

昨今の生成AI活用において、社内文書やマニュアルなどの外部知識をAIに参照させて回答させる「RAG(検索拡張生成)」の導入が急速に進んでいます。
しかし、実際にシステムを運用し始めると、「資料を読み込ませているはずなのに、AIが的外れな回答を返す」、あるいは「肝心な情報を見落としている」といった課題に直面することが少なくありません。
検索精度を上げるためには、RAGのナレッジ(知識)となるデータの取り扱い方が重要です。
AI(LLM)には、一度に処理できる情報の量に制約があり、巨大なファイルをそのまま読み込ませることはできません。
そのため、元データをAIが扱いやすい「適切なサイズ」に細かく切り分けるチャンク分割が必要になります。なお、この切り分けられた断片を「チャンク」と呼びます。
また、ドキュメントに与える付帯情報を「メタデータ」と言い、これによりそれぞれのチャンクが「何のデータか」を示します。
このチャンク分割の設計ミスやメタデータの欠如が、RAGの回答精度が上がらない主な要因の一つです。
本稿では、RAG構築の要となる「チャンク分割」と「メタデータ」の仕組みを整理し、ノーコード・ローコードプラットフォーム「Dify」を活用することで、どのように最適化を行うべきか、その具体的な実践手法を解説します。
チャンク分割が実務に与える影響
RAGの構築において、元のドキュメントをどのような単位で分割するかは、単なる技術的な作業ではありません。
これは、システムの「運用コスト」と「回答の信頼性」に直結する重要な設計工程です。
不適切な分割は、ビジネス利用において無視できない以下の2つのリスクを招きます。
トークンコストの最適化と抑制
LLM(大規模言語モデル)のAPI利用料は、一般的に入力・出力される「トークン量」に応じた従量課金制です。
RAGの仕組みでは、質問に関連すると判断されたチャンクがAIへの入力(コンテキスト)として送られます。
もし1つのチャンクが不必要に大きい場合、回答に不要な情報までAIに読み込ませることになり、一回あたりの実行コストを押し上げます。
