッドシートへと戻される仕組みを構築しています。
Googleスプレッドシートとの連携
なお、上述したDifyのワークフローは、Googleスプレッドシートとの連携によって完成します。
まず、Googleスプレッドシートの内容をDifyに渡すため、Google Apps Script(以下、GAS)を用いた自動起動の設定を行います。
具体的には、Googleスプレッドシートの拡張機能からスクリプトエディタを開き、Difyと通信するためのプログラムを記述します。
なお、このプログラム内には、Difyの管理画面で発行した専用の「APIキー」を組み込んでいます。このAPIキーにより、パスワードのような役割を果たし、外部から安全に自作のAIワークフローを呼び出す「API連携」が確立されます。
次に、スプレッドシート上に図形描画機能を使って「AI分析実行」というボタンを作成し、先ほど作成したスクリプトを割り当てます。これにより、複雑なコード画面を開くことなく、ボタンをクリックすることでDifyへ分析指示が飛ぶようになります。
通信が始まると、GASはGoogleスプレッドシートの内容をDifyに送り、Dify側で生成AIが分析を実行します。
分析が完了すると、生成AIの回答データがGASに送り返されますが、スクリプト内で「〇〇セルに書き込む」という命令を構成しておくことで、分析結果が自動的に指定したセルへ流し込まれます。

この一連の流れにより、担当者がボタンを押すことで、顧客の声を整理した上での改善案を含めたレポートを受け取ることができます。
生成AIを活用する上での注意点
このように、生成AIを活用することで、簡易的な分析をすぐに行うことができます。
ただし、生成AIは万能ではないため、以下の点で注意が必要となります。
個人情報・機密情報の取り扱い
最も注意すべきは、データのセキュリティです。生成AIに読み込ませるVOCの中に、顧客の氏名、電話番号、住所などの個人情報や機密情報が含まれていないかを確認してください。
これはシステム側の設定以前に、「入力する担当者が、最初の段階で個人情報を書き込まない」という意識を持つことが対策となります。
例えば、入力時に「田中様」を「顧客A」に、「090-xxxx」を「電話番号」と置き換えるなど、担当者がその場でマスキングを行うルールを徹底しましょう。
分析に必要なのは「どのような不満や要望があるか」という文脈です。内容に関係のない契約番号や詳細な住所などは、入力の段階で除外するよう運用を整えます。
また、利用する生成AIの規約を確認し、入力データが学習に利用されない設定を選択することも重要です。
ハルシネーションへの理解
生成AIは非常に説得力のある文章を作成しますが、時には事実とは異なる内容を生成することがあります。
そのため、生成AIが算出した「件数」や「特定の事例」が正しいかどうか、最終的には必ず人が確認する工程を設けたほうがいいでしょう。
また、生成AIは「傾向の把握」には非常に強力ですが、厳密な数値の正確性を求める際は注意が必要です。
リソース制限とコストの管理
大量のデータを一度に処理しようとすると、生成AI側の利用制限に達し、エラーが発生することがあります。
そこで、大規模なデータを扱う場合は、100件〜500件単位で分割して実行するワークフローを組むなど、エラーを回避するための工夫が必要です。
また、高性能なモデルを頻繁に利用するとコストが高くなる場合があるため、用途に合わせて軽量なモデルと使い分けるなどの対策を取りましょう。
こうした点に注意し、生成AIをうまくすることで、顧客応対が単なる記録で終わらず、製品開発やサービス品質の向上へと繋げることができるでしょう。

無料メルマガ会員に登録しませんか?

現在、デジタルをビジネスに取り込むことで生まれる価値について研究中。IoTに関する様々な情報を取材し、皆様にお届けいたします。

















