

アレグロスマート社はAIと連携した開発不要なIndustry4.0に対応できるプラットフォームを提供している。
今年の6月にはAI Modelの開発環境 Data Scientist Development 機能を追加した、複数のAI Modelの学習を同時に実行ができ、完成した復習のAI Modelを実行ができる実践で活用できるIoT×BigData×AI プラットフォームを展開していくという。
今回、アレグロスマート株式会社 代表取締役社長CEO 田渕鳴利氏、同社 取締役CTO 原田充氏に話を伺った。(聞き手:小泉耕二)
-御社について教えてください。
田渕: 弊社は12年目になりますが、私はもともと日立製作所の関連会社でSEをやっていました。その後、PSInetに移りデーターセンターの立上げに携わり、その後ITの世界に関わっています。
2004年に某警備会社から、個人情報保護法の施工に伴うフィジカルとITセキュリティを融合させたシステムを作りたいという相談をいただいたのが、起業のきっかけです。

-情報漏えいが大問題になったころですね。
田渕: そうですね。その知見を活かして、2007年に「M2Mクラウド」を開始しました。
その後、バージョンアップを作りながら、運よく2010年に(株)スペースシャワーネットワークが提供運用しているSPACE SHOWER MUSICの楽曲ダウンロードすべての実績データを集めて、基幹システムに毎日200万件以上のデータを連携して、ビックデータにしています。

さらに某製薬メーカーとの事例で、遠隔からリアルタイムで、ガンの治験薬の温度管理をすることもやっています。システム運用やITシステムに豊富な人材がいない為、フルスタックで、開発不要のIoT×BigDataPlatformクラウドサービス、バージョン3.0の提供を開始しました。
次に未病対策。心拍数や血圧、気象データなど10万人分の対応をし、当時は、オープンソースの大量のリアルタイムの複数の計算処理が必要なストリーミングソフトウェアApache Spark Streaming(大規模ストリーミング処理フレームワーク)を活用して
3.5にバージョンアップしました。
しかし、このソフトウェアでは、対応できても、非常にサーバーコストの膨大な負担やリアルタイムのデータ処理計算には、向かないことがわかり、その後、弊社のCTO原田が独自に大規模分散ストリームング処理フレームワークを開発し、製品を「Allegro Smart Platform(アレグロスマートプラットフォーム)」という名前に変更したのと同時に、ブランドを向上させるために会社名も「Allegro Smart」にしました。
そして、2016年にGoogleが開発しオープンソース化したされた人工知能エンジンTensorFlow
と連携をしました。某大手鉄鋼メーカーへ提供、現場で製造製品の人工知能を使ったシミュレーションをパソコン上で確認できるサービスを提供しました。その後、某警備会社のスマートハウスサービス事業を展開したいご要望に応えて、準備しています。
これらの経験を元に、インダストリー4.0と言われているビジネスモデルも含まれています。でも、インダストリー4.0のプラットフォームというのは、まだありません。
-4.0自体は、まだ概念モデルですから。

田渕: IoT×BigData×AI PlatfomであるAllegro Smar tPlatformの特徴は、フルスタックで必要な多種多様なフォーマットの異なるデータの収集、意味の共通化、リアルタイムな複数の同時計算処理と複数の計算処理連携、複数のAI Modelの実行と複数のAI Model連携、BigDataの利用APIサービス機能が準備されているのですぐに始められます。
これにSaaSでAllegroSmart System Consoleによって利用できるというにしています。今進めているうちの一つがAI機能の充実です。6月ぐらいにデータサイエンティストプラットフォームクラウドサービスというのをリリースする予定にしています。AI Modelの開発できる環境と開発履歴管理と複数のAI Modelの学習機能と精度比較機能を追加します。
遠隔で我々がAI Model開発をサポートをします。インターネットを通じて、AI Model開発のクラウドソージングも実現できます。AllegroSmart Platformで、データサイエンティストの育成が気軽にできるモデルが展開できるのです。クラウドソージングのようなモデルができると良いと思っています。
原田: 私から事例をご紹介します。神奈川県の大山に環境センサーを設置し、山の天気予測をしています。温度、湿度、気圧、雨量、風向、風速などを取って、リアルタイムで出しています。

