

需要予測は、企業の利益向上や効率化などを支援する、重要な役割を果たします。
需要予測を行わなければ、適切な調達や生産が行えず、欠品や過剰在庫などのリスクが発生する可能性があるからです。
加えて、昨今のビジネス環境は、消費者のニーズの多様化、市場のグローバル化、天候や社会情勢などの予期せぬ外部要因といった様々な影響により、ますます複雑化しています。
そこで、将来の需要を予測することができれば、企業の競争力を維持し、効率的な経営を行うことができるでしょう。
関連記事:需要予測についてさらに詳しく知りたい方はこちらの記事も参考にしてください。
需要予測とは?基本の手法や目的、製造業で活用できるシステムの種類などを解説
しかし、過去の販売実績などデータを活用する従来の需要予測は、突発的な変化への対応が遅れたり、潜在的な需要を見逃したりするといった課題がありました。
こうした中、IoTによりセンサーデータから得られるリアルタイムな情報を活用した需要予測が注目されています。
本稿では、IoT機器やセンサーデータがどのように需要予測の精度を向上させるのか、そして、企業にどのようなメリットをもたらすのかなどについて解説します。
従来の需要予測の課題
まず、従来の需要予測とはどのようなものかを解説します。
需要を予測するには様々な方法がありますが、ここでは、過去のデータを活用した予測を従来の需要予測とします。
こうした従来の需要予測で活用される過去のデータは、結果が集計されて初めて利用可能になります。
そのため、「今」起こっている変化を即座に反映して予測することはできません。
現状の変化が激しくない時代においては、過去のデータを活用した予測は有効な手法でしたが、前述したような昨今のビジネス環境においては、予測の結果にタイムラグが生じる可能性があります。
また、従来の需要予測は、基本的に過去のデータパターンが将来も継続するという仮定に基づいています。そのため、過去に例のない、あるいはパターンを大きく変えるような事象が発生した場合、予測精度が低下してしまいます。
さらに、従来の需要予測では、予測結果を最終的に人が参考にした上で、これからどれだけ生産するかを決めるのが一般的です。
そのため、担当者の属人化が起こり、異動や退職によって予測精度が不安定になったり、判断の根拠が不明確になったりするリスクがあります。
関連記事:属人化の課題や解決方法について知りたい方はこちらの記事をご覧ください。
属人化とは?属人化が起きる原因やデメリット、デジタルを活用した具体的な解消方法などを解説
IoTとは?
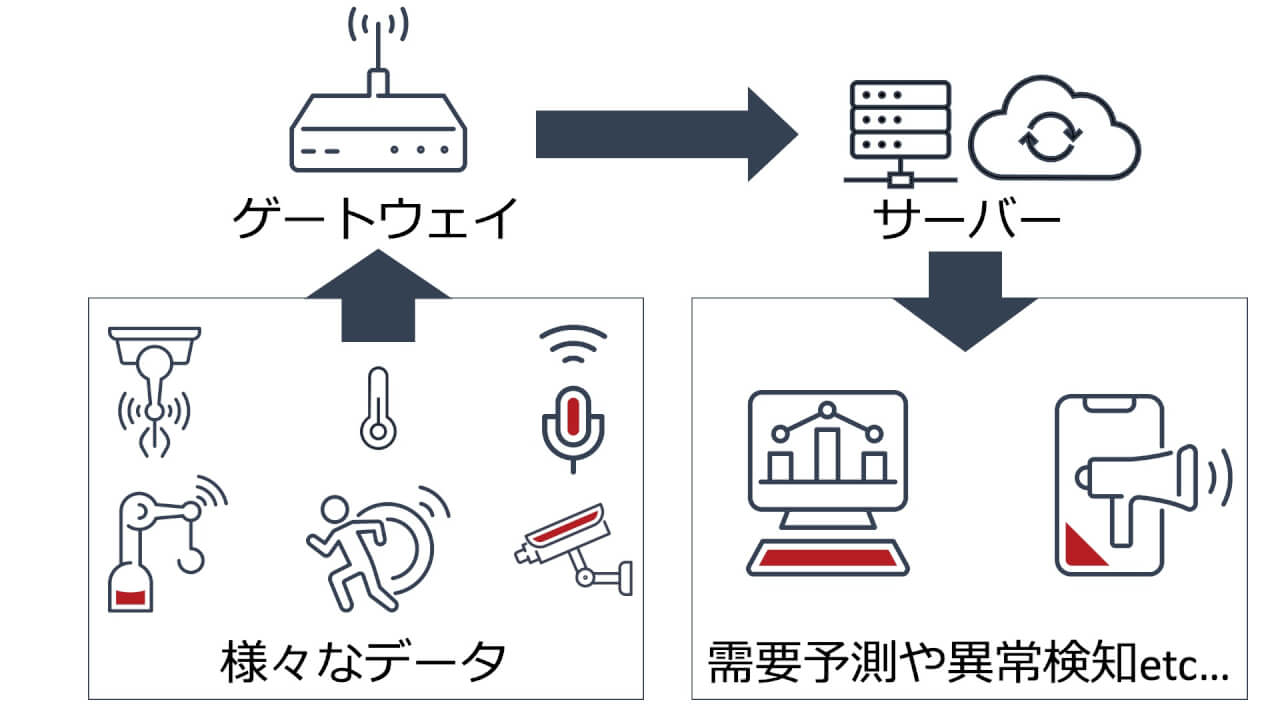
そこで、「今」に近い状況の変化を反映してくれるのがIoTです。
まずは、IoTについて簡単に説明します。
IoTとは、「Internet Of Things」の略で、様々なモノがインターネットに繋がるという意味です。
具体的には、温湿度や振動、人の行動や位置情報などを測定する様々なセンサーや、カメラやマイクなどを活用して、物理世界のデータを収集します。
収集したデータは、必要に応じて「ゲートウェイ」と呼ばれる中継機器などを経由し、様々なネットワークを通じてインターネット上のサーバーなどに送信されます。
サーバーでは、データを処理し、目的に応じて予測や異常検知などの分析を行います。
こうした一連の流れをなるべく早く行うことで、リアルタイムに近い形で現実世界の状態を把握することができます。
需要予測にIoTを活用するメリット
IoTを需要予測に活用する最大のメリットは、前述した「リアルタイムに近い形で現実世界の状態を把握することができる」という点です。
リアルタイムに近いデータを即座に分析し、需要予測を行うことで、急な需要の変動にも迅速に対応することが可能になります。
