
モーションキャプチャとは、人物や機械などの実際の挙動を3次元計測できるシステムのことだ。
一般的にモーションキャプチャを行うためには特殊な装置やスーツが必要で、計測場所や利用シーンが限定されている。
近年では画像認識技術を応用することで特殊な機材を用いずに、カメラ映像だけからモーションキャプチャを行う技術も登場しているが、映像上における人同士の重なり合いによる解析の難しさや、背景が切り抜き易い環境でしか用いることができないといった制約が原因で、屋内・屋外、空間の広さを問わずに複数人の高精度なモーションキャプチャを行う技術は実現されていなかった。
国立大学法人東京大学 大学院情報理工学系研究科 中村仁彦研究室(以下、東京大学・中村研究室)と、株式会社NTTドコモの研究チームは、東京大学・中村研究室の開発したカメラ映像だけからモーションキャプチャを行う技術「VMocap」を応用することで、特殊な装置やスーツを用いずに、広い空間における複数人のモーションキャプチャを行う技術を開発した。
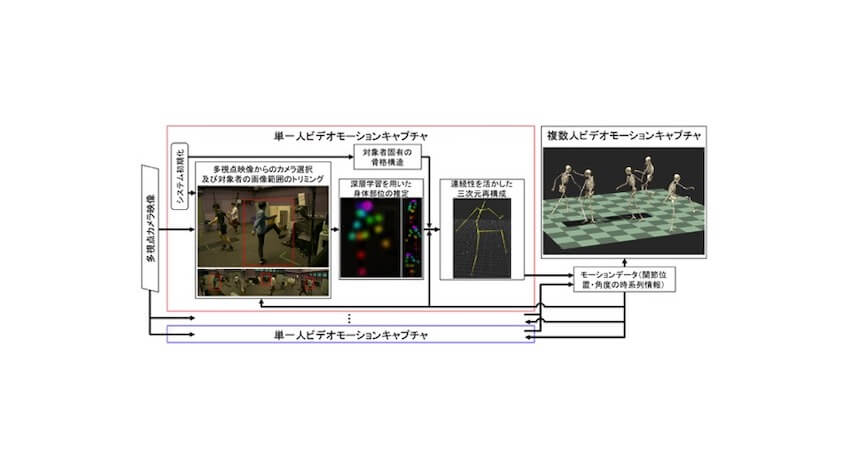
同技術は解析に用いるべき最適な映像を、複数のカメラから自動的に選択して切り替えることで、映像上における各対象の身体部位を推定する。
この推定を複数の視点から行いつつ、骨格構造や運動の連続性に基づくフィルタ処理を施すことで、高精度で滑らかなモーションデータを取得することができる。
取得されたモーションデータは、次時刻の映像選択に用いられ、この一連のループが最終的なモーションキャプチャの性能に好循環をもたらし、広い空間における複数人のモーションキャプチャを可能にする。
また、人同士の身体が映像上で重なって見える状況下でも、人の骨格構造と運動の連続性、画像認識技術を活用することによって運動を推定することができ、フットサルのように複数の選手が激しく動き回るようなシーンでも、高精度で滑らかなモーションデータや骨の動きが取得できることを実証した。
これにより、スポーツの試合やライブ会場など、従来モーションキャプチャが困難だった場所でも手軽にモーションデータを取得し、運動解析や3Dアニメーションの作成ができるようになる。

大学卒業後、メーカーに勤務。生産技術職として新規ラインの立ち上げや、工場内のカイゼン業務に携わる。2019年7月に入社し、製造業を中心としたIoTの可能性について探求中。

















