

昨今、SNSの普及に伴い、画像の秘匿化はますます重要性を増している。しかし、従来の方法は手間がかかり、秘匿が不十分であるだけでなく、画像の見た目や統一感を損なう問題があった。
こうした中、東京大学大学院工学系研究科電気系工学専攻の矢谷浩司准教授らのグループは、生成AIを用いた画像の生成的コンテンツ置換(GCR)法を開発した。
新たに開発された手法では、画像全体とプライバシーに関連する部分の内容を表現するテキストを生成し、それらから拡散モデルにより代替画像を生成して元の画像に配置する。
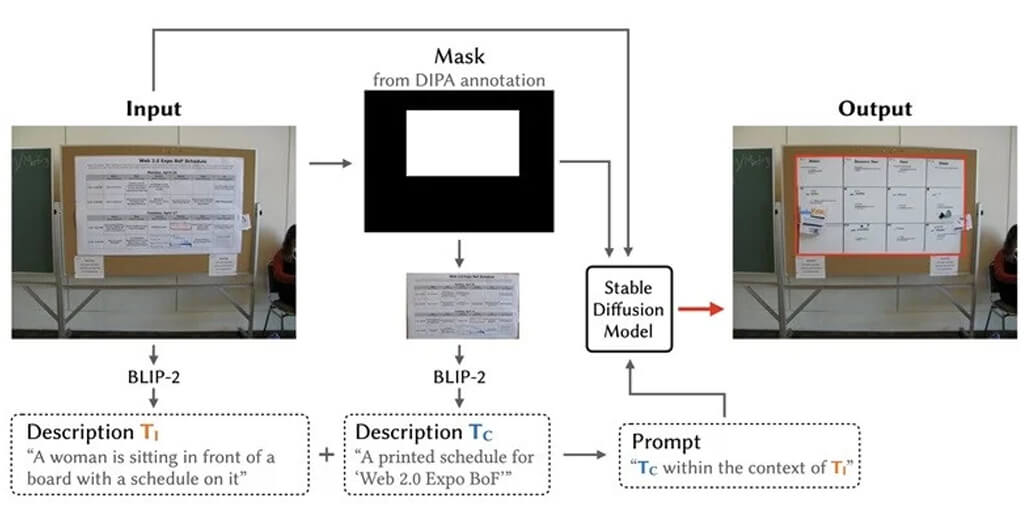
この方法では、ユーザが加工を行いたい画像をシステムにアップロードする。システムは、アップロードされた画像に対して、与えられた画像から情報を抽出し、画像を説明するテキストを生成するマルチモーダル学習技術をベースに構築された人工知能技術である「BLIP-2モデル」を用い、画像全体の内容を表現するようなテキストを生成する。
さらに、DIPA(注2)と呼ばれる矢谷研究室が構築したデータセットにより提供されているマスク情報を用いて、画像内のプライバシーに関連しうる部分を抽出し、その部分の内容を表現するようなテキストを生成する。
この2つのテキストをもとに、拡散モデルと呼ばれる確率的プロセスを用い、テキストの記述に基づいて画像を生成する人工知能技術である「Stable diffusion」(現在はバージョン2.1)を使用して、画像内のプライバシーに関連しうる部分に類似した代替画像を生成し、元画像上に配置することで、コンテンツの置換を行う。
これにより、もと画像にあったプライバシーに関連しうる情報は秘匿化されながらも、画像の見た目や内容を維持することが可能となった。
ぼかし、カートゥーニング(画像の一部を非現実的な程度に強調する方法)、色塗り、除去(画像内の物体等を消し去り、背景で置き換える)、GCRの5つを比較したユーザ実験の結果、GCRによる秘匿加工では、画像内で加工が行われた場所を見つけ出すことが最も難しかったことが確認された。

また、他の秘匿加工手法と比較して、加工後の視覚的な調和が最も保たれていることも確認された。
元画像が持つストーリー性の維持に関しては、GCRはカートゥーニングよりも劣ったものの、プライバシー保護の強さにおいてはGCRが秀でており、GCRによる秘匿加工が、プライバシー保護と画像の視覚的美しさを両立しうる手法であることが確認された。

活用シーンとしては、SNSでの画像共有やプレゼンテーション、ビジュアルデザインなどへの応用が期待されている。さらに、将来的には動画への応用や、より使いやすいインターフェースの開発も進行中だ。
なおこの研究は、Microsoft Research Asia D-CORE Programとメルカリ R4Dとインクルーシブ工学連携研究機構との共同研究である、価値交換工学の成果の一部だ。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















