

近年、ディープラーニング技術は画像・音声認識を主体に発展を遂げ、セーフティ、ものづくり、インフラ保全などさまざまな分野での活用が広がっている。
例えばものづくりの分野では、製品の外観検査において、人材確保が難しい熟練検査員をカメラによる画像認識で代用したいという要望がある。外観検査をディープラーニングで行うには不良品データを学習する必要があるが、発生頻度の低い不良品は大量に得ることが難しいため、不良品データの収集や不良品を模擬したデータ作成に多大な時間とコストを要していた。
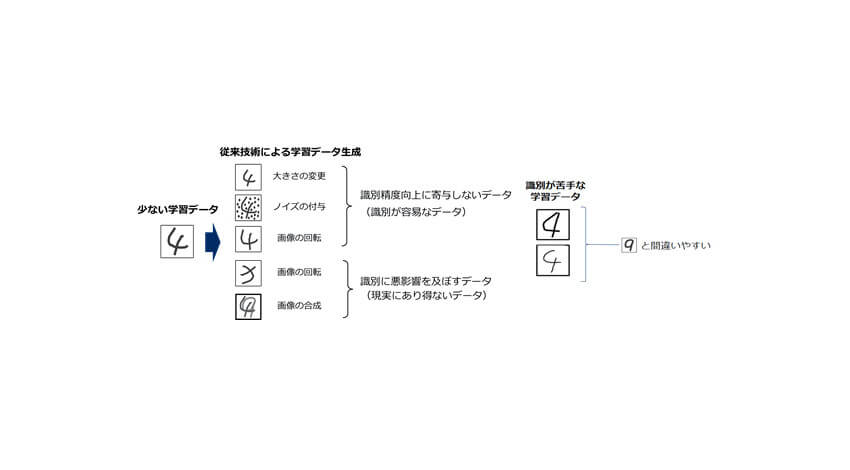
また、識別精度の向上には、識別が難しい「苦手な学習データ」をより多く学習することが有効だが、データ拡張と呼ばれる従来の技術では、ニューラルネットワーク(※1)に入力する前にデータを意図的に加工・変形させ、学習データ量を人工的に増やしていた。しかし、このような増やし方では苦手な学習データの量が不十分かつ識別精度向上に寄与しないデータも多く生成され、十分な学習効果が得られなかった。
さらに、従来のデータ拡張ではデータの種類毎にデータの生成方法を変える必要があった。例えば、画像では大きさや回転角度など、音声では声の高さや話す速さなどを変えることでデータを人工的に増やしていた。さらに、専門家がデータ生成方法を選び、学習に悪影響を及ぼすデータが発生しないよう調整する必要があったため、様々な種類のデータに短期間に適用することは困難だった。
そこで、日本電気株式会社は、従来の半分程度の学習データ量でも識別精度を維持できるディープラーニング技術を開発した。同技術の主な特長は以下の通り。
- 必要となる学習データを従来技術に比べ半分に削減
- データの種類の違いによる専門家の調整が不要
同技術は、ニューラルネットワークの中間層で得られる特徴量を意図的に変化させることで、識別が失敗しやすい苦手な学習データを集中的に人工生成し識別精度を向上させるという。今回同技術を公開データベース(手書き数字認識:MNIST、物体認識:CIFAR-10)(※2)にて評価し、学習データ量が半分でも従来技術と精度が変わらないことを確認した。
同技術は、ニューラルネットワーク内部の数値に基づいて自動的に学習データを生成するため、多様なデータに対して適用することができ、専門家による調整が不要となる。これにより、従来では学習データ収集時間やコストの高さが阻害要因となっていた製品の外観検査やインフラ保全など、さまざまなシステムの早期立ち上げを可能にするという。

※1 人間の脳の仕組みを模したモデリング手法。ニューラルネットワークにデータを入力すると、そのデータが中間層を伝わり、出力層から認識結果として出力される。
※2 MNIST:0から9までの10種類の手書き数字画像からなるデータセット。CIFAR-10:飛行機、鳥、犬など10種類の画像からなるデータセット。いずれも機械学習の精度評価に標準的に用いられる公開データセットである。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















