

株式会社野村総合研究所(以下、NRI)は、特定の業界や業務に特化した大規模言語モデル(LLM)の構築手法を高精度化および効率化させたと発表した。
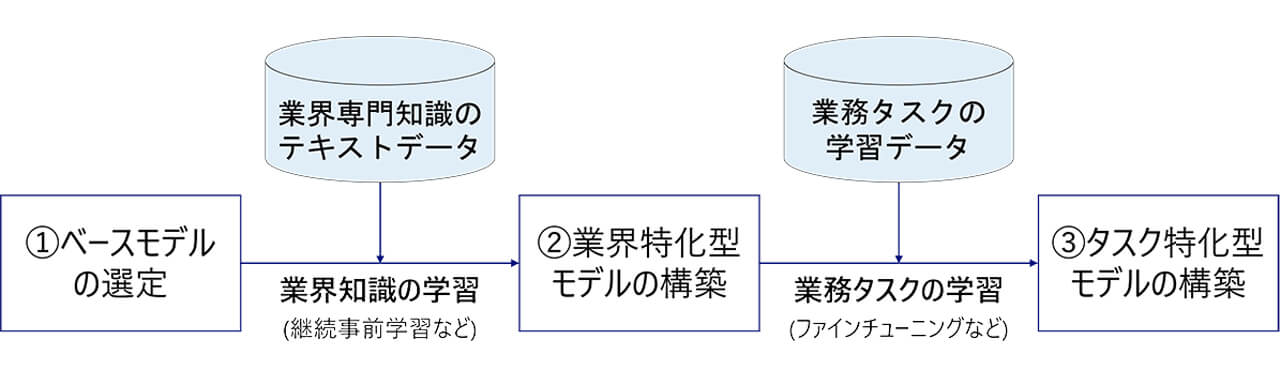
今回開発された構築手法は、一般に公開されている基礎性能の高い中規模LLMを土台とし、業界知識や特定の業務プロセスを効率的に学習させるものだ。
具体的には、業界特化およびタスク特化のための学習データ作成プロセスを自動化する。大量のテキストデータから専門知識を習得させる仕組みに加え、高性能なLLMを用いて業務に即した問答データや学習用データを自動生成する。
これにより、少数の業務サンプルと定義さえあれば、対象業界を問わず低コストで専門性の高い特化型モデルを容易に構築することが可能となった。
さらに、モデルの圧縮技術により、少ない計算資源でも高い精度を維持したまま稼働できる環境を実現している。
NRIは同手法の有効性を確認するため、構築した特化型LLMをAIエージェントの仕組みに組み込み、実際の業務手順を模した環境で検証を実施した。
その結果、証券や保険の「営業会話チェック」および「募集文書校正」といった金融実務タスクにおいて、いずれもOpenAI社の商用大規模モデル「GPT-5.2」を上回る高い正解率を達成した。
これにより、AIが自律的に複数の手順を実行し、担当者の専門的な判断を支援するプロセスの有効性が実証された形だ。
NRIは今後、企業の専門的な業務プロセスをAIで支援するため、業界・タスク特化型モデルを組み込んだAIエージェントの導入・展開を進めていくとしている。
今回確立された構築手法は金融以外の分野にも適用可能であり、多様な業界や業務へと適用範囲を拡大することで、汎用モデルでは対応が難しかった専門領域におけるAIの社会実装を推進していく方針だ。
なお、同取り組みは、経済産業省とNEDOが実施する国内の生成AI開発力強化プロジェクト「GENIAC」第3期の支援を受けたものである。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















