

2016年4月4~7日に米国サンノゼコンベンションセンターで開催されたエヌビディア主催 GPU Technology Conference(GTC) 2016 で発表されたディープラーニング関連の情報を、日本で発表するための「NVIDIA Deep Learning Day 2016 Spring」が先日ベルサール高田馬場で開催された。
その中で行われた「GTC リピートセッション」では3人が登壇し、まず中部大学工学部 情報工学科 講師 山下隆義氏より、「Heterogeneous Learning for Multi-task Facial Analysis Using Single Deep Convolutional Network」について発表があった。
Heterogeneous Learning for Multi-task Facial Analysis Using Single Deep Convolutional Network

山下氏はMachine Perception and Robotics Groupという研究グループで、機械知覚とロボティクスのテーマを掲げ研究・開発をしている。
機械知覚テーマではディープラーニング、SVN(support vector machine)などの機械学習による画像認識を研究開発しており、ロボティクステーマでは産業・生活支援ロボットのための画像認識の研究をしているという。
その山下氏より、ディープラーニングについての話があった。
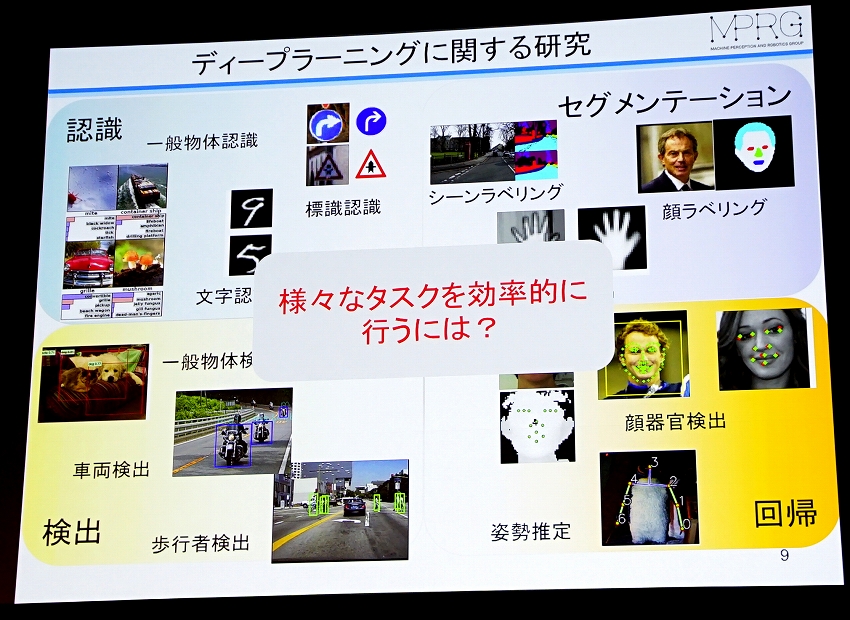
ディープラーニングは「認識」「検出」「セグメンテーション」「回帰」と大きく4つの分野に分かれ、それぞれのタスクに対して独立したネットワークを学習を行うという方法になっているが、様々なタスクを効率的に学習するにはどうしたらいいかということを研究・開発しているそうだ。