適切なサイズでチャンクを切り出すことは、必要な情報だけをピンポイントで特定し、無駄なトークン消費を抑えるというコスト管理の側面を持っています。
回答精度の維持と「ノイズ」の排除
チャンクのサイズ設計は、AIの理解力に直接影響を与えます。
ここでは「大きすぎる場合」と「小さすぎる場合」の二極化するリスクを考慮しなければなりません。
| チャンクサイズ | メリット | リスク・デメリット |
|---|---|---|
| 大きすぎる場合 | 文脈(コンテキスト)が豊富に含まれ、情報の欠落が少ない。 | 質問に関係のない「ノイズ」が混入しやすく、AIが正解を見失う原因になる。 |
| 小さすぎる場合 | 検索のヒット率が上がり、特定の数値を抽出する際などに有利。 | 前後の文脈が分断され、AIが「何についての記述か」を判断できず、誤答を招く。 |
実務においては、単に「全資料を100文字ずつ区切る」といった一律の処理では不十分です。
例えば、複雑な条件分岐がある就業規則なら、一文が長くなるため大きめのチャンクになり、一問一答形式のFAQ集なら、小さなチャンクの方が検索精度は向上します。
このように、対象となるドキュメントの性質に合わせて「意味のまとまり」を維持しつつ、最適なサイズを探るプロセスこそが、RAG運用における実務的な最適化の核心と言えます。
実務シーンにおけるチャンク分割
チャンク分割の重要性を理解するために、具体的な実務シーンを想定してみます。
今回、構築の対象とするのは「社内規定・操作マニュアル回答Bot」です。
直面している課題
社内資料において、多くの企業が直面している課題は、「作成すること」が目的化してしまい、いざ必要な時に情報にたどり着けないというものです。
例えば、就業規則、経費精算ルール、システム操作マニュアルなど、関連資料が100ページを超えるPDFとして存在している場合、従来のキーワード検索ではヒット数が多すぎたり、文脈が異なる箇所がヒットしたりして、回答にたどり着くまでに時間がかかってしまいます。
結局、「どこに何が書いてあるか」を探す手間がかかったり、知っている特定の担当者に問い合わせが集中したりして、組織全体の生産性が下がる可能性があります。
