

この記事はNVIDIAのブログ記事で発表された内容である。
NVIDIAは、JetsonTX1とTX2に対応した運用LinuxソフトウェアリリースであるJetPack3.1を発表した。TensorRT2.1とcuDNN6.0へのアップグレードにより、JetPack3.1はビジョンガイドによるナビゲーションやモーションコントロールなど、高速なバッチサイズ1を利用するリアルタイムアプリケーションでディープラーニングのパフォーマンスを最大2倍に引き上げる。そして、この機能強化によってJetsonが従来以上のインテリジェンスを展開することで、配達ロボットやテレプレゼンス、ビデオ分析といった各種自律型マシンを生み出していくことが期待されている。
NVIDIAはJetson TX2のリリースの際、エッジコンピューティングのプラットフォームとして大きな機能強化を施したという。Wave Gliderのようなネットワークのエッジで動作する遠隔制御のIoTデバイスでは、ネットワークの通信範囲や帯域幅が狭まり遅延が悪化することが多く、またクラウドへのデータを中継するゲートウェイの役割を果たすことが一般的だ。一方で、エッジコンピューティングでは安全な内蔵型のコンピューティングリソースにアクセスできるようにすることで、IoTの可能性を広げることが期待されているという。

NVIDIAのJetsonが組み込まれたモジュールは、Jetson TX1で1TFLOP/sでサーバーグレードのパフォーマンスを実現し、Jetson TX2では10W未満の電力でAIパフォーマンスを2倍に引き上げることができるという。
Linux For Tegra (L4T)R28.1を搭載したJetPack3.1は、Jetson TX1とTX2に対応した長期サポート(LTS)版の運用ソフトウェアリリースだ。顧客向けの製品化には、TX1とTX2に対応したL4Tボードサポートパッケージ(BSP) が最適だという。また、それらのLinuxカーネル4.4の共通コードベースによって、TX1とTX2間の互換性とシームレスな移植が実現し、JetPack3.1以降は、ユーザーはTX1とTX2の両方で同じライブラリ、API、ツールバージョンにアクセスできる。
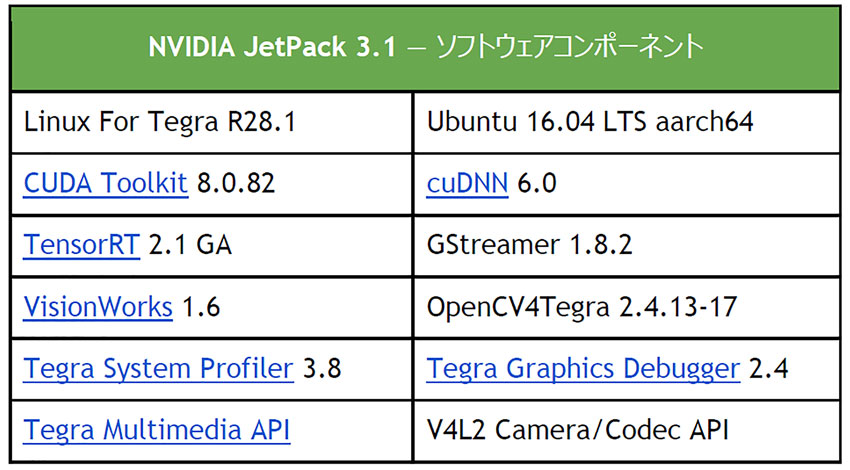
cuDNN5.1から6.0へのアップグレードとCUDA8への保守更新に加えて、JetPack3.1にはストリーミングアプリケーションの構築に役立つ最新のビジョンおよびマルチメディアAPIが含まれている。使用するホストPCにJetPack 3.1をダウンロードすると、最新のBSPやツールによってJetsonをフラッシュできる。
JetPack3.1には最新バージョンのTensorRTが搭載されているため、最適化されたランタイムのディープラーニング推論をJetsonで展開できる。TensorRTではネットワークグラフの最適化、カーネルの統合、半精度FP16のサポートによって推論パフォーマンスが向上するという。また、TensorRT2.1には複数の重み付けによるバッチ処理をはじめとする主要機能と拡張機能が含まれているため、Jetson TX1とTX2のディープラーニングパフォーマンスや効率がより高まり、遅延が短縮されるという。
