
株式会社NTTデータ(以下、NTTデータ)は、汎用言語モデルBERT(注1)を特定の業務領域(ドメイン)に応じて最適化し、顧客の扱う業務文書に適した言語モデルを自動で構築するドメイン特化BERT構築フレームワーク(以下ドメイン特化BERT-FW)を開発した。
注1 BERT(Bidirectional Encoder Representations from Transformers)とは、2018年10月にGoogleが発表した自然言語処理モデルであり、自然言語処理分野のさまざまなベンチマークにおいて従来モデルの精度を上回るなど近年非常に注目されている。
本FWの利用により、NTTデータは業界を限定しないさまざまなドメインに特化したBERTを短期間で構築し、顧客に高性能な言語処理サービスを素早く提供できるようになった。
本FWは、専門用語や特有の文脈を含む文書を解析する際に、言語モデル自体を顧客の業務文書に最適化することで従来のBERTと比べて高精度の結果を得ることができる。また、言語モデル構築の一連の流れは自動化されているため、専門家によるチューニングを行う場合と比べて短期間でモデルを構築することが可能。
本FWの適用により、専門用語や特有の文脈への対応が必要だった分野での自然言語処理技術活用の幅が大きく広がることを見込んでいる。2021年4月以降順次、文書を扱う業務の効率化やサービスの高度化を検討している企業を募り、2021年度中に顧客との共同検証の5件実施を目指す。
背景
近年、深層学習をはじめとしたAI技術が目覚ましい進歩を遂げており、自然言語処理技術のビジネス適用も進んでいる。
BERTの活用も盛んに試行されていますが、実ビジネスで取り扱う文書では業界特有の専門性の高い用語や言い回しが多く、これらの要因により十分な精度が得られないことが課題となっていた。
これに対して、NTTデータでは金融業界文書に特化した金融版BERT(注2)を開発し、2020年7月より実施している金融業界向けの自然言語処理の実証実験において活用している。こうした業界特化の言語モデルは金融業界以外の顧客においても高いニーズがある。それらに迅速に応えるため、顧客の業務データごとに適した追加学習データを自動収集する仕組みであるドメイン特化BERT-FWを開発した。
特徴
ドメイン特化BERT-FWは、汎用言語モデルであるBERTに追加学習を行い、顧客の業務文書に合わせて最適な言語モデルを構築する仕組みだ。
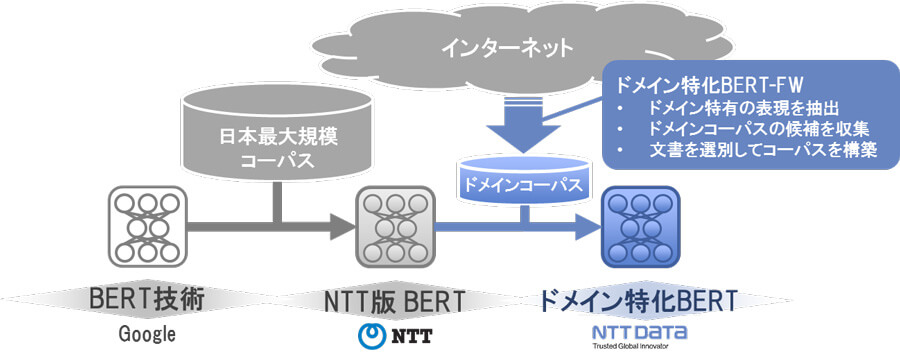
従前から、一般的なBERTに追加学習を行い業界特有の知識を学習した言語モデルを作成するアプローチは一定の成果を上げていた。一方で、自然言語処理を適用する業務によっては事前に「業界」の範囲を適切に定義することが難しいことが課題となっている。これに対して本FWでは、対象とする業務文書ごとに最適なデータを収集して追加学習を行うことにより解決を図っている。
本FWでは、処理対象の業務文書から学習前の一般的なBERTモデルによる扱いが難しい文章を効率的に選別する。主に専門用語を含む文を対象に類似した文章をインターネットから収集し、追加学習することで特定ドメインに特化した言語モデルを構築する。これにより、業界を限定せずに顧客の業務ごとに最適化された言語モデルを提供できるようになった。この一連の流れを自動化することで、迅速に言語モデルを構築し、一般的なBERTモデルを上回る精度を実現する。

性能
ドメイン特化BERTモデルの性能を評価するため、金融系資格試験に解答するタスクで検証を行った。汎用モデルであるNTT版BERT(注3)およびNTTデータが2020年7月に構築した金融版BERTモデルと比べて、ドメイン特化BERT-FWで構築したモデルは高精度であることが確認できた。
検証:金融系資格試験における得点比較
金融知識を求められる課題として、教材制作会社作成の一種外務員資格試験(注4)の模擬試験(注5)にする試験回答AIを開発し、各モデルによる得点を比較

モデル構築の期間短縮効果
本FWの活用により、顧客の業務に最適化されたモデルを作成する際の期間を大幅に短縮することができる。例えば、検証1向けのモデル作成でのモデル構築に要した期間について、金融版BERTモデルでは構築期間が29日であったのに対し、ドメイン特化BERT-FWを用いたモデルは8日で構築することができた(図2)。また、自動化による副次効果として、業務有識者(顧客等)の作業は不要となった。
ドメイン特化BERT-FWは自然言語処理技術の短期間での業務適用や細かなタスクごとに並行した複数のモデル構築を実現する。

注釈
注2NTTデータが開発した金融分野に特化したBERTモデル。
https://www.nttdata.com/jp/ja/news/release/2020/071000/注3NTT版BERTは日本最大規模のコーパス(日本語Wikipediaに加えニュースサイトやブログより収集(12.7GB))で学習させたBERTモデル。
注4金融商品取引法上の登録外務員として、金融商品を取り扱う者の資質確認のため日本証券業協会が実施する資格試験。金融商品取引業に関する法令・諸規則の知識等が問われます。
注5「うかる!証券外務員一種2018-2019 必修問題集 フィナンシャルバンクインスティチュート編 日本経済新聞出版」の模擬試験部分を利用。
文章中の品名、会社名、団体名は、各社の商標または登録商標です。

無料メルマガ会員に登録しませんか?
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