構築の目的とゴール
今回のケーススタディのゴールは、これらの膨大なドキュメントをRAGのナレッジとして取り込み、「特定のルールを数秒で引用・回答する仕組み」を構築することです。
ここでAIに期待される役割は、単に「要約」することではありません。「第○条のこの記述に基づくと、あなたのケースはこうなります」という、根拠に基づいた正確な回答です。
チャンク分割とメタデータが成否を分けるポイント
このマニュアルFAQシステムにおいて、実用性の分岐点となるのは、以下の3つの要素をいかに制御できるかです。
判断に必要な情報の「欠落」を防ぐ
本来なら「原則としてAだが、例外としてBである」という一セットの情報であるはずが、不適切な分割によって「例外B」の記述が漏れているケースです。この場合、AIは例外ケースを無視した回答を出力する可能性が高まります。
チャンク分割により、セットにすべき情報をひとまとめにします。
「見出し」と「内容」の紐付けを維持する
AIが正確に回答するためには、その情報が「何についての記述か」という見出し情報をセットで把握する必要があります。
しかし、一般的にAIツールで資料を読み込む際は「500文字ごとに区切る」といった、物理的な文字数による機械的な分割が行われます。
そのため、この「文字数による区切り」が、ちょうど「見出し」と「内容」の中間地点で発生してしまうと、情報の紐付けが解消されてしまうリスクがあります。
例えば、「第3条:出張手当の支給額」という見出しと、その具体的な「金額」の記述が離れた位置にある場合、文字数だけで機械的に分割されると、AIの手元には「3,000円」という数字だけの断片が届くことになります。
その結果、AIは「どの規定に基づいた数字なのか」を特定できず、情報の出所(根拠)を正しく示せなくなったり、別の項目の数字と誤認したりする原因になります。
そのため、見出しと内容を紐つける必要があります。
「メタデータ」による回答根拠の明示
ビジネスでAIを運用するためには、AIが出力した回答の根拠として「どの資料の、何ページに書いてあるか」というソースを示す必要があります。
