
身体の超音波検査では、超音波ビームが骨などの構造物に反射し、それより遠い画像情報を取得できないために、その箇所が「影」として映ることが多々あるという。これは「音響陰影」と呼ばれ、画像の質を劣化させるだけでなく、検査そのものの精度を低下させる最大の原因である。
超音波検査画像に映り込む影を検出する従来の方法は2つある。1つは影の性質を詳細にモデル化し、ルールに基づいて影を検出するという伝統的な画像処理のアプローチ、もう1つはディープラーニングを用いて影の有無をラベル付けしたラベル付きデータを学習(教師あり学習(※1))させて影を検出するというものだ。
1つ目の手法は、超音波検査画像に映り込む多様な影に対応できるモデルを作る必要があるため、精度を高めることが難しいと考えられている。2つ目の手法は、ディープラーニングにより学習させるのに十分な量の「影あり/影なし」ラベル付きデータを準備する必要がある。しかし、影ありと影なしの境界を統一した基準でラベル付けすることが難しく、またこの境界以下の薄い影には原理的に対応できないという弱点があった。
理化学研究所、富士通株式会社、昭和大学、国立がん研究センター(以下、共同研究グループ)は2018年度から、機械学習やディープラーニングを用いて、胎児心臓超音波画像の解剖学的構造をリアルタイムに検知することで、疾患による構造変化を検出する診断支援AI技術を中心に研究開発を進めている。
手動走査により取得し、また骨などによる影が入りやすい超音波検査画像に特有の課題を克服するために、これまで少量・不完全なデータからでも的確な予測可能な「ロバストな機械学習技術(※2)」を研究してきた。
しかし、今後臨床応用を進めていくには、さらに多様な超音波検査画像を処理する必要があるという。そのような検査画像の中には、診断支援AIにとって重要な臓器を隠してしまう影など、そのまま解析すると誤った検知結果を導くものが含まれる可能性がある。そのため、不適切なデータに対しては、再取得を促す機能の開発が求められていた。
そして今回、ディープラーニングによるラベルなしデータでの学習により、超音波検査にAI技術を適用する上で大きな課題である「影」を自動検出する新たな技術を開発し、従来手法に比べてより正確に影を検出できることを確認した。同技術は、ラベルなしデータで学習することから、技術を実装する労力を軽減できる。具体的な学習方法は以下の通り。
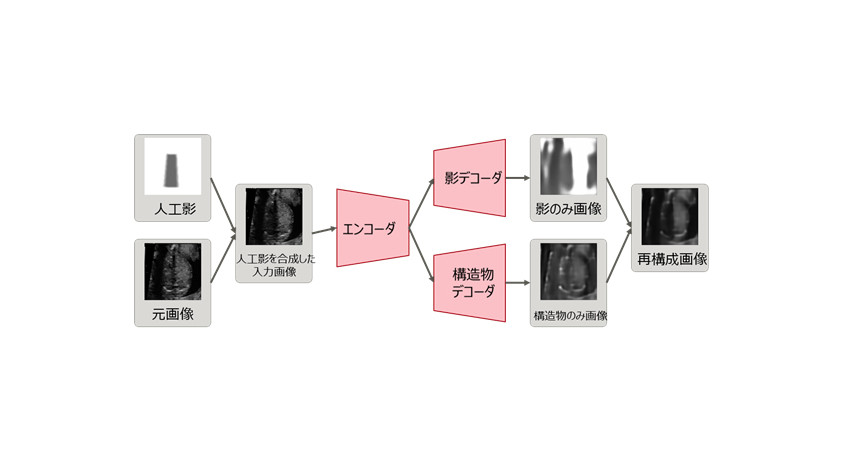
- 元画像と専門医の知見に基づいてランダムに作成した「人工影」を合成したものを入力画像とする。
- その入力画像を、影のみを含んだ画像(影のみ画像)とそれ以外の構造物のみを含んだ画像(構造物のみ画像)に一旦分離した後、それらを合成することで入力画像を再構成するオートエンコーダ(※3)を構成する(再構成画像)。
- 人工影を合成した入力画像と再構成画像との誤差と、人工影と分離した影のみ画像との人工影が存在する領域での誤差が、同時に小さくなるように学習させる。
学習後に影を検出する際には、入力画像を超音波検査画像とし、影のみ画像を検出結果とする。影のみ画像の画素値(画素の明るさ)の合計の比較などにより、影あり/影なしを自動的に判定することができる。
同技術を、昭和大学病院産婦人科での通常の妊婦健診において取得した胎児心臓の超音波検査動画に適用して評価した。動画93本から作成した画像37,378枚を学習用データとして学習させ、7本(約1分)から抜き出して臨床医が影の部分をラベル付けした評価用データの画像52枚を使用して、影画像の検知精度を評価した。
その結果、伝統的な画像処理手法(単純な2値化(※4))、および従来型のディープラーニング手法と比較して、開発した技術はより正確に影を検出できることを確認した。
検出した影が胎児心臓の異常検知に悪影響を及ぼす可能性を見いだすことで、検査者に対して「再走査の指示」を出し、誤った異常検知を防ぐことが可能となる。また、超音波画像に映り込んだ影が異常検知に与える影響を自動的に評価できるようになり、胎児心臓超音波スクリーニング技術(※5)の臨床応用に向けた研究がさらに前進する。
今後は、同技術を2018年度に開発した胎児心臓超音波スクリーニングの基盤技術と統合することで、異常検知性能を向上させるとともに、条件を満たさない入力を判定して再走査を指示する仕組みの構築を目指す。また、成人循環器やがん検診など超音波検査が用いられている幅広い領域での活用に期待できる。
※1 ラベル付きデータとは、人間がラベル(正解)を与えたデータのこと。機械学習において、ラベル付きデータからその特徴を学習する方法を教師あり学習と呼ぶ。
※2 従来の機械学習は、膨大なデータ量や質の高い完全データがなければ十分な予測能力を発揮できない。この課題を克服し、少量のデ-タや不完全なデータであっても、的確に未来を予測できる(=ロバストな)機械学習の基盤技術。例えば、正常例だけを訓練データとする異常検知技術では、何が異常かを明示的に与えることができないため、的確に異常を検知するためには膨大で多様な正常データを収集し学習する必要がある。理研AIP-富士通連携センターの研究課題の一つ。
※3 深層学習における代表的な教師なし学習手法。エンコーダ、デコーダと呼ばれるニューラルネットワークからなり、入力データをエンコーダにより特徴量へ変換し、特徴量をデコーダにより入力データへと再構成(復元)する。
※4 グレースケール(多くの場合、256階調)の画像を、白と黒の2階調へと変換すること。
※5 胎児の超音波診断において先天性心疾患のスクリーニングを支援する技術。その基盤技術として、機械学習・ディープランニングを用いて胎児心臓超音波画像の解剖学的構造をリアルタイムに物体検知し、疾患によるその構造変化を検出する技術を中心に研究開発を進めている。
プレスリリース提供:富士通
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















