

株式会社野村総合研究所(以下、NRI)は、80億パラメータという比較的小規模な言語モデルを基盤に、特定業界や個別タスクに特化した大規模言語モデル(以下、LLM)を低コストで構築する独自の手法を開発したと発表した。
この手法には、日本語処理性能に優れ、商用利用可能なオープンウェイトモデルである東京科学大学・産総研開発の「Llama 3.1 Swallow 8B」(80億パラメータ)をベースに採用している。
小規模モデルの活用により計算リソースと運用コストを削減するほか、オープンウェイトであるため、ベースモデルを特定のモデルに固定せずに、目的やタスクに応じて適切に選定することが可能で、将来的なモデルアップデートにも対応できる点が特徴だ。
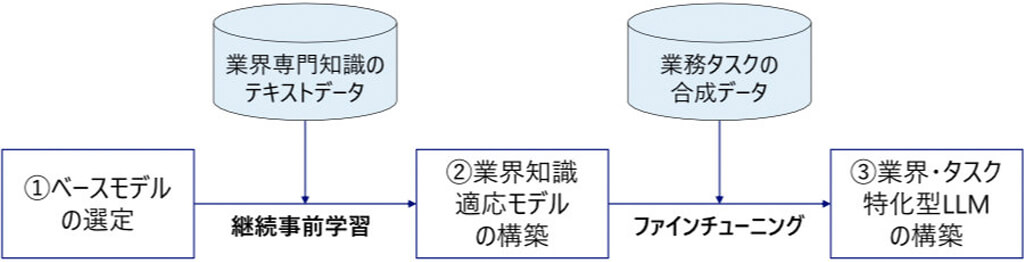
そして、ターゲットとする業界の専門テキストデータを独自に収集・構築し、ベースモデルに対して継続事前学習を実施する。今回は、銀行・保険等の金融業界を例に、日本語の専門知識テキストデータを日本語金融コーパスとして独自に構築した。
これにより、ベースモデルが元来持つ汎用的な言語能力を維持しつつ、業界特有の専門知識を効果的に習得させる汎用的な仕組みを構築した。
さらに、実データの収集が困難なタスクに対し、LLMを用いて多様なシナリオに基づいた「合成データ」を生成することができる。
この合成データを活用してファインチューニングを行うことで、該当タスクに特化したLLMを構築した。これにより、データが限定的、あるいは取得困難な現場特有の課題解決への応用が期待される。
なお、この手法を用いて、保険業界の営業コンプライアンスチェック試験を実施したところ、商用大規模モデルのGPT-4o(2024年11月20日版)を9.6ポイント上回る結果であったという。
今後NRIは、今回の成果を基に、他業界やタスクへの最適化を加速させる計画だ。2025年度には東京科学大学 岡崎研究室との共同研究を開始し、実証実験の実施やモデル技術の改良を進め、生成AIの社会実装を推進する。
さらに、ビッグテック企業やスタートアップとの連携も強化し、技術の商用展開や、タスク特化型AIエージェントへの活用など、多様な用途での利活用拡大を目指すとしている。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