ここで重要になるのが「メタデータ」です。メタデータとは、ドキュメント単位で設定される「属性情報」のことで、分割された各チャンクにもその情報が保持されます。
例えば、以下のような情報をドキュメントに付与します。
出典情報: ファイル名やID
更新日時: その情報がいつ時点のものか
カテゴリー: どのカテゴリーに属するドキュメントなのか
ドキュメント自体にこれらの情報を付与しておくことで、分割された一つひとつのチャンクに対してAIが「これはいつの、何の資料か」を正確に把握した状態になります。
その結果、AIは回答に「『経費精算規定』の第7条に基づくと……」といったソース(出典)を明示してくれます。
さらに、メタデータを付与しておくと検索時に「フィルタリング(絞り込み)」することができます。
例えば、「最新の資料だけを対象にする」といった条件を指定することで、古い規定に基づく誤回答を物理的に防ぐことができます。
このように、ドキュメントに適切なメタデータを付与しておくことで、ナレッジが増え続けても、AIが「正しく、最新で、適切な」情報にアクセスできるようになります。
実践:Difyを活用した社内マニュアルFAQシステムの構築
次に、チャンクを実際にどのように作るのか、Difyのナレッジ機能を活用して、社内マニュアルFAQシステムを構築してみます。
なお、Difyとは、LLMを活用し、ノーコード・ローコードでAIアプリケーションを構築・運用するためのオープンソースのプラットフォームです。
Difyのナレッジ機能の概要
Difyのナレッジ機能とは、PDFやテキストファイルなどの資料をAIが参照できる形式に変換して保存する機能です。
このナレッジ機能には、AIに情報を正しく理解させるための設定項目がいくつかあります。
今回は、チャンク分割に関わる二つの設定項目を解説します。
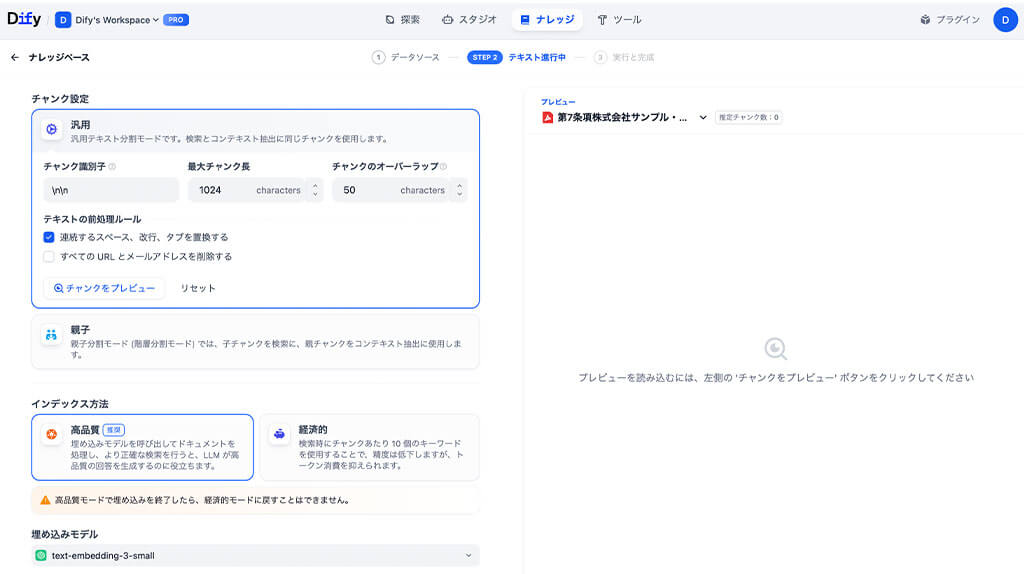
文章を読みやすく切り分ける「チャンク設定」
チャンク設定には、汎用モードと親子分割モードの2つのモードがあります。
汎用モードは、単純に文字数で機械的にページを切り分ける標準的な方法です。
