
ディープラーニングは、画像・音声認識などで優れた性能を有し、AI処理のアルゴリズムとしてクラウド上で活用されている。一方で、多層化により認識性能を向上させたディープラーニングモデル(以下、モデル)は、演算量・パラメーター(※1)が多く、大量の演算リソースや電力を必要とする。
車載用途やスマートフォン、組み込みIoTデバイスなど多様なエッジデバイス(※2)が登場する中、限られた演算リソース上でも高性能なモデルを高速・省電力に実行するため、モデルの軽量化技術が求められている。
軽量化技術としては、従来からチャネル(※3)・プルーニング(※4)という手法が提案されていた。これは、モデルの畳み込み層(※5)から冗長なチャネルを削減し、チャネルに関連する演算・パラメーター・メモリーを削減する技術だ。しかし、従来手法は、削減率の設定を層ごとに行う必要があり、手間がかかり、最適な削減にならないという課題があった。

このような中、国立研究開発法人新エネルギー・産業技術総合開発機構(以下、NEDO)と沖電気工業株式会社(以下、OKI)は、NEDO事業で、モデルの精度を維持しつつ演算リソースを削減するモデル軽量化技術の開発を目的としたAIエッジ技術の研究開発テーマを推進してきた。
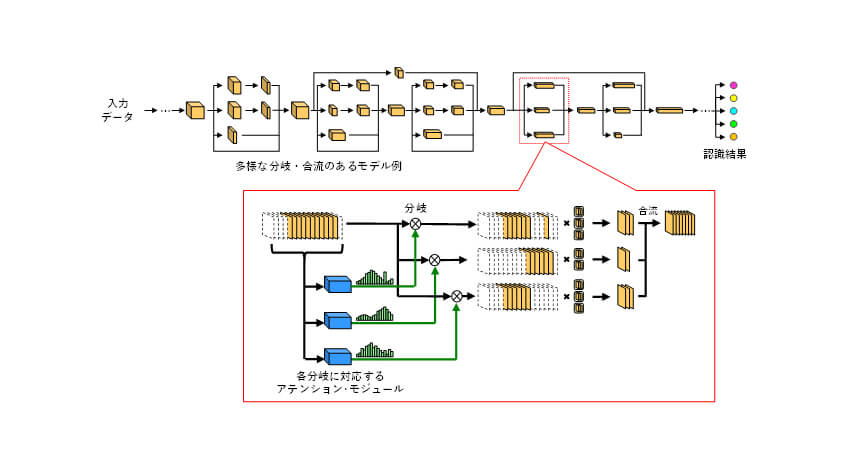
今回、OKI独自のチャネル・プルーニング技術であるPCASを発展させ、新たなモデル軽量化技術を開発した。PCAS技術は、チャネルの重要度推定にアテンション(※6)・モジュールを導入することで、認識性能の維持効果を高めつつ、層単位の削減率設定を不要とした技術だ。層間に挿入したアテンション・モジュールに後段の層への情報伝播を抑制する構造を持たせ、モデル全体の推論誤差を最小化する学習を経て、全体最適による重要度推定を可能にする。

今回開発した軽量化手法は、PCAS技術を発展させた近年の多様な分岐・合流経路を含むモデルに柔軟に対応できるアーキテクチャだ。モデル内の分岐経路では、経路ごとに認識性能に寄与する重要なチャネルが異なるため、その差異を吸収する必要がある。そこで、分岐部では、単一のチャネルに対して複数のアテンション・モジュールを導入することで、複数経路のチャネルの重要度を全体最適で推定する。
さらに、経路ごとに異なるチャネル構成の不一致を整合する仕組みと、学習過程の詳細な分析に基づく誤差伝播(※7)量の制御方法を開発し、多様なモデルに対して認識性能を引き出すことに成功した。
この技術を用いると、演算量の削減により、高速かつ低消費電力でAI処理を実行することができる。測定の結果、ベンチマークとして一般的に用いられる高精度モデルへの適用においては、認識精度劣化を約1%に抑えながら、積和演算回数と処理時間をそれぞれ約80%削減した。
同技術開発により、エッジデバイスなど演算性能や電力消費に制限のある環境への高度なAIの搭載や、サーバー・クラウド環境における高度なAIの小規模・省電力運用などが期待できる。これにより、今後増加が見込まれるIoTアプリケーションへの応用が可能なAI技術の開発が加速され、多様で高度なデータ利活用社会の実現へ貢献する。
NEDOとOKIは今後、今回開発した軽量化技術を低ビット演算環境にも適用し、さらなる高度化と高効率化に取り組むほか、大規模な認識モデルへの適用にも取り組み、高度なAIを軽量かつ省電力に実行できる技術の確立を目指す。
※1 ディープラーニングモデルは、演算用の多数の固定的なパラメーターを持つ。代表的なパラメーターに重み係数がある。重み係数と入力データとの積和演算を行い、その結果を活性化関数で処理して出力することが、ニューラルネットワークの最も基本的な演算となる。
※2 利用者に近いネットワークの末端に位置するコンピューティング機器。クラウドやサーバーなどと比較し、利用できる電力や発熱、演算能力などの制限が厳しい小型の機器。
※3 フィルターとの畳み込み演算の結果を保持するニューロンの集まり。
※4 ニューラルネットワークのなかで冗長なニューロンを削減することで、それに関わる係数や演算を削減する技術。枝刈り技術とも呼ばれる。
※5 CNNとも呼ばれる畳み込み演算を有するニューラルネットワークの構成要素。一つの畳み込み層には複数のチャネルが含まれる。入力データ上に分布する空間的な特徴を保持した演算が可能。
※6 主に画像認識や自然言語認識などで、認識に重要な情報に着目するための手法として開発されてきたニューラルネットワーク技術。
※7 層から層へと誤差を伝播すること。ニューラルネットワークの学習では、出力層における誤差を推論とは逆方向の入力層に向かって伝播し、誤差が小さくなる方向にパラメーターを調整する。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