例えば、突然の猛暑による飲料水の需要増や、イベント開催に伴う特定商品の需要増などをいち早く察知し、生産調整や在庫補充といったアクションをタイムリーに行うことで、販売機会の損失や過剰在庫のリスクを削減することができるでしょう。
また、これまで需要予測に活用されていた過去のデータは、主に過去の販売実績データであることがほとんどでしたが、IoTにより、これまで取得できなかった多様なデータを活用できるようになります。
例えば、商品棚や倉庫などに重量センサーを設置し、「棚の総重量の変化」を測定することで、リアルタイムな商品販売数や在庫数を把握できます。
これにより、欠品が発生する前に補充指示を出したり、予期せぬ需要の急増を即座に検知したりすることが可能になります。
他にも、顧客に提供する製品自体にセンサーを組み込み、インターネットを通じて「活用状況」「消耗品の残量状況」「エラー発生状況」などのデータを収集することで、消耗品の交換時期を予測し、適切なタイミングで顧客に通知したり、保守部品の需要を正確に予測したりすることが可能です。
さらに、製品の使われ方を分析することで、顧客が求めている機能を把握し、将来の製品開発や関連サービスの需要予測に活かすこともできるでしょう。
店舗を運営している企業であれば、店舗にカメラや赤外線センサーを設置することで、「店舗への入店者数」「特定の売り場での滞在時間・通過人数」「顧客の動線」などを把握することができます。
これらのデータと実際の購買データを組み合わせることで、「どのような人の流れが売上に繋がりやすいか」「時間帯や天候によって人の動きはどう変わるか」といった分析が可能になり、需要予測の精度向上が見込めます。
ここで紹介した例はほんの一部で、IoTによって取得・活用できるデータは、現実世界の多様な側面を捉えることができるほど無数に存在します。
そのため、IoTを活用した需要予測の精度をどこまで高められるかは、各企業のアイディアと工夫にかかっていると言えるでしょう。
IoTを活用した需要予測システム実装のステップ
需要予測にIoTを活用したシステムを実際に構築・導入するには、計画的なアプローチが必要です。ここでは、よりイメージがしやすいように、実装ステップの一例をご紹介します。
目的の明確化と課題設定
前述した通り、IoTによって取得・活用できるデータは無数にあるため、どのような成果を得たいのかを設定しなければ、取得するべきデータを定めることができません。
そこでまずは、現状の予測と実績の乖離を把握し、予測にかかる時間や工数、欠品率、過剰在庫率、廃棄ロス額などの定量データを収集・分析します。
同時に、予測担当者や営業、生産管理、在庫管理などの関連部門へのヒアリングを通じて、定性的な課題も洗い出します。
また、業務プロセスを可視化し、ボトルネックとなっている箇所を特定することも有効でしょう。
このように、現在の需要予測プロセスとその実態を客観的に把握します。
次に、現状分析で見えた課題に対し、IoTを活用して「何を達成したいのか」を具体的に定義します。
例えば、「〇〇製品カテゴリーの欠品率を〇%削減する」「予測業務にかかる工数を〇%削減する」「在庫回転率を〇ポイント改善する」など、測定可能かつ達成可能な目標を設定します。
この目標が、企業の経営目標にどう貢献するのかも明確にしておくと、関係者の理解と協力を得やすくなります。
活用データの選定と収集計画
次に、どのようなデータを、どのように集めるのかを決めます。
まずは、最初に設定した目的を達成するために、どのようなデータが役立つか仮説を立て、候補をリストアップします。
例えば、「過去の販売実績」「在庫データ」「生産実績」「顧客データ」といった社内データに加え、IoTで新たに取得可能になるセンサーデータや外部データなど、幅広く検討します。