親子分割モードは、「AIが読み込む詳しい本文(親)」と、それを見つけ出すための「検索用の目印(子)」をセットにする分割方法です。
システムは実際に「子」の方を検索し、ヒットした結果として文脈が保たれた「親」の文章をAIに渡します。
例えば、前後の文脈が重要な議事録などの場合、キーワードや短い要約が書かれている「子」で検索をかけ、前後の発言を全て含む長い「親」をAIに渡すという設計にすることができます。
この仕組みにより、ユーザーが話し言葉や短い単語で質問しても、AIが的確な本来の詳しいルールや文脈を見つけ出すことができ、的外れではない正確な答えを作れるようになります。
また、子を編集しても親の文章には影響しないため、運用しながら「子チャンク」だけを編集して、検索に引っかかりやすくするチューニングを行うことも可能です。
AIの探し方を決める「インデックスモード」
「インデックスモード」では、 AIが情報を見つけ出すための「検索の賢さ」を選びます。
高品質モードでは、質問の「意味」や「ニュアンス」を理解して関連する情報を探すモードです。言葉の表現が少し違っても正解を見つけてくれます。
経済的モードでは、本の巻末にある「索引」のように、質問と同じキーワードが書かれている場所をシンプルに探すモードです。
これらをうまく組み合わせることで、「手持ちの資料について、的外れな回答をせず、正確に答えてくれる賢いAI」を作ることができます。
ナレッジ機能を活用したシステム構築
では実際に、Difyのナレッジ機能を活用して、社内マニュアルFAQシステムを構築してみます。
今回読み込ませたのは、出張手当の定義や、地域ごとの宿泊費上限、長期出張時の減額規定、タクシー利用の制限といった、全7条のルールが記されている「経費精算規定」です。
チャンク分割
初期検証では、一定の文字数で機械的に区切る「汎用モード」を採用しました。
しかし、見出しと具体的な手当額が別々のチャンクに分断される「泣き別れ」が発生し、情報の文脈が失われる結果となりました。
