

IoTとともに話題に上がることが多くなったディープラーニング。様々なシステムにディープラーニングが使用されるようになる中、三菱電機が「ディープラーニングの高速学習アルゴリズム」を開発したとのことで、三菱電機株式会社 情報技術総合研究所 知能情報処理技術 部長 三嶋英俊氏と機械学習技術グループマネージャー 松本渉氏にお話を伺った。
─早速ですが今回発表されたディープラーニング高速化アルゴリズムについて教えてください。
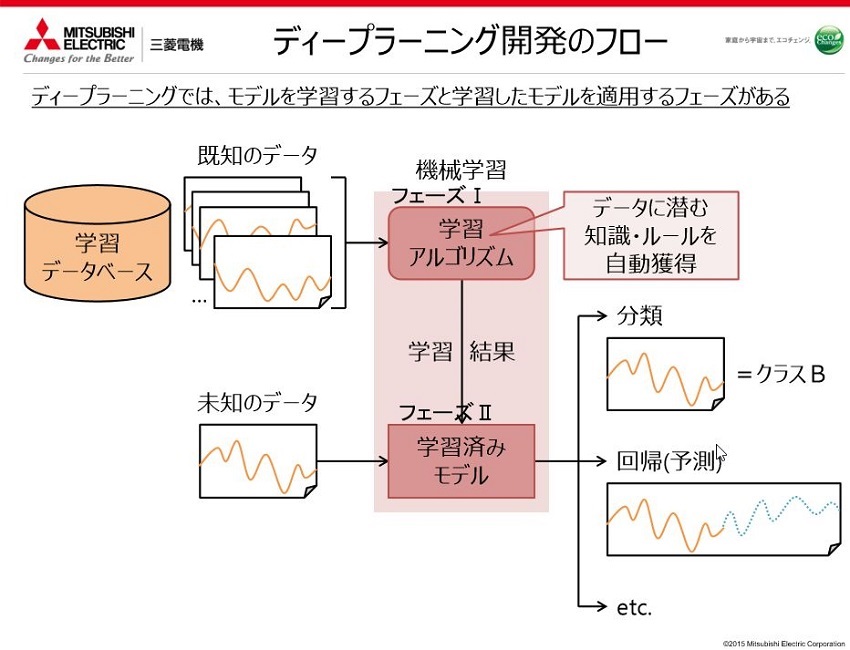
開発の狙いとしてはディープラーニングの学習そのものの演算処理が非常に重たくて、学習を進めて精度を高めていこうとすると大規模なサーバーが必要だったり、専用のハードウェアを準備する必要があったりとなかなか敷居が高いという状況がありました。その学習をどうすれば機器の中で完結して行えるようになるかというところが出発点ですね。
つまり、従来のディープラーニングですと、クラウド上にAIがあってそれは更新されていくと言えると思いますが、それを機器の中に取り込む。要はデバイスに組み込めるようなAIを作ることを目的としています。
─ディープラーニングの学習ができるデバイスの製造を目標としているということでしょうか?
そうですね。そういうところを狙っていきたいですね。例えば昨今、自動運転が非常に多く注目を集めていて、その次にFA(Factory automation)機器分野がありますが、モノづくりは当社にとって非常に重要だと考えていて実際にビジネスとしてもFA関係の引き合いは非常に多いです。近頃の大きな流れとしてはクラウドとFA機器を繋いでのモノづくりがあるかと思いますがFAというのは工場の経営データにも直結しますので、クラウドに情報を上げるのに躊躇を覚える方もいらっしゃると考えています。そういったニーズに向けてできるだけ工場内や設備内で完結してデータを処理できるような機械学習が必要だと考えています。
また監視カメラなどを例にとりますと、よほどのことがない限り警察などが監視カメラのデータを外に出す、クラウドにあげたりするというのは個人情報保護の観点からあまりできません。そうなってくると「エッジ側」である程度処理をして「何かあったよ」ということを外に通知する形態を取る必要があります。