それを山下氏らは「ヘテロジニアスラーニング」と呼び、例えば先ほどの「認識」と「回帰」という別々の問題をひとつのネットワークで行うものだという。
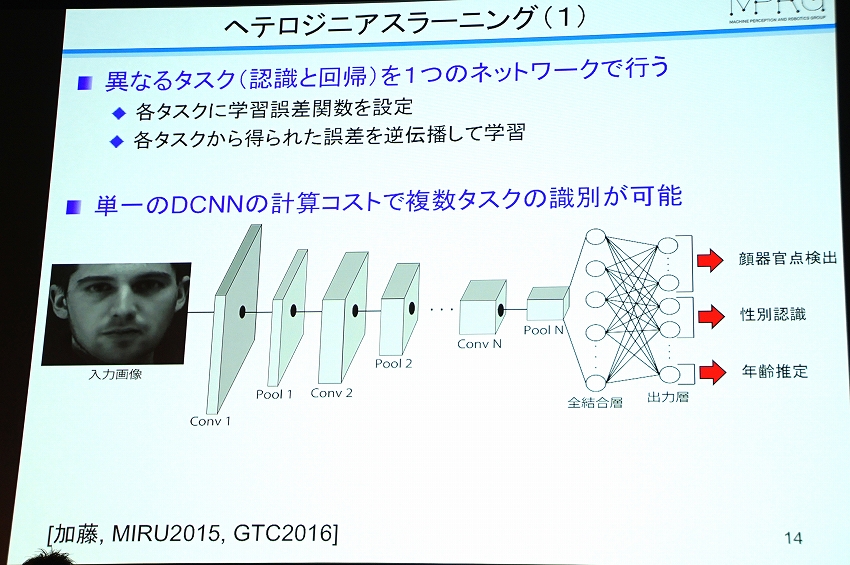
例えば、顔の画像を入力すると、顔の器官点、性別、年齢などを同時にひとつのネットワークで出力する。しかし、別々のタスクを同時に行うとうまく学習ができないという問題が起こる。
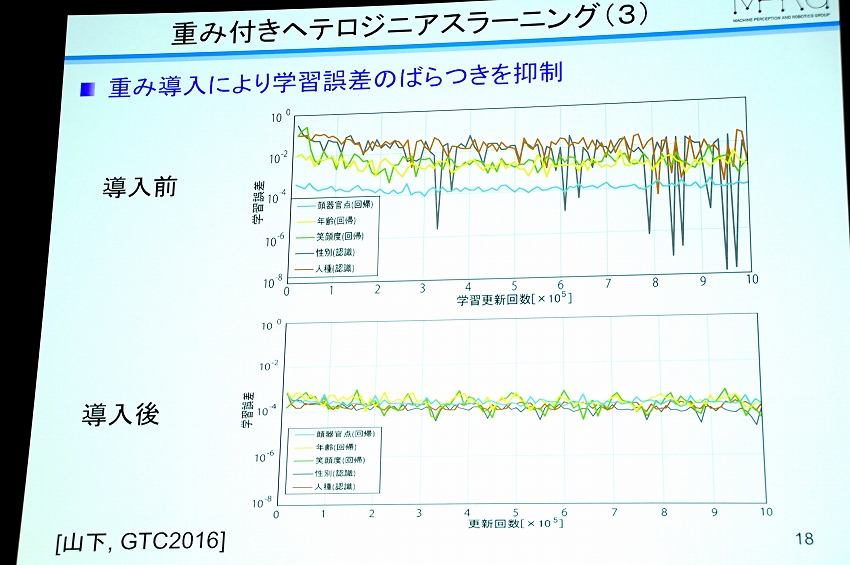
学習時にうまくいくものもあったり、いかないものもあったり、タスク時にばらつきが出るが、それをばらつきがでないようにするために、学習誤差のばらつきを抑制するタスク重みを導入したそうだ。
重み付けの方法は、単一タスクを個別に事前学習し、それぞれの学習誤差を見ながら「どれが一番誤差が小さいか」を探し、誤差が小さいものをメインのタスクにするという。
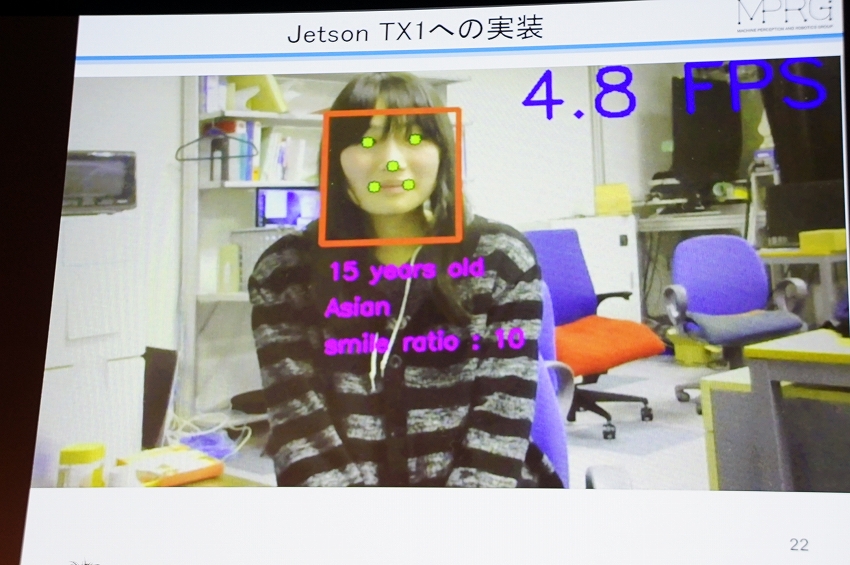
この方法をNVIDIA製品の JETSON TX1に実装し、その結果としては下記写真のように、年齢や国籍、笑顔のスコアが表示される。
この技術は顔の推定だけではなく汎用性があり、歩行者の検出と部位推定をすることができる。その実験結果としては、従来手法よりも誤検出が少なく、従来と同じ誤検出率だったとしてもミスレートが低かったそうだ。
今後広がる可能性がある自動運転を例にあげ、ブレーキをかけるとしても、歩行者がこちらを向いている場合と向いていない場合で、ブレーキのかけ方も変わってくるため、そういった場合の制御もできるという。
Capitalico – Chart Pattern Matching in Financial Trading Using RNN

