
株式会社富士通研究所は、学習に必要な量のデータを取得できない場合にも、高精度な判断が可能な機械学習技術「Wide Learning(ワイドラーニング)」を開発した。
近年、医療やマーケティング、金融などの様々な分野においてAIが導入されはじめ、AIの判断を活用した業務支援や自動化に対する期待が高まっている。しかし、業界や業種によっては、判断したい対象に対してAIの学習に必要な十分な量のデータを取得することが難しく、実用に耐える高い精度が出ないという問題がある。
また、AIが十分に高い精度での認識・分類性能を出したとしても、なぜその答えが出てきたのか専門家や開発者自身も説明できないため、現場で説明責任を果たせずAIの導入が進まない大きな要因となっている。
「Wide Learning」技術の特徴は下記の2点だ。
データ項目を組み合わせて大量の仮説を抽出:
すべてのデータ項目の組合せパターンを仮説とし、各仮説に対し分類ラベルのヒット率で、その仮説の重要度を判断。例えば、商品購入に対しての傾向をAIで分析する際に、これまでの購入者・未購入者(分類ラベル)のデータ項目から、<女性・免許所有> <未婚・20~34歳>などすべてのパターンを組み合わせ、これらを仮説とした際に実際の商品購入者のデータとどれくらいヒットするかを分析する。
このとき一定以上のヒット率の仮説をナレッジチャンクとよび、重要な仮説であると定義。これにより、元々の判断対象となるデータが十分に揃っていない場合でも、注目すべき仮説をもれなく抽出することができ、これまで考えつかなかった仮説の発見にも貢献する。
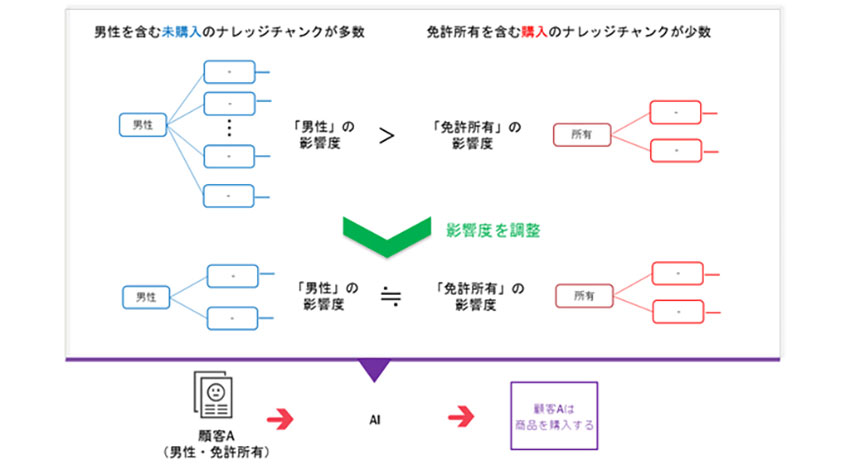
ナレッジチャンクの影響度を調整し高精度な分類モデルを構築:
抽出した複数のナレッジチャンクとラベルに基づき分類モデルを構築。この際に、ナレッジチャンクを構成する項目が他のナレッジチャンクを構成する項目と重複が多い場合に、分類モデルへの影響度を小さくなるように制御する。これにより、ラベルやデータに偏りがある場合にも、高精度な分類が可能なモデルを学習する。
例えば、商品購入データの中で未購入の男性のデータが大多数を占めている場合に、影響度を制御しないで学習すると、性別とは関係なく得られた<免許所有>の項目を含むナレッジチャンクが分類に影響しなくなる。
開発方式では、項目の重複に応じて<男性>が含まれるナレッジチャンクの影響度を抑え、少数である<免許所有>が含まれるナレッジチャンクの影響度が相対的に大きくなるように学習することで、<男性>でも<免許所有>でも正しく分類できるモデルを構築する。
同技術について、デジタルマーケティングや医療などの領域のデータに対して適用し、検証を行ったところ、UC Irvine Machine Learning Repositoryのマーケティングと医療領域のベンチマークデータを用いたテストで、ディープラーニングに比べ正解データを当てる精度が約10~20%向上し、サービスに加入する見込みの高い客や罹患患者を見逃す確率を約20~50%低減することを達成した。
今回、約5,000件の顧客データの中で購入顧客が約230件と正解データが少ないマーケティングのデータを使ったところ、同技術を用いて販促する人を決めると、見込み顧客を販促対象から外す数をディープラーニングの分析結果である120人から74人と減らすことができた。
提供:富士通研究所
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