「漫然運転検知アルゴリズム」という機械学習でその人が漫然と運転をしていないか、運転が難しい状態でないかの判別を機械学習で行うソリューションを以前発表させていただきました。その時漫然運転をしているかどうかの判断を心拍数などのバイオメトリクスデータや顔の表情、向きなどのデータから行っていたのですが、顔のデータを取得できているのなら、運転席に座っている人が本当に運転をしていい人かどうかを判断できるのではないかという考えに至りました。
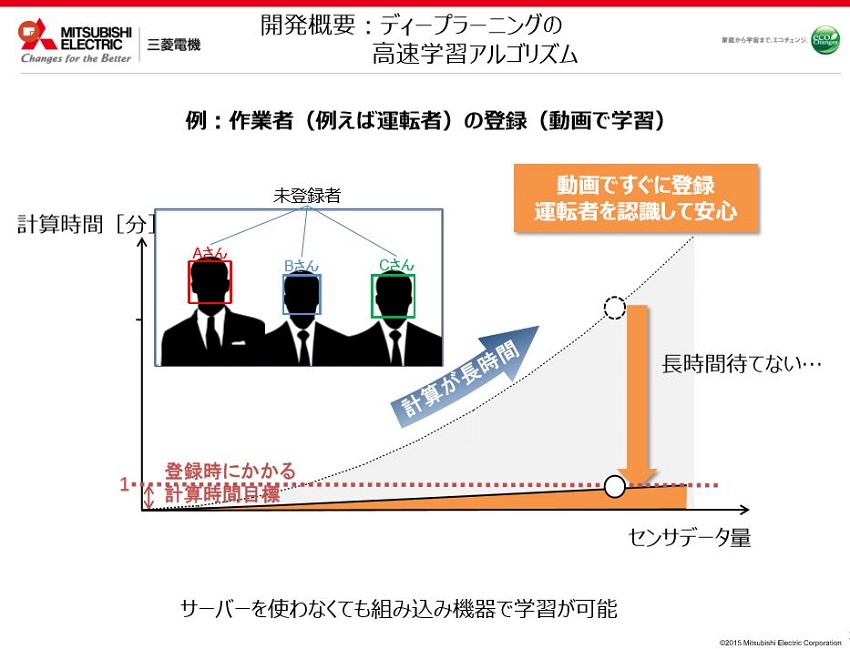
家族の車の場合、父親、母親、成人済の娘は運転が許可されるけど、息子はまだ免許がないから運転席に座っても車が動作しないといった区別がしたいとなると、最初のユーザー登録の際は事前に専用の機械で登録などとすれば良いですが、息子が免許を取ったから途中で息子も運転可能にしたいとなったときに車のCPUでディープラーニングにその人の顔を学習させようとすると、大体30分くらいかかります。いざ使いたいとなった時にそんなに待つのか?となりますので1分以下ぐらいがストレスなく行えるレベルかと思い、今回のディープラーニングの高速化アルゴリズムの開発の話につながってきます。
クラウド上にデータをあげて処理をしたら良いという話も多くありますが、やはり自分の顔となると、どれだけ安全といえどもインターネットを通してサーバーなどに蓄積されていくのを嫌がる人は多いので、組み込み機器の中で完結してデータの処理ができて、外に情報を出す必要がない状態を目指しています。
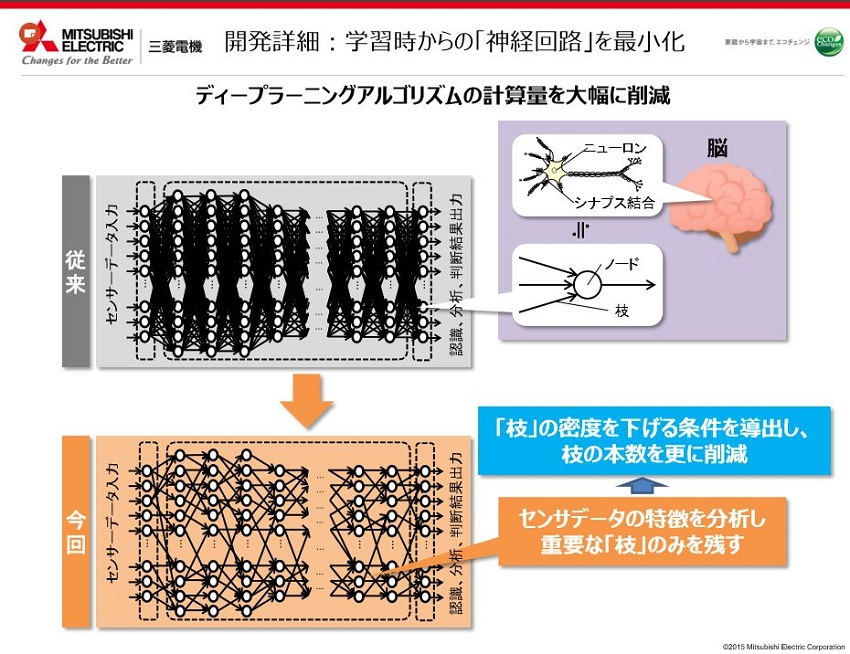
それ以外にも機器ビジネスは非常に多数有りますので、なんとかデバイス内で完結できるディープラーニングができないかという事で、当社で研究を行ってきました。ディープラーニングではノードを複数の枝でつないで、脳の神経細胞と同じような構造を作ります。枝のところを通る際に演算の掛け算をするのですが、そこで処理がかかっているとのことで、どうにか省力化できないかと考えてきました。
─直観的には省くことは難しいのかなと感じてしまいますね
そうですね。ただ簡単に考えると、小学生の時の掛け算で0に何を掛けても0と習ったと思いますが係数が0になる部分をできるだけ増やすようにすることで計算を簡略化できます。我々が行ったのはまさにそういった取り組み方です。
─重みづけに使う係数が0になるところを増やして計算をできるだけ簡略化するということですか。
はい。計算を簡略化できる部分を探すためには、センサーデータの特徴を分析して、その枝の部分でも重要な枝だろうと思われるところを決め打ちで残します。
─これは人が残すのでしょうか?
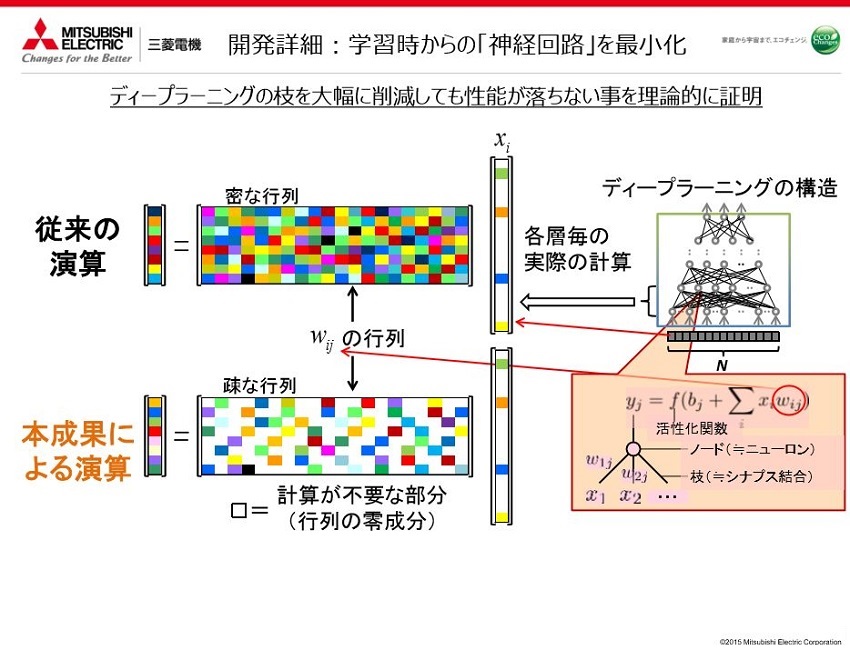