そして、取得するデータが決まったら、データを取得するためのセンサーやデバイスを選びます。
その際、必要な精度に加え、温度、湿度、粉塵、振動といった設置場所の環境に耐えうる耐久性があるか、コストや電源確保の可否、通信方式、メンテナンス性などを総合的に評価しましょう。
また、予測に必要なリアルタイム性は秒単位なのか分単位なのかを考慮し、データの取得頻度に合わせてセンサーやデバイスを決めていく必要があります。
併せて、通信方式もデータの量や頻度、距離、消費電力などの要件を考慮して選択します。
例えば、低消費電力かつ長距離通信が必要なのであればLPWA、高速大容量通信が必要なのであれば5Gといったように、適切な通信方式を選びましょう。
さらに、取得したいデータに個人情報を含む場合は、個人情報保護法などの関連法規を遵守し、プライバシーに配慮した設計・運用が必要となります。
データ基盤の構築
どのようなデータを、どのように集めるのかが決まったら、次はそれらのデータを実際に受け取り、整理・保管し、分析や予測に使える形にするための「データ基盤」を構築します。
データ基盤は、大きく分けて「データを集める仕組み(収集・集約)」「データを貯める場所(蓄積)」「データをきれいに加工する仕組み(前処理)」の3つの主要な要素で構成されます。
データ収集・集約
「データを集める仕組み(収集・集約)」は、データ基盤全体の「入り口」にあたり、後続のデータ蓄積、処理、分析の質を左右する重要なプロセスです。
このプロセスでは、様々な場所から、様々な形式で、様々なタイミングで発生するデータを、安定的に効率よく一箇所に集めてくる必要があります。
そのため、取得するデータの形式やデータ量、送信頻度や通信プロトコルに合わせてシステムを設計する必要があります。
データの蓄積
データを集める仕組みが整ったら、次は「データを貯める場所(蓄積)」を構築します。
この場所は、後でデータを分析したり予測モデルを学習させたりするために、日々集まってくる大量のデータを安全かつ効率的に貯めておく「保管庫」としての役割を果たします。
データをどのように貯めるかは、そのデータの特性や利用目的に応じて、主に二つの考え方があります。
一つは、センサーから送られてくる生データや、画像、テキストなど様々な形式のデータを、まずは加工せずにそのままの形で大量に貯めておくための「データレイク」と呼ばれる保管場所です。
湖(レイク)のように多種多様なデータをそのまま受け入れるイメージで、将来どのような分析に使うか現時点では決まっていないデータも、とりあえず保持しておける柔軟性があります。
もう一つは、分析レポートを作成したり、ビジネス状況を把握したりしやすいように、事前に構造(テーブル形式など)を整え、きれいに整理されたデータを格納するための「データウェアハウス(DWH)」です。
こちらは倉庫(ウェアハウス)のように、整理された状態でデータが保管されているイメージです。
実際の活用シーンでは、まずデータレイクに全てのデータを貯め、その中から分析に必要なデータを取り出して加工し、データウェアハウスに移してから分析を行う、といった使い分けがされることも多くあります。
どの技術(保管庫)を選ぶかは、扱うデータの種類が構造化されているか、テキストや画像かといったことや、どれくらいのデータ量を蓄積したいのかに加え、更新頻度やそのデータの利用目的に合わせて決定する必要があります。
データの前処理
そして、蓄積されたデータを分析や予測モデルで実際に使えるようにするために、「データをきれいに加工する仕組み(前処理)」を構築します。
蓄積されたデータは、多くの場合、そのままでは分析や機械学習に適していません。
例えば、データの一部が欠けていたり(欠損値)、明らかに間違った値(異常値)が含まれていたり、単位や形式がバラバラだったりすることがあります。