続いて、Alpaca Chief Engineering Officer林 佑樹氏より発表があった。
Alpaca は日本とシリコンバレーに拠点があるスタートアップで、フィンテックでのサービス開発を進めている会社だ。今回は「キャピタリコ」というサービスと、その後ろで使われているディープラーニングの技術の発表があった。
「キャピタリコ」は、FXなどのチャートを見て投資の判断をしポジションを取って利益を上げていく、というテクニカルトレーダーをサポートするためのツールだ。このサービスは2015年のGTCで発表し、ユーザーの声を聞きながら改良を重ねている。
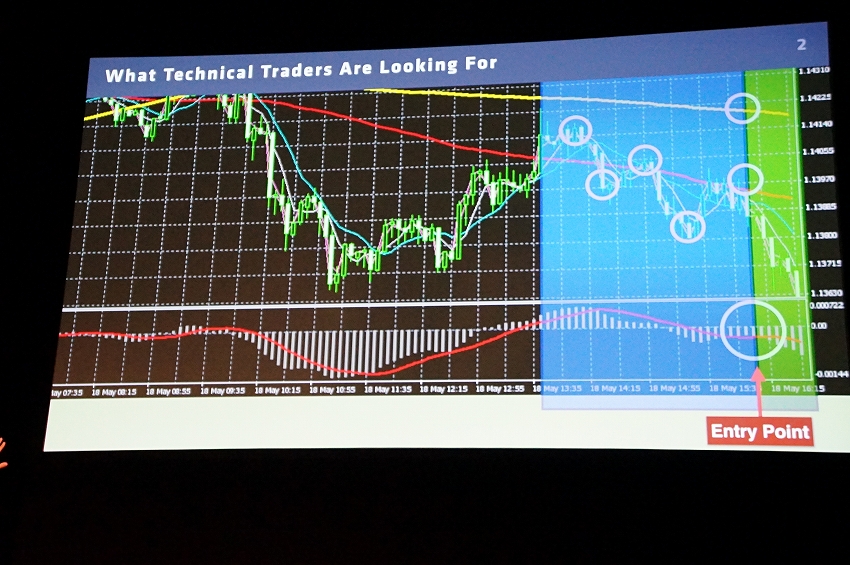
例えば上記図でいうと、水色の部分のような特徴が現れこのようなパターンが続くと、このあとは値段が落ちる傾向になる典型的なダウントレンドのチャートだという。
この分野は長年研究されているが、なかなか成果も出ていない分野でもあるというが、同社は時系列の波形データから特徴を抽出したそうだ。ユーザーがチャート上でどこに着目しているか、という情報をニューラルネットワークに与えれば、あとは「いい感じにまとめてくれる(林氏)」という。