現時点では人が枝を選別しています。枝を大幅に削減しても性能が落ちない事を理論的に証明したのが今回の成果です。日本神経回路学会等と協賛して行っている「ICONIP」という学会が10月16日~21日に京都大学でありまして、そこで成果の発表をいたしました。
色が付いてるのは何らかの値が入っていると思ってください。入力された数値に対して計算を加えて出力を得る形になります、出力側から見ると総和になるので行列演算をしてるのと一緒になります。数字がたくさんあるものは「密な行列」と呼び、そこは計算量が多いままで、従来のディープラーニングと一緒。そこで値をほとんど持たない「疎な行列」をどう構成するかという課題に落ちます。
─きっと、そこがミソですね。
はい。そして実際にできるぞという一つの証明として、論文にはどれぐらい少ない量でいけましたっていう実験表を載せています。MNISTっていう公開されてるデータベースの手書きの数字を画像認識した結果です
─25分の1の計算量で正答率97.9パーセントですか。
はい。これが25分の1の場合で、枝を減らさなかった場合と比べても性能は1パーセント以下しか落ちないということで、結局密な行列で計算したものと疎な行列で計算したものと、ほとんど、結果は変わりません。理論的にいうと疎な行列でも十分性能が落ちないでこの計算を成り立たせる事はできるというところを論文では証明しています。
─その太い幹っていうのを見切るところがすごく難しそうです。どのニューロンが何を想起してるかというのは非常に難しいですし、どれだけ残して、どれだけ切っていいかという判断もすごく難しいような気がします。
確かに難しいですが、例えば入力のデータに対して主成分となり得るような重要なデータの個数がある程度限定できるでしょ?という発想でやっております。主成分となりうるデータをこの密な行列でも疎な行列でも、情報を欠損させないで中間層に伝搬させる事は可能であるというところを今回の論文で証明したという事になります。
計算量を1/25にしても大丈夫ですと。論文には書いてるのですが、理論限界からすると、密な行列でも疎な行列でも同じようにデータを転換できるという事がこの論文の中に書かれてます。論文に記載している例は計算量を1/25にした例を示していますが、他の画像識別の検証では計算量を1/30に削減しても同様の効果が得られたことを確認していますので10/14付のニュースリリースでは計算量を1/30に削減と説明しています。
─これはこのデータだからという事はないのでしょうか?