気象庁は、地球だったり日本だったり見ている範囲が広いですが、局所的な天気はわかりません。山の天気には、この風が吹いたら雨が降るとかあるそうです。私達はそういった局所的な天候の予測に機械学習を使っています。
田渕: これをやった理由は、IoTプラットフォームと言われてもわからない、というお客様が多かったので、わかりやすい事例を作ったということなのです。
-なるほど。どこかにある学習データを入れたわけではなく、学習データはセンシングしているわけですね。

原田: そうです。データ自体は3年ほど取っていたので、機械学習による予測の精度も測れるということです。
田渕: ここがミソで、前提条件としては、雨が降るだろうということを解析、分析します。気象庁などを見ながらデータを使って判定をしていくことをやった結果、温度、湿度、気圧、風速、風量は1分刻みに直して、かつ雨量は10分刻みに直したデータを使うと良いということがわかったのです。
-ああ。学習データ自体も実はコツがあったということですね。
田渕: そうです。現状、90%ほどの確率で当たるようになっています。ただ、落とし穴があって、ディープランニングはちょっと合わないのです。
-わかっている人が雲を見れば「今日はしけるな」みたいな話ですよね。山の危険を事前に知ることができるのはニーズがありそうですね。
田渕: そうですね。最終的にはデータサイエンティストプラットフォームを展開しようと思っています。今はIoTプラットフォームが、フルでプロセスが使える状態で月10万から15万円、時には5万円ぐらいで提供します。AIをつけると、毎月50万円もしくは従量制にすることを検討しています。
-なるほど。モデルを作るところがミソですよね。世の中の人が結構誤解していると思うこととして、「学習モデルがなきゃいけない」ということがあります。モデルを作るのにもさっきの気象情報の話があったようにデータの置き方によっては、アホなAIが出来たりするということをご存知でない方も多いのです。
AIを買ってきたらなんでもできると思い込んでいて、いやいやデータがいるのですよ、と言う話ですが、話を進めていくと「チューニングしなきゃいけないなんて聞いてない」という話になります。「『AIはなんでもできる』をまず払拭するのが俺の仕事だ」という方もいます。

