

昨今、深層学習を核としたAIの活用が期待されているが、深層学習の性能を引き出すには、質・量を兼ね備えた学習データが不可欠だ。
しかし、これまでの深層学習では、環境や撮影デバイス、制作・加工手段など取得条件が異なる学習データが混在する場合に、高精度な認識モデルの学習が難しいという問題があった。さらに、現実世界において、起こりえる取得条件を事前にすべて想定・把握できるとは限らない。
そこで日本電信電話株式会社(以下、NTT)は、どのような条件で取得されたデータであるかが全く分からない寄せ集めの学習データからであっても、高精度な認識モデルを学習可能な深層学習技術を発表した。
今回発表された技術では、データごとの取得条件の違いを明らかにするため、元のデータに対して単純な改変を施すことで新しいデータを生成する、新たなデータ拡張技術を考案。このデータ拡張技術を用いて、データの取得条件が混在し、また、その条件が完全に未知な学習データに対し、データごとの取得条件の違いを教師なし学習によって推定することで、その影響を受けずに高精度な認識モデルを学習可能な深層学習技術を実現した。
また、データ拡張を適用することにより、取得条件に依存する情報のみを正確に捉える自己教師あり学習技術も開発した。
具体的には、データ拡張により画像をいくつかのブロックに分割し、各ブロックの位置をランダムに入れ替えることで、認識したい対象物体の形状はバラバラになり、認識が難しくなる。一方で、CGか実写かという取得条件に関わる情報は、自己教師あり学習により依然として認識可能であることが下図で分かる。
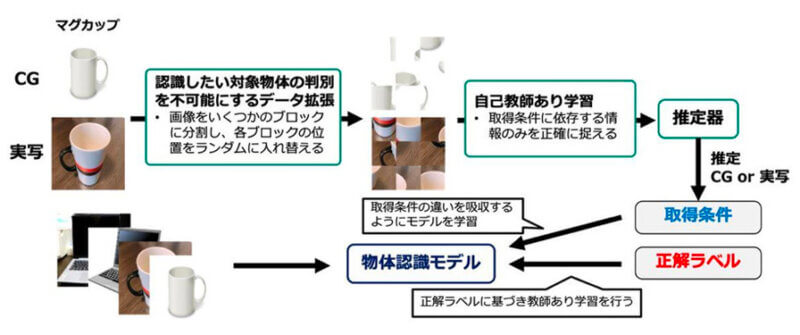
このように、データ拡張を適用した画像を用いて自己教師あり学習を行うことで、取得条件に基づいて正確にデータを分類することができるようになり、結果として取得条件の影響を受けない高精度な認識モデルを学習できるようになった。
実際に、異なる取得条件が混在する特定のデータを用いて評価した場合、従来技術が3.6%の認識精度、今回の技術では77.4%の認識精度だった。この技術によりこれまで学習に利用しにくかったデータの活用を可能にする。
NTTは今後、今回の成果を、画像に限らず音声など映像情報メディアでも有効であることを検証していくとしている。

無料メルマガ会員に登録しませんか?
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