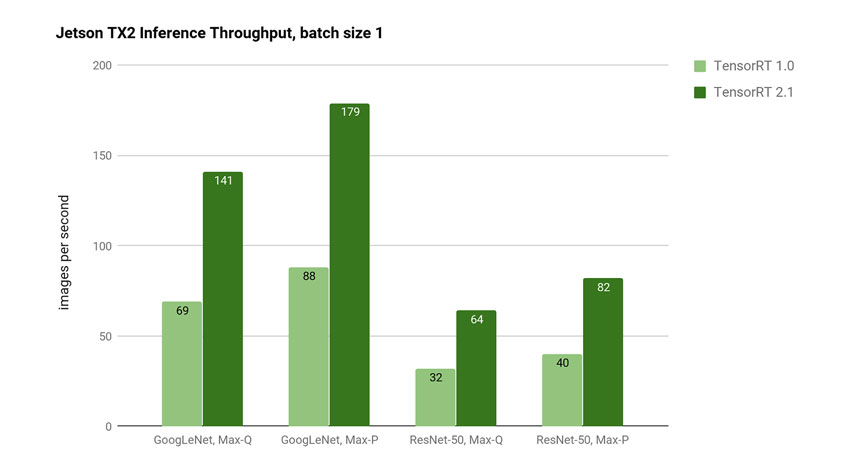
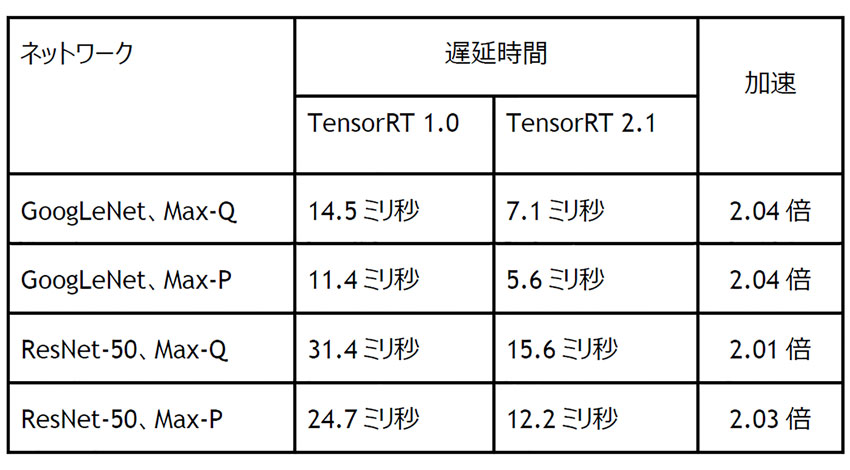
表1に示された遅延時間からは、バッチサイズ1では遅延が比例的に短縮されることがわかる。Jetson TX2でTensorRT2を使用した場合、GoogLeNetではMax-Pパフォーマンスプロファイルで5ミリ秒の遅延、Max-Q 効率プロファイルでの実行時に7ミリ秒の遅延を達成している。
一方、ResNet-50では、Max-Pで12.2ミリ秒の遅延、Max-Qで15.6秒の遅延となっている。ResNetは通常、GoogLeNetよりも画像の分類における精度の向上を目的として利用され、TensorRT 2.1を使用すると2倍を超えるランタイムパフォーマンスの向上を達成できるという。さらに、Jetson TX2の8GB のメモリ容量によって、ResNetのような複雑なネットワークでも、最大128の大規模なバッチサイズが可能になるという。
遅延が短縮されることで、ほぼリアルタイムの応答性が必要な用途 (高速なドローンや水上艇の衝突防止、自律航行など) で、ディープラーニング推論のアプローチを利用できるようになるという。
TensorRT 2.1 では、ユーザープラグインAPIを使用したカスタムネットワークレイヤーをサポートしているため、残余ネットワーク(ResNet)、リカレントニューラルネットワーク (RNN)、You Only Look Once (YOLO)、Faster-RCNNなどにサポートを拡張することで、最新のネットワークや機能を実行できるようになるという。カスタムレイヤーは、次のIPluginインターフェイスを実装するユーザー定義のC++プラグインによって実装される。

ユーザーは、上記のコードと同様のカスタム定義のIPlugin によって、独自の共有オブジェクトを構築できるという。ユーザーのenqueue()関数内にCUDAカーネルによるカスタム処理を実装できる。TensorRT2.1では、この手法を使用してFaster-RCNNプラグインを実装し、オブジェクトの検出を強化する。
また、TensorRTでは、Long Short Term Memory (LSTM)ユニットとGated Recurrent Unit(GRU)用の新しいRNNレイヤーを提供し、時系列シーケンスのメモリベースの認識を向上させる。このようなレイヤータイプをすぐに利用できるようにすることで、組み込みのエッジアプリケーションへのディープラーニングアプリケーションの展開を加速させていくという。
提供:NVIDIA
【関連リンク】
・エヌビディア(NVIDIA)

無料メルマガ会員に登録しませんか?

技術・科学系ライター。修士(応用化学)。石油メーカー勤務を経て、2017年よりライターとして活動。科学雑誌などにも寄稿している。

















