
昨今、大規模言語モデル(以下、LLM)が実業務へ導入され始め、LLMによるテキスト生成に外部情報の検索を組み合わせることで回答精度を向上させる技術「Retrieval Augmented Generation(RAG)」が注目されている。
RAGにより、最新の正確な情報に基づいた回答生成や事実に基づかない情報生成(ハルシネーション)を抑制する効果が期待されている。
しかし、企業が保有するデータを扱う際に文書が複雑であることや、専門知識を要するなど、ドキュメントの解析や理解、意味抽出の観点からRAGにデータを取り込む過程での課題もある。
こうした中、株式会社シナモン(以下、シナモンAI)は、社内文書を活用するためのドキュメントLLM「Super RAG」を発表した。
「Super RAG」は、表やチャート図、棒グラフやダイアグラム、手書きなどの帳票から、情報抽出しながらハルシネーションを抑制し、LLM利用における文書活用を支援するサービスだ。
LLMが提供する全ての機能が利用可能であることを基本とし、「ドキュメント解析」「ナレッジ注入」「プロンプト自動生成」といった3つの独自技術を活用している。
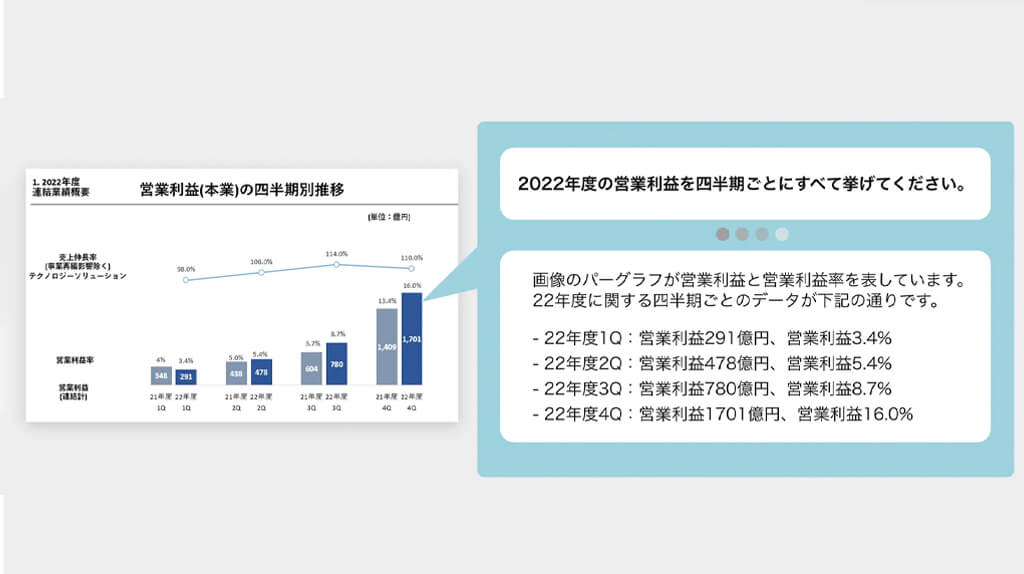
以下は、一般のRAGシステムでは読み取り難易度が高い図表のサンプルと、シナモンAI「Super RAG」による情報抽出結果だ。読取対象とした元データは、同社が独自に作成したサンプルデータだが、読取結果は実際に各データをインプットとして「Super RAG」に投入した出力結果となっている。

今後シナモンAIは、ドキュメントLLM「Super RAG」をエンドユーザ企業やパートナー企業向けに販売を推進するとしている。
なお、パートナー企業においては、提供されるアプリケーション内で「Super RAG」を組み込んで共同提供を行うパートナーシップや、カスタマイズによるエンドユーザのLLM利用を支援する際に「Super RAG」を採用するパートナーシップについて、パートナー企業各社との連携を開始しているとのことだ。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