田渕: 私も似たような話をよく聞きます。
-御社はデータ収集プラットフォームも作られているし、そこから機械学習のモデルを作るところもやっているということですね。
田渕: そうですね。結局、組み合わせたものじゃないと役に立たないんじゃないかと思っているのです。最終的には、データサイエンティストサービスというのを事業化しようと考えています。
さらに、お客様の会社にデータサイエンティストを教育しようと思っています。全部アウトソーシングしてしまうと、社内に何にも残らなくなってしまいます。
-データサイエンティストって難しいですよね。
田渕: ただ、何のデータと何のデータを組み合わせたりることで、様々な予測ができたりするはずだとお客様は考え方を持っています。特に現場の人たちですがね。
原田: 製造業の事例ですが、当日か前日に受注して当日出荷という、結構スパンが短いのですが、どれだけ工場のリソースが余っているかわからなくて、注文を受けられるかどうかリアルタイムにわからないのです。スケジュールもどの機械や人が余っているかというのが結構大変で、手計算でやっているのです。どれだけ今人が足りているんだろう、何時になったら終わるんだろうというのがわかりません。
そこで、スケジュールは自動ででき、注文を受けられるかどうかを予測したいということでした。そこで、分析をおこなって、受注データと工程が進むたびにイベントをもらい、それを使ってスケジュールを自動でいろいろ分析等を行って、こんな工程があって、そしてこういうものができそう、という予測をおこなっています。
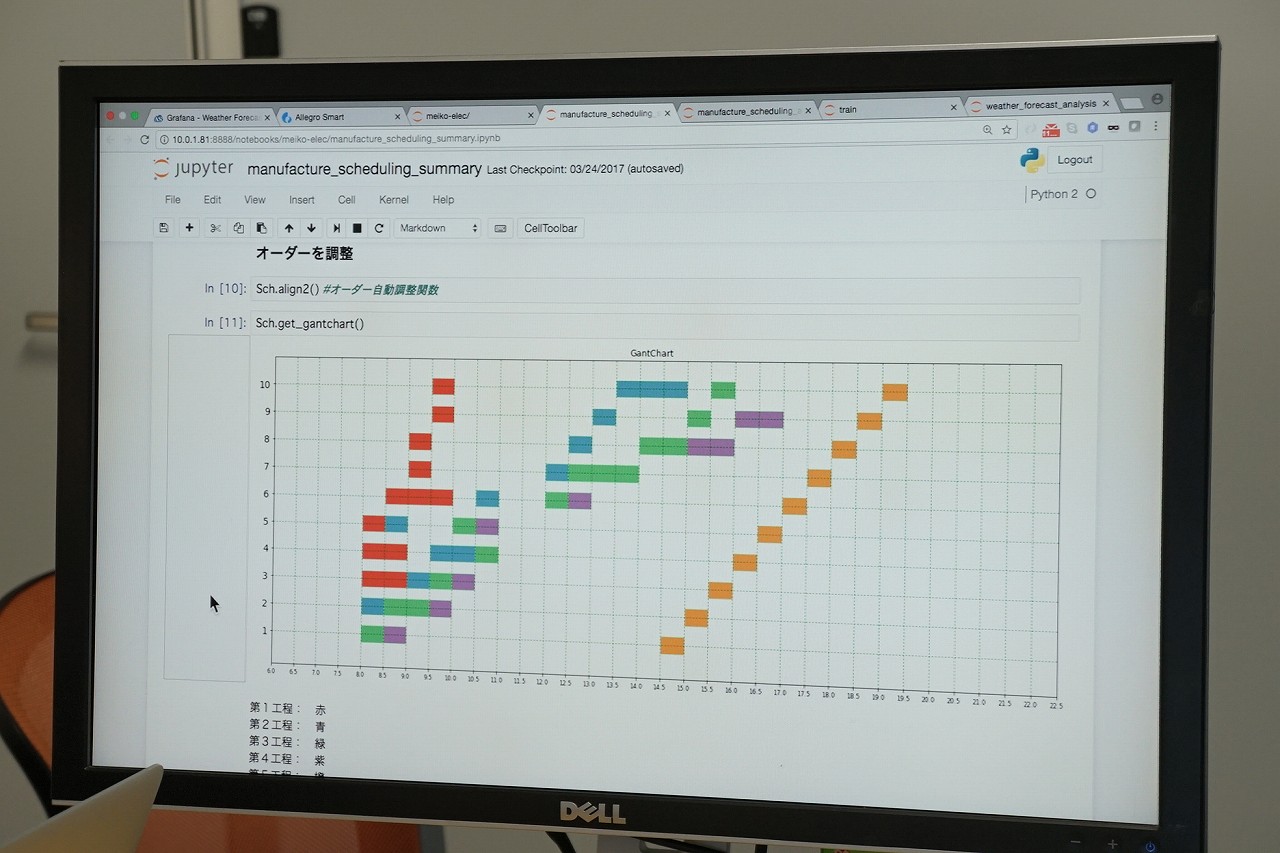
田渕: この時に足らないデータがわかるのですが、やってみないとわからないこともあります。
-やらないとわからないというのは、見積もれないからやっかいですよね。
田渕: 初期は無償でやっていました。
-PoCは工場の決裁権じゃないところでやっていると思うので、工場の決裁権でこれをやろうとするからダメだって話になるのではないでしょうか。
田渕: 見せるものができていると話をしやすいです。
-工場におけるデジタライゼーションは、それぞれの工場の稼働状態や、その中にどういう産業機械が入っているからどういうモノが作れるかということを全部データで持ってくるわけです。そうすると、ある受注があった時にどこの工場にいつ渡せば何が作れるとか全部わかりますよね。それで生産を全部効率化していくことができれば、すごく先まで行くとマスカスタマイゼーションができるわけです。
要は全てのお客様のニーズを把握しながら、「じゃあこれはA工場にやってもらおう」「これはB工場にやってもらおう」ということしながら生産ができます。これがインダストリー4.0の本質なのです。だから御社の仕組みはすごくいいと思います。ただ、産業機械によって癖があるので、デジタライゼーションは案外簡単にいかないことが一番問題なのです。
田渕: そういう意味では、今太陽光発電所が80万カ所ぐらいの話がきています。電気の電圧が安定して供給できないということで、我々が間に入って、発電量を予測したり、どこのパネルがおかしいのかをデータにします。
-太陽光発電の設備を監視し、電力生産量を予測するのですか?
田渕: そうです。これストリングをただ見ているだけなのです。パネルが一つじゃ何ボルトと決まっているので、それを直列につなげるのですね。それを1個のストリングと言います。
原田: 1個で40ボルト、10個で400ボルトという感じでまとめます。その後、パワコンや分電盤を経由して、売れるようになります。このような施設で、各設備の内、発電効率に影響がありそうな設備の前後に電力計を設置し、データを取っています。
-ということは施設内のパネルのグループみたいな位置づけですか?一つのグループは例えば直列だったりするのかもしれないけど、これが一つのグループで、二つ三つ四つってあるということですか。
原田: 一つの施設で1グループもあれば、複数グループもあります。データを取るのは各設備の前後になります。