ネットワークはLSTMを利用、凝った構造の作りではなく非常にオーソドックスになっているが、上記図の「Training」や「Data」は試行錯誤を重ね、とても苦労したという。
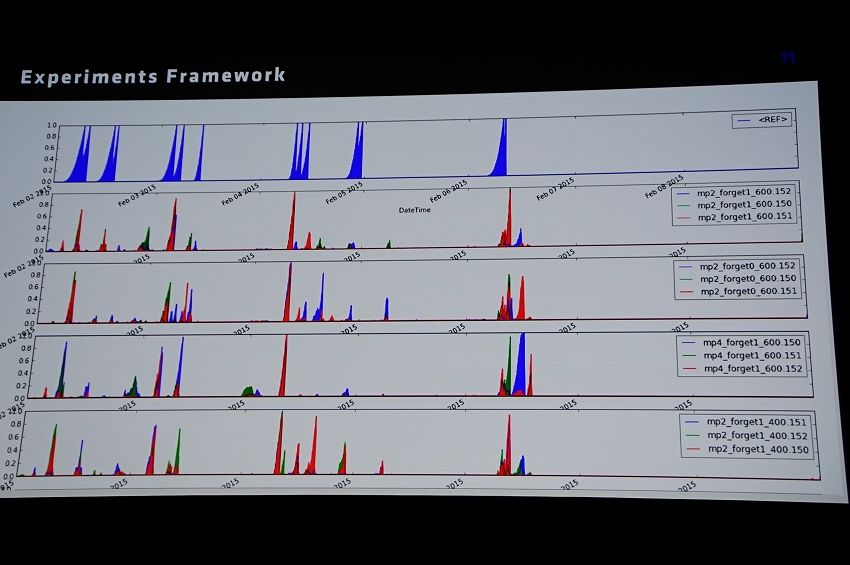
上記図の一番上の青い部分は人がラベルをつけたもので、下の4つは異なるコンフィギレーションでトレーニングされたモデルの反応結果だが、大きく外れていないという例だ。
ディープラーニングは多くの学習データがあって成り立つケースが多いが、同社の場合はチャート上からユーザーにレンジを選んでもらうので、その際に「何千も選んでください」というのはサービスと成り立たない。よって数個から数十個のサンプルで効率的に学習できる仕組みを作ることがポイントだったそうだ。
Chainer: A Powerful, Flexible, and Intuitive Deep Learning Framework

最後に株式会社Preferred Networks 取締役副社長 岡野原大輔氏の発表があった。
同社は、IoTにフォーカスしたリアルタイム機械学習技術のビジネス活用を目的とした企業でChainer(チェイナー)という、ディープラーニングを作るためのフレームワークを提供している。
まず、同社が今年ラスベガスで行われたCESで発表したという、トヨタ自動車と共同展示したデモンストレーションの話があった。

写真の白いクルマは自動運転で制御されており、あやしい挙動をしている赤いクルマが岡野原氏がラジコンで操縦しているクルマだ。
自動運転車は全て強化学習を使っており、人間がどのように運転しているのか教えずに、機械が自動的に学習しているということだった。
「複雑な状況をどのように表現すればクルマにとって最適なのか」、「データをどのように表現するのか」が今まで問題になっていたが、このデモンストレーションでは、全てのクルマが取るセンサーは生データとなっており、それをディープラーニングし、どのように組み合わせて制御すれば将来ぶつからないか、というのを予測して動いているという。

次に、国際ロボット展2015でファナックと共同展示をした「学習によるロボットの制御」の話があった。これはバラ積みされた円柱の取りだしを0から自動的に学習するというものだ。
これは、ヒトにとっては簡単だが、機械には難しいという典型的な作業だそうだ。どういう場合に取れるのか取れないのかといったことを掛け合わせるのが難しいというが、このデモでは8時間の学習で、ヒトがチューニングした内容と同様の結果が出たそうだ。
これまでのPythonのフレームワークはTheanoと呼ばれるライブラリを使っていたが、オープンソースChainerでは使っていない。
その理由はこれまでのディープラーニングのフレームワークよりもフレキシブルに、自由にディープラーニングのネットワークを定義できるようにしたかったからだという。
【関連リンク】
・Machine Perception and Robotics Group
・Alpaca
・PFN(Preferred Networks, inc.)

無料メルマガ会員に登録しませんか?
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