今回発表した論文ではそういった制約条件はありません。
─人の顔の認識などデータが複雑だと難しいということはないのでしょうか?
扱うネットワークの構造というのでしょうか。構造とかデータとかがどうだったらとか、そういう話は当然出てきます。前提として出てくるのですけれど、それでも何らかの前提を分けた時に、さっきのガンマに依存しないっていうのは実は驚異的なお話でして。それが分かっただけでも、これはすごい成果だなと考えています。
学会で発表した時も、人工知能系ではこういった省力といった面での分析というのはあまりありませんでした。

─どちらかというと精度を上げる方向が多いですよね。
そうですね。メーカー側から見ると性能は良いけどものすごく時間が掛かるとなると利用できる場面が限られてしまいます。車両向けの機器でも、バッテリーに対する影響についてメーカーさんから言われることが多いのでできるだけ抑えたいと考えています。そういう発想で一通りの成果が得られたので、発表をして我々もやってるよ!と旗を揚げました。
─端的に言えば計算量がすごく減るのでそんなにスペックがなくても速く、かつ省電力でできるよって事ですよね。
そうですね。2月に成果披露会という研究成果を皆さま方に知っていただく機会がありまして、その時に「コンパクトな人工知能」っていうタイトルで発表させていただきました。そこでは「学習はスーパーコンピュータなんでしょ?」という声もありましたがなんとか今回の結果を出せました。
─これはネットワークの階層の数が多い方がいいとか少ない方がいいというのはあるのでしょうか?
そうですね。やはりデータの量や種類が多いときに効果を発揮します。2万の入力データがあると中間層で5千ぐらいのデータ数になりますが、この5千の中間層と2万の入力データは全て枝でつながっていて、すべてかけ算を行います。もちろんものすごく負荷がかかります。だから、ここの段階で計算する数をある程度抑えるとガクッと負荷が落ちます。
─そうなってくると、どこを減らしたら良いのかが気になりますね。
我々の方も最初やってる中で「これって減らしても結果は一緒?」っていう話をしてまして、そもそもどうしてそうなんだろうか?みたいなところもある程度直観的にやってきたのですけど、割と理屈立てて展開できるようになりました。設計の話はちょっと置いといて、理論的には皆さんに知っていただいた方が良いと考えて今回の発表をさせていただきました。
─「そういう事ができるよ」ということですよね。
そうですね、「コンパクトにする事に意味がある」というのは割と普遍的な話だと思ってまして、何かの機器を小さくコンパクトにするというのはやっぱり日本が一番得意としてるところなので、そういうところに力を発揮できるということを理解していただきたいなと思います。あとは我々の中で製品化を行う段階で品質管理部門とかのチェックをちゃんと受けて、第三者にも認めてもらって、実用化を行うことで皆さんに「使ってみない?」と言えるようになると思いますが、まず段階としてはアルゴリズムの完成度を上げる段階ですので、もう少しお時間をいただいて、そこを詰めていく予定です。
人の認識能力だと、ほとんどの場合が95パーセントっていう限界値があります。それをディープラーニングが少しずつ超えていくっていうのが今の大きな流れです。先ほどの文字認識では約98%の精度だったと思うんですけれど、そこは人間に勝ってる部分としては割と認識されてきてるところなので。まずはそこで実験して突破口にしていきたいと考えています。
─いずれネットワークにつながらなくてもスマートホーム機器で音声認識が出てくると思いますが、そういうところに使えそうな感じがします。音声認識でその人の癖などをちゃんと学習して、ノーマライズするのは今、簡単にいきません。こういうのがあって家電製品の中に入っていて喋りかけてるとだんだんその製品が賢くなってきて方言でも大丈夫。そしてそれがバッチでデータが吸い上げられて、みんなの方言を共有してくれたりするといいですね。
