
ABEJAは、ディープラーニングを活用したオープンプラットフォーム「ABEJA Platform」のベータ版について、2017年9月11日よりPartner Ecosystemに参加するパートナー企業に提供を開始したと発表した。また、2018年2月より正式版をリリースすることも併せて発表した。
ABEJAは、「ABEJA Platform」のアルファ版を、Partner Ecosystemnのパートナー企業を対象に、2016年12月より提供していた。
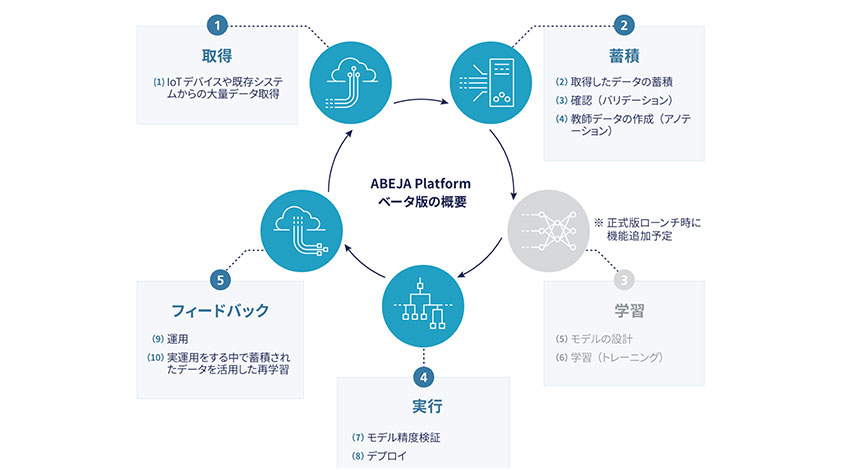
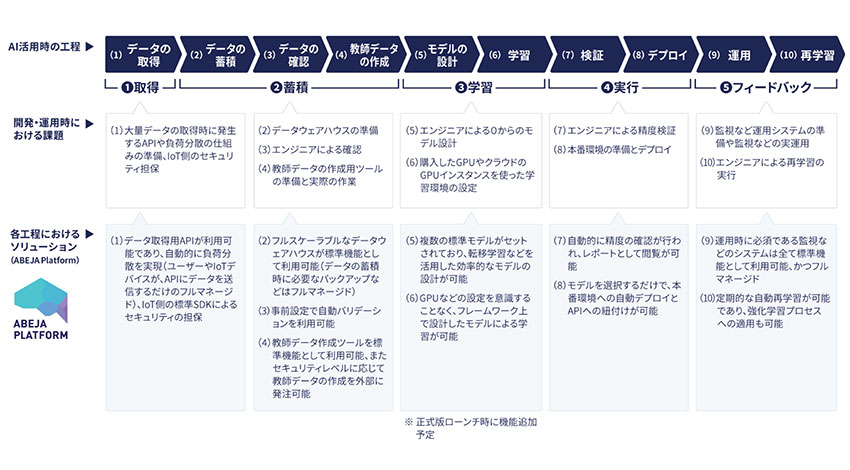
通常、企業がビジネスのソリューションとして、AI、特にディープラーニングを活用するための環境を開発する場合、以下の10の工程を実装するための各種システムを有する環境を構築する必要がある。
①大量データの取得
(1)IoTデバイスや既存システムからの大量データの取得(コレクション)
②蓄積
(2)取得したデータの蓄積
(3)蓄積データの確認(バリデーション)
(4)教師データの作成(アノテーション)
③学習
(5)モデルの設計
(6)学習(トレーニング)
④実行
(7)モデルの精度検証
(8)デプロイ
⑤フィードバック
(9)運用
(10)運用の課程で蓄積されたデータを活用した再学習
例えば、(1)において、大量データの取得時に発生するAPIや負荷分散の仕組みの準備、IoT 側のセキュリティ担保等が必要となる。また、(2)においては、データウェアハウスの準備が必要になる等、環境の整備にあたり各工程においてインフラや周辺システム等を独自に整備する必要がある。
2018年2月に提供開始を予定している「ABEJA Platform」の正式版では、10の工程を実装するために必要なインフラや周辺システムを、1つのプラットフォーム上で一貫して利用することができる。
では、ベータ版とアルファ版では何が違うのか?
2016年12月に提供を開始したアルファ版では、①大量データの取得、および②蓄積のサイクルにおいては、
(1)IoTデバイスや既存システムからの大量データの取得(コレクション)
(2)取得したデータの蓄積
のみが利用可能だったが、ベータ版ではアルファ版の機能に加え、②蓄積のサイクルにおける、
(3)蓄積データの確認(バリデーション)
(4)教師データの作成(アノテーション)
を拡充した。さらには、④実行のサイクルにおける、
(7)モデル精度検証
(8)デプロイ
⑤フィードバックのサイクルにおける、
(9)運用
(10)運用の課程で蓄積されたデータを活用した再学習
の機能も追加している。なお、 (4)と(10)については、現時点でベータ版には含まれないが、後日拡充される予定だ。
2018年2月の正式版のリリースに向け、ベータ版のリリース後もパートナー企業からのフィードバックを反映させながら、③学習のサイクルにおける、
(5)モデルの設計
(6)学習(トレーニング)
についても整備を進めていくという。
【関連リンク】
・アベジャ(ABEJA)

無料メルマガ会員に登録しませんか?

技術・科学系ライター。修士(応用化学)。石油メーカー勤務を経て、2017年よりライターとして活動。科学雑誌などにも寄稿している。

















