

株式会社ELYZAは、商用利用可能な130億パラメータの日本語「ELYZA-japanese-Llama-2-13b」を開発し、一般公開した。
2023年8月に公開した「ELYZA-japanese-Llama-2-7b」と同様、Meta Platforms, Inc.(以下Meta)が開発した英語の言語能力に優れた大規模言語モデル(以下LLM)である「Llama 2」に対し、日本語による追加事前学習と、ELYZA独自の事後学習を行ったモデルとなっている。
学習に用いたのは、OSCARやWikipedia等に含まれる日本語テキストデータだ。複数のバリエーションがあり、ユーザからの指示に従い様々なタスクを解くことを目的としてELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-13b-instruct」や、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-13b-fast」が存在する。

パラメータ数が130億に増加したことに加え、事後学習に使用するデータを増強したことで、「ELYZA-japanese-Llama-2-7b」を上回る性能を実現している。
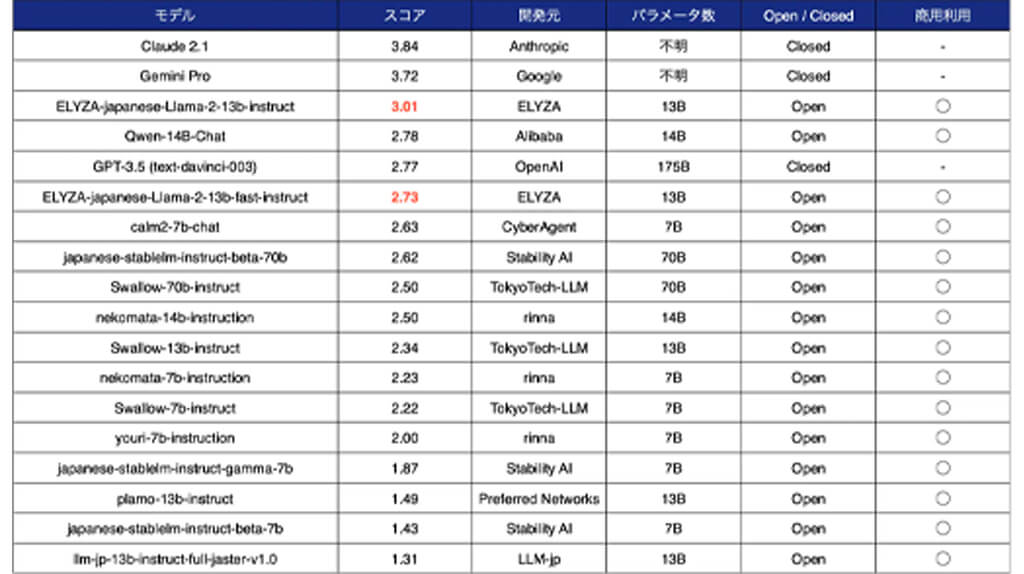
性能について、ELYZA独自作成のデータセットを用いて評価した結果、「ELYZA-japanese-Llama-2-13b-instruct」については、13Bモデルながら70Bモデルを含むオープンな日本語LLMの中で最高のスコアを獲得した。
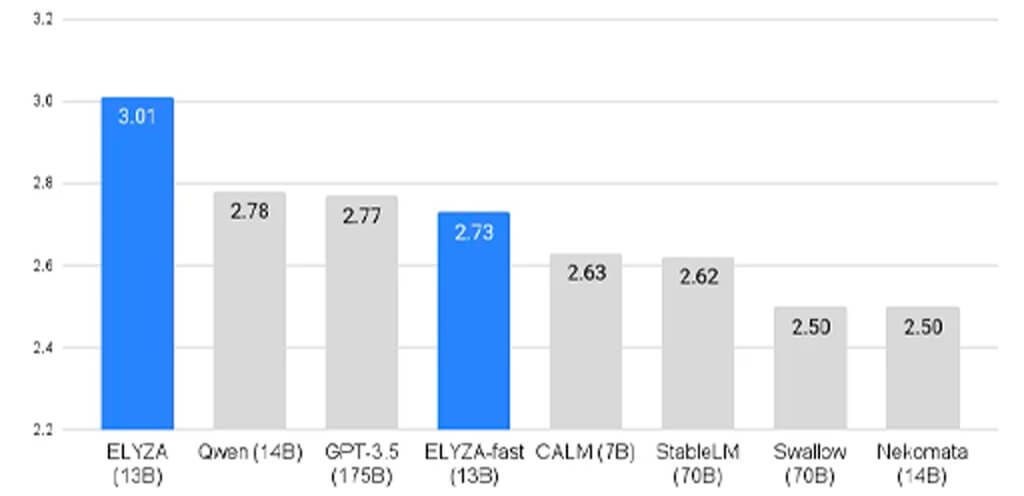
また「Qwen-14B」を除く日本語LLMの中では唯一クローズドなモデルであり、1750億(175B)パラメータのGPT-3.5(text-davinci-003)を上回る結果となっている。
さらに、「ELYZA-japanese-Llama-2-13b-fast」では、前回の「ELYZA-japanese-Llama-2-7b-fast」で作成したトークナイザーを効率化するためにいくつかの改良を加えることで、前回(13,042個)よりも少ない12,581個の日本語の語彙追加で、同じ日本語の文章を表すのに必要なトークン数を元の「Llama 2」の47%まで削減することに成功している。なお、前回は55%で、推論速度に換算すると、約2.27倍の性能だ。
ライセンスは「Llama 2 Community License」に準拠しており、Acceptable Use Policyに従う限りにおいては、研究および商業目的での利用が可能だ。
加えて、チャット形式のデモについても、Hugging Face hub上で公開されている。デモを公開するにあたり、vLLMというライブラリを用いて推論を高速化し、その効果を体感できるよう「A100 GPU」を使用したデモ提供も行われる。
なお、一定期間後は、13Bモデルを低コストで運用するための手段として検証中である、量子化したモデルとデモの公開を検討しているとのことだ。
今後は、現在進行中のAI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI) の大規模言語モデル構築支援プログラムにて、700億パラメータモデルの開発も進行していくとしている。
さらに、「Llama 2」での取り組みに限らず、海外のオープンなモデルの日本語化や、独自のLLMの開発を進める計画だ。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