-その取っているデータがいきなり落ちるのですか?
田渕: これは面白いことに発電量のグラフが急にどんと落ちるのです。パネルだからフンが落ちたり、故障したりなどが原因です。それをまず見ましょうという話になって。今度は日照と発電量から発電効率を計算し、そのデータを蓄積し分析すると予測できるのです。
-でもさすがにフンが落ちるのは予測できないですよね。
田渕: さすがにそうですね。故障の予測をします。法律で、何かあった時に東電に報告書を提出しなければいけなくなるので、自動的に報告書を出すということを対応中です。
-要は供給状態をちゃんと監視して報告書を出すというのと、あとは供給高が落ちるタイミングを先に予測して、なるべく早く直そうということですね。
田渕: そうです。そうするとより一層設備の予防保全ができるのではないかなと。今、太陽光発電がほったらかしであることが多いのです。
次に、アメリカの製品の話なのですが、我々はオプティマイズと言っているのですけど、電力をストリングいっぱいつなげると落ちたりして電気が安定しないのですが、その電気を安定させる機械があります。
とにかくずっと安定してほぼ1000ボルトで出力する機械があって、それを連携させました。そうすると供給側は安定して提供することができる装置とセットで監視をします。
-なるほど。監視そのものと装置を使った安定供給を一緒にサービスとして今後販売されるのですね?
田渕: そうです。
原田: 次に、今この会議室のドアに開閉センサーや温湿度センサーをつけていて、玄関のマットにはマットセンサーをつけています。

それらのデータを時系列でグラフに出しております。

-アレグロスマートはカスタマイズしやすいのでしょうか。
田渕: そうですね。センサーはどこのメーカーのものでもかまいません。それを吸収できるようになっています。
特徴はオプティマイザーと言って、プロセッシングの機能でデータの様々なデバイスシステムなのですけど、データを共通化できるのです。メトリック情報と言っているのですけど、無いものはどんどん増やすことができます。
-構成を全部意味づけしているのですか?
田渕: そうです。生データ一応全部取っていて、オプティマイズデータを作っていきます。
-なるほど。だから昔の電文生成主義みたいなことやっているのですね(笑)。
田渕: ええ。なので、PLCのデータとMESの情報をくっつけるだけでできるのです。
-そうですよね。データの構造がわかっちゃえばどこに何が入っているかはっきりしますよね。
田渕: そうです。うちの特徴はデータを取った後にデータの構造を解析して設定をするのです。なので非常に使いやすいです。
-普通はプログラムをして、データの何バイト目のデータを取って、このデータとこのデートをくっつけるプログラム書かなきゃいけないところが、データの構造をはじめに定義しちゃうから、あとから例えばストレス指数というやつを引っ張ってきてとかをGUIベースで出来ちゃうわけですね。
田渕: おっしゃる通りです。あとカリキュレーターというスクリプトなのですけど、この設定ですね。計算式が。さっき定義したデータを使っているのです。それを動的にWebにもできます。
-どのように料理するかがこれに書いてあるのですね。何言語でやっているのですか?
田渕: これはJavaScript(ジャバスクリプト)です。Pythonも一応書けるようにします。
-Pythonの方が早そうな感じがしますね。
原田: 統計処理はライブラリが充実しているPythonが速いですけど、通常処理ではJavaScriptの方が速いですね。Googleが作ったJSエンジンが速いです。
-ではJavaScriptの技術と知識があって、データがシリアライズできればアレグロスマートの中で様々なデータの構造を操作するということができるということですね。
田渕: おっしゃる通りです。これと同時にマシンラーニングがあるので、ロジックこっちでかけるようになっています。個々でデータを選んでもらって、学習させるということができるようになっているのです。