チャンクサイズに制限をかける最大チャンク長を変えたり、チャンクの区切る文字を指定する区切り文字を変えたりしても、この泣き別れは解消されませんでした。
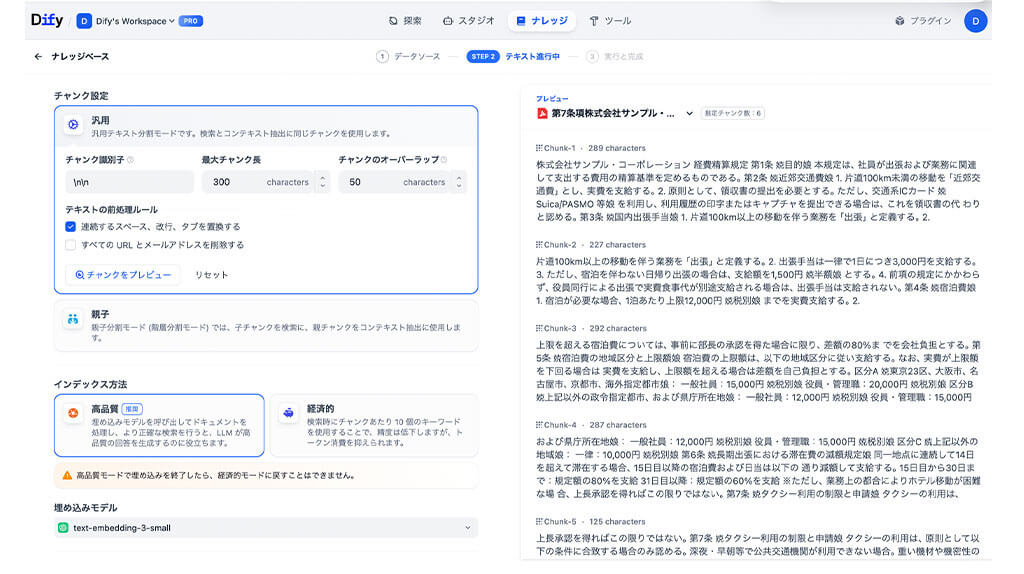
そこで、親子分割モードを活用し、検索用の「子」と回答用の「親」を分ける自動設定を試行しました。
しかし、複雑な箇条書きにおいては、一塊となってほしい内容が別々の子チャンクへ解体されてしまい、文脈の破壊を完全に防ぐことはできませんでした。
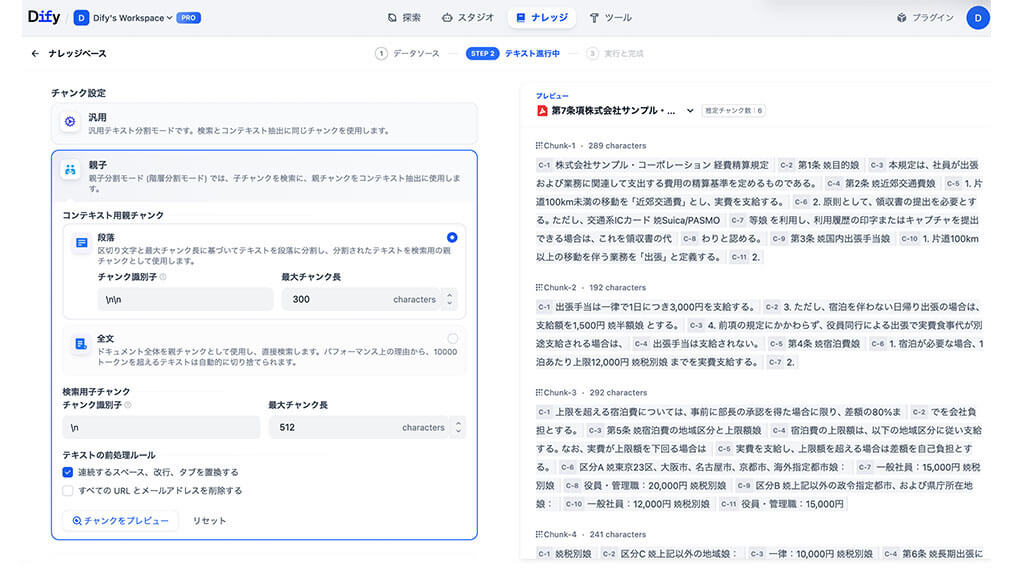
最終的にはインデックス画面上で「全ての条項を独立した親チャンクとして再定義する」という手作業を実施しました。
第1条から第7条まで一文ずつ目視で確認し、「1条=1親チャンク」として、条項の内容を一つづつ子チャンクとして設定しました。
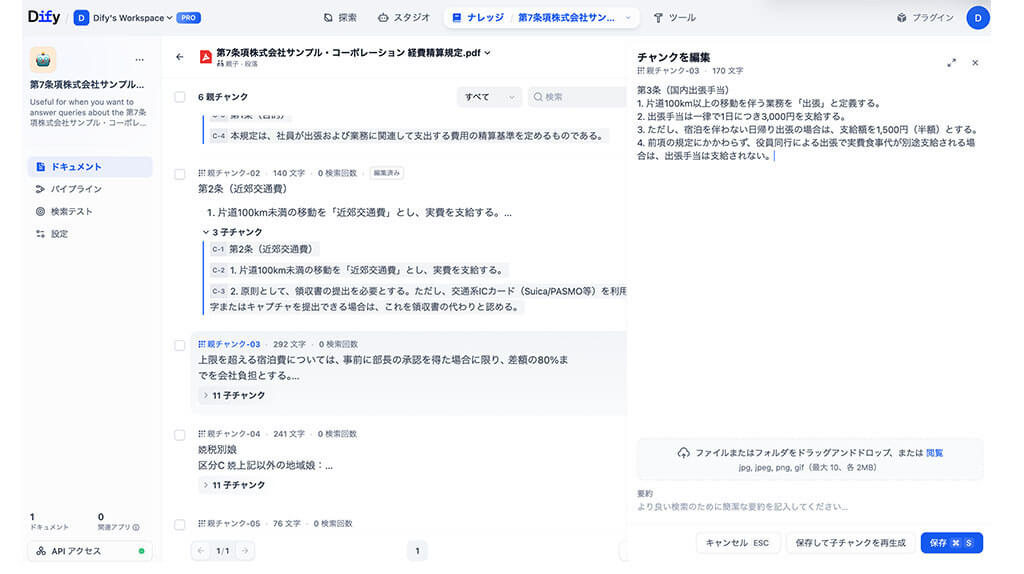
メタデータの付与
次に、今回読み込ませたドキュメントに対し、ドキュメントの属性を示す「メタデータ(カテゴリ、文書ID、発行日)」を付与しました。
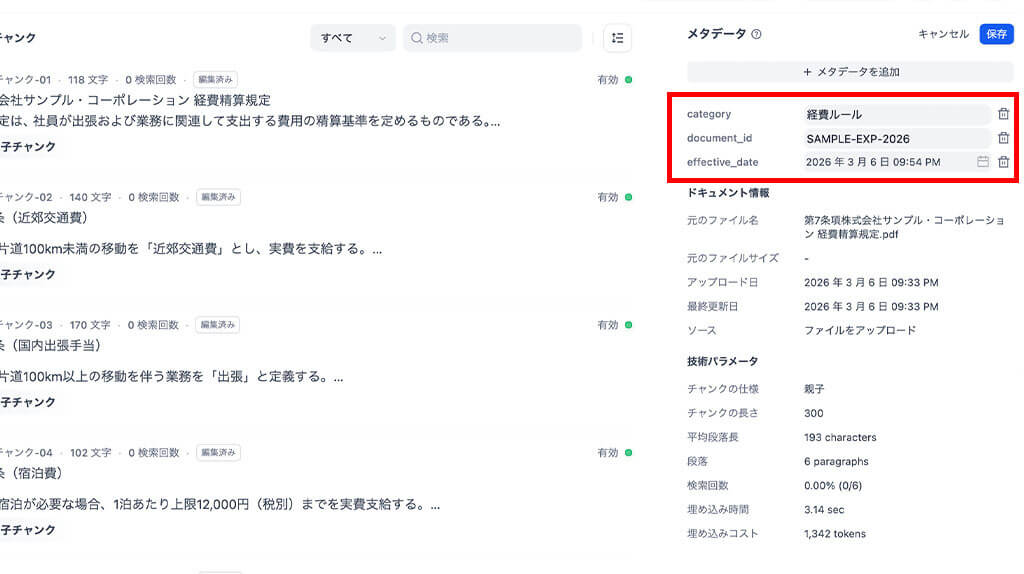
これにより、将来的にナレッジが増えた際、「経費に関する質問には経費ルールのカテゴリだけを検索対象にする」といった絞り込みが可能になるほか、人事規定など、無関係な資料から似たような単語がヒットして誤回答を招くリスクを物理的に排除できます。
また、文書IDを付与することで、資料が改訂された際も、特定のIDを持つチャンクを一括で差し替えるなど、メンテナンスの利便性と正確性が担保されます。
発行日に関しては、「最新の規定のみを対象とする」といった時間軸でのフィルタリングができるようになり、古い規定をナレッジとして残したまま、AIには最新情報だけを参照させるといった柔軟な制御が可能になります。
このように、ドキュメントに適切なメタデータを付与しておくことで、ナレッジの量が増え続けても、AIが「常に最新で、正しいカテゴリの」情報にのみアクセスできる環境を整えることができます。
検索テストによる精度の結果
