

パナソニック ホールディングス株式会社(以下、パナソニックHD)は、カリフォルニア大学バークレー校(以下、UC Berkeley)、北京大学、カーネギーメロン大学の研究者らと、未知のデータを効率的に見分けることに着目したAI技術「Split-Ensemble」を共同開発した。
同技術は、AIに解かせるタスクを、似たような対象を分類する複数のサブタスクに分割し、サブタスクの中で「未知データ」も多面的に教え込むことで、未知データを見分ける能力を効率的に獲得するものだ。
従来、AIが学習していない分布外のデータ(out-of-distribution、以下、OOD)への対処は、OODとして学ばせる外部データを用意し、追加の計算コストをかける必要があった。これに対し、今回開発された「Split-Ensemble」では、既にあるデータセットのみから作成した複数のサブモデルを使って、OODへ対処できるようにする。
具体的には、似た者同士を見分けるサブタスクを複数用意し、それぞれのタスクを解く複数のサブモデルを学習する。
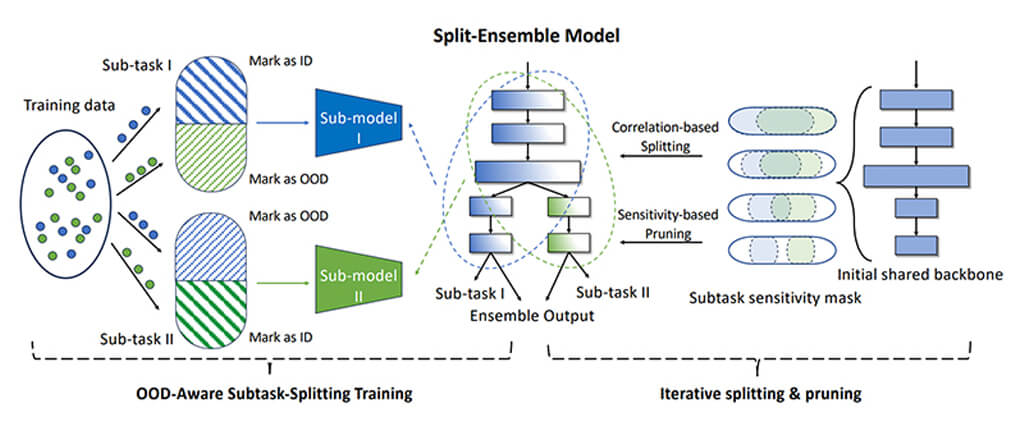
サブタスクでは、一部のデータを分布内データ(in-distribution、以下、ID)として扱い、残りをOODとして学習させるアーキテクチャになっている。例えば、「ビーバーとカワウソとアシカとそれ以外(OOD)」、「楓と樫と松とそれ以外(OOD)」という風にすることで、似たカテゴリ同士の見分け方と同時に、OODの見分け方を学習する。

元のタスクを解けるようにするには、複数のサブタスクでサブモデルを学習し、それらの出力を統合する必要があるが、小規模でも学習させるモデル数が増えれば必要となる計算量は増加する。そこで今回は、サブモデル間で可能な限りアーキテクチャを共有し、モデルの枝刈りなどを行うことで計算量の増大を抑制した。
そして、同手法の有効性をベンチマークデータセット(CIFAR-10、CIFAR100)で検証した結果、従来法に比べて4分の1の計算コストでOODを見分けられることが確認された。
パナソニックHDは、同手法の最も大きなインパクトについて、「独自のアーキテクチャにより深層学習モデルにOODの検出能力を向上させたという点だ」としている。
今回の取り組みでは、ImageNetデータセットなど、比較的小規模なタスクで評価を行ったが、今後は、同手法を大規模なLLMsに適用することで、ハルシネーションの抑制などにも繋げていくのだという。
なお「Split-Ensemble」は、AI・機械学習分野のカンファレンス「The 41st International Conference on Machine Learning(ICML 2024)」に採択され、2024年7月21日から2024年7月27日にオーストリア ウィーンで開催される同会議で発表される。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