事前に膨大なデータを我々エンジニアが全て集めることはできないので、やっぱりこういった機能が機器の中に搭載されていかないと、さらなる技術の発展っていうのはなかなか難しいのかなと考えています。

─そうだと思います。冒頭にあったセキュリティカメラも今の物だと笑顔認識とかできるじゃないですか。でもカメラ側である程度データ処理をやってくれないと、全部ネットワークに画像をあげて全部クラウドで処理するというのはナンセンスです。これから先、何十億人って人たちの顔のデータがボンボンあがってくると思った時に、ある程度エッジでさばいてくれないと、とてもじゃないけど処理する事自体にオーバーヘッドが掛かり過ぎちゃう気がします。
もう一世代経てば巨大なサーバー群ができたりして、そういうものも全部繋いでも問題なくなるかもしれませんが、いったんはたぶんエッジ側で処理しないといけない流れが来ると思います。画像は何を認識したいかとかが割とはっきりしてきたので、やってる人達が出てきてますけど、音声がまだ全然手つかずの状態ですし、さっきの車の中の環境なんかもまだまだという感じがします。
音声なんかでもサンプリング間隔を見ると10マイクロセックとか20マイクロセックごとにサンプルを取ってますが、全部ネットワークにあげる必要ありますかと思いますね。
─データが小さいとしてもある程度のノーマライズは必要ですね。機器自体がさっきみたいに勝手に方言対応していくみたいなことは結構大事だと思います。すべての処理をサーバーに任せるというのは冗長な感じもしますし、日本語だけでも相当なパターンがあるのに、それを一つのパターンだけでしか返せないというのはちょっと無理がある気がします。
だいぶ無理があると思いますね。その人向けにカスタマイズされていくことで心地よい環境を作り出すわけで、心地よい環境は例えば安全・安心。ひいては、そういうところにもつながる話です。例えば、「ヒューマン・イン・ザ・ループ」っていう言葉が最近流行ってますけれど、やっぱりどんなシステムでも人が間に介在しているので、その人にとって最適化されたものっていうのがやっぱり必要です。今までは人が機械に合わせていったっていう流れを、機械側が人に合わせていくような流れにしていくべきだと考えています。
やっぱり人間の事を理解する。あるいは、人間に寄り添うような機器を目指すと、サーバーに何でもかんでも持って行くのがいいってわけでもないのかなと思います。
─セキュリティ的にも何でもつながってると少し怖いですよね。
特に顔は皆さん抵抗感があるみたいですね。ネットワーク側に何かアタッカーが来れば脅威にさらされてしまうことになるので、色々な局面で考えると必要以上にデータは出さない方がいいんじゃないかと考えています。
─今後は本技術をどういった発展をさせていきたいと考えていますか?
やっぱり究極的な話で言うと、「自律的」というキーワードがあると思います。例えば設計者が考えなくても、ある程度機械側で吸収して自分の力で学習していくものですね。なかなかそこまで一足飛びには行かないとは思っていますが、別件でご紹介しているニューラルネットワークの自動設計もそういう発想が出発点になっています。その研究とこの研究はまだマージできていませんが、そういうところをリンクしていくと、どんどん自律的なものになっていくんだろうなと思っています。

─なるほど。この中間層を全部自分で勝手に設計できるようになるかもしれないわけですね。本日はありがとうございました。
【関連リンク】
・三菱電機(Mitsubishi Electric)
コンサルタント兼IoT/AIライター 人工知能エンジン事業の業務支援に従事するかたわら
一見わかりにくいAIの仕組みをわかりやすく説明するため研究中

