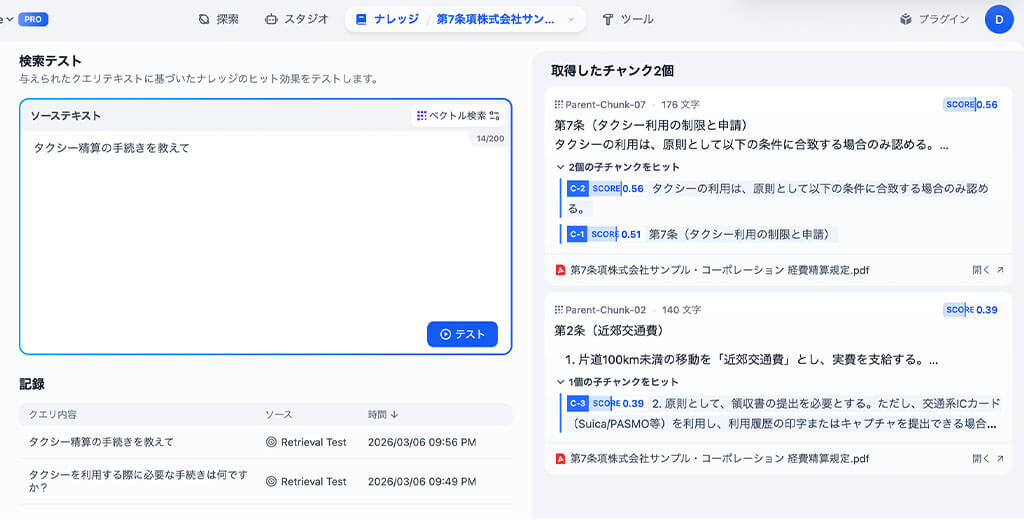
最終的な検索テストとして「タクシー精算の手続き」を質問して検証してみました。
タクシーの精算に関しては、タクシー利用の制限と申請については第7条に、近郊交通費の定義や申請方法については第2条に記載されています。
この別の条項にまたがる2つの情報を、適切に抽出し、「条項」「見出し」「内容」をセットで提示してくれました。
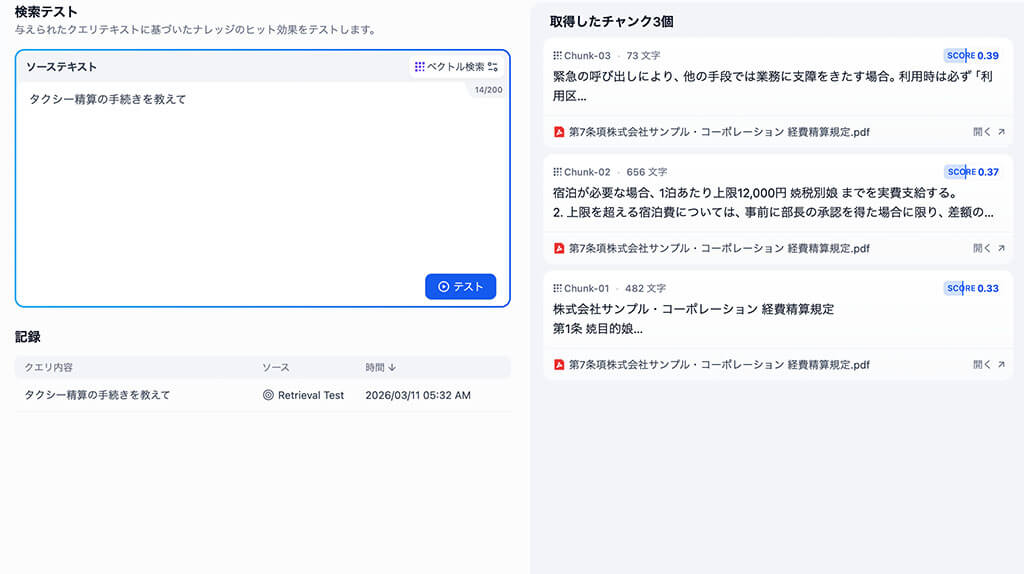
比較するために、全く同じ「経費精算規定」の内容を、汎用モードにて文字数でページを切り分けたチャンク分割の場合でも検索テストをしてみました。
その結果、「タクシー」や「精算」というキーワードを拾って回答をしていますが、前後の関係のない文章も回答結果として提示されたり、何条のルールなのかが明記されていなかったりしました。
まとめ
今回の検証を通じて、Difyのようなツールを使えば「誰でもRAGを作れる」一方で、「精度の高いRAGを作るには、チャンクの概念理解が不可欠である」ことが分かりました。
今回はDifyを使用しましたが、今後別のプラットフォームを利用したり、独自にシステムを構築したりする場合でも、以下の原則は変わりません。
- 意味の最小単位を維持する: 文字数ではなく、情報の意味やまとまりで区切る。
- 文脈を孤立させない: そのチャンクが「何についての記述か」という情報を常に持たせる。
- メタデータで信頼性を補完する: 検索フィルタリングと出典明示のための属性情報を整備する。
AIの回答精度や信頼性は、LLMの性能に加え、「人間がいかにAIが理解しやすい形にデータを整えて渡してあげるか」が重要です。
今回の「チャンク分割」という概念を理解し、データの構造に向き合うことで、実務において真に「使える」AIシステムを構築することができるでしょう。

無料メルマガ会員に登録しませんか?

現在、デジタルをビジネスに取り込むことで生まれる価値について研究中。IoTに関する様々な情報を取材し、皆様にお届けいたします。

