-ここはさすがに学習モデルの数式を知らないとダメですよね。
田渕: ここを企業の方に教えていこうと思っていて、Slack(スラック)と画面を使いながら実際に今もやっています。
-引っ張ってきたデータをGoogle Cloud Platformに食わせて、TensorFlow(テンソルフロー)でやるという話にはならないのですか?
田渕: これ実はTensorFlowでやってます。
原田: 今はTensorFlowとR(アール)の機械学習と、それからChainerの3つが入っています。
田渕: そして、こういった履歴も全部とれるようになっているのですよ。全ての生データ(RawData)をとっていって、学習データのセットも全部とっていきます。そうしないとわからなくなるので。

原田: どのデータとどのロジックで学習してどの結果(精度)になってどのモデルができた、というのはセットで取っておかないと評価ができなくなります。これだとうまくいった、これはダメだった、というのがありますので。
-なるほど。同じロジックでデータを変えるのですか?それともデータが同じでロジックを変えるのですか?
原田: 両方ですね。
-両方あると思うのですけど、どっちが多いのですか?
原田: ロジックを変える方が多いです。
-じゃあロジックを変えることで学習効率が上がるケースがあるということですか。
原田: ロジックを変えることで学習効率が上がります。データを変えることより簡単に試すことができます。両方ですね、やっぱり。それから、データとロジック両方、同時に変えることもあります。いずれにしても結構地道な作業です。

-私はデータの要素を変えるのかなと思ったのです。今まで気温はやってなかったけど、この度気温も足してみましたみたいなことやるのかなと思ったのです。
原田: はい、やりますね。先ほど田渕からも説明があった通り、今まで風速だけ使っていたのが、風速の変化量を使うとなったり。天気の場合ですと、普通に全て学習データにすると晴ればっかりのデータなので、雨のデータが非常に少ない。
偏ったデータにしないために、雨を多めにチョイスしようとか。そのような調整をしないとよい学習ができないのです。なので、エクセルでいうところの、列を増やす方向のデータ追加と、行を増やす方向のデータ追加のどちらも行います。
-どちらも行うのですね。だからやっぱりデータをいじる方が多いのではないかと思ったのですが、そういうわけではないということですよね?データを変えるとロジックももちろん変えなきゃいけないのわかるのですが。
田渕: そうですね。先にデータだと思いますね。
-ですよね。大枠のロジックというか考え方は特に変えなくて、データの幅や量を変えたりするのではないでしょうか。
原田: そういうケースもありますけれども、ディープラーニングの手法自体を変更することもあります。
-なるほど。そっちは様々なロジックを使って、結果の良し悪しを見ながら変えていくということですね。
田渕: 今ちょっとバージョンアップしているのは、データやっぱりチョイスの時点で、データプロバイダーAPIを用意しているのですね。API選んでデータセット作って、セットをいろいろ作ればいいのです。
-なるほど。中間データを作るみたいな。
田渕: そうです。学習するデータをそれで分析ならこのデータセットって決めるじゃないですか。そろえたセットが保存されていて、それをここで選んで。この機器のこれとこれとこれのメトリック(データ項目)のデータセットを1分刻みと10分刻みで、という操作もできるようになっています。

-本日はありがとうございました。
【関連リンク】
アレグロスマート
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