そのため、この前処理ステップで、これらのデータを分析や予測に適した「使えるデータ」に整える必要があります。
主な処理内容としては、まず「データクレンジング」があります。
具体的には、欠損値に対して、「平均値で埋める」「前後の値から推測する」「そのデータ自体を削除する」など、欠損値の処理を定義します。
同様に、欠損値や異常値をどう扱うかを定義したり、「日本」「にほん」「Japan」といった異なる表記を統一したり、数値であるべきデータが文字列として保存されている場合などに適切なデータ型に変換したりといったクレンジングを行います。
そして、クレンジングされたデータを、さらに分析しやすい形や、予測モデルが学習しやすい形に「変換・加工」します。
例えば、単位や形式を統一したり、売上や顧客情報といった別々に管理しているデータを結合したり、日次の売上データを週次や月次にまとめるなどのデータの集計を行ったりします。
これらのクレンジングや変換・加工処理は、データが日々追加・更新される中で、毎回手作業で行うのは非効率的です。
そのため、これら一連の処理手順を「データパイプライン」としてプログラムやツールで定義し、自動的に実行する仕組みを構築するのが一般的です。
データを処理するタイミングも重要で、一定期間(例えば1日1回深夜に)データをまとめて処理する「バッチ処理」と、データが発生するのに合わせてほぼリアルタイムに処理する「ストリーム処理」があります。
どちらを選ぶかは、データの鮮度がどれくらい重要か、分析の目的などによって決めます。
この自動化されたデータパイプラインを実現するためには、データを抽出・変換・格納/読み込みするETL/ELTツールや、データ処理に特化したクラウドサービス、あるいはプログラミングとワークフロー管理ツールの組み合わせがよく利用されます。
どの技術を選択するかは、扱うデータの量や処理の複雑さ、求められる処理速度、開発チームのスキルセットなどを考慮して決定します。
この前処理ステップを経て、データはようやく分析や予測モデル構築のための「準備完了」の状態となります。
データの質は予測モデルの精度に直接影響を与えるため、この「下ごしらえ」の工程は、地味に見えるかもしれませんが、極めて重要です。
準備が整ったこの質の高いデータを活用し、いよいよ次のステップで具体的な需要予測モデルを構築していくことになります。
需要予測モデルの構築と検証
このプロセスでは、下ごしらえが終わったデータの中から、規則性やパターンを学習し、それに基づいて未来を予測するモデルを構築します。
まずは、どのような手法(アルゴリズム)を使って需要予測モデルを構築するかを決定します。
手法の選択肢は、時系列モデルや回帰分析、コンピュータがデータから自動的に学習する機械学習など、多岐に渡ります。
どの手法を選ぶかは、単品レベルの短期予測か、カテゴリ全体の長期予測かといった予測対象と期間に加え、どの程度の予測精度が必要か、予測結果の理由を説明する必要があるか、開発・運用コストなどを考慮します。
使用する手法が決まったら、準備したデータを使って実際にモデルを開発します。
この段階で重要になるのが「特徴量エンジニアリング」です。
これは、日付、売上数量、気温といった元のデータから、モデルがより学習しやすく、予測精度向上に繋がりやすいような新しい情報(特徴量)を作り出す作業です。
例えば、「過去7日間の売上移動平均」や、「週末かどうか」「セール実施日かどうか」といった、特定の条件に当てはまるかどうかを示す情報などが特徴量にあたります。
このように特徴量エンジニアリングなどを経て、予測モデルが学習しやすいように整えられたデータセットが準備できたら、準備したデータを目的別に分割します。
通常、データをモデルの訓練に使用する「学習データ」と、完成したモデルの性能を客観的に評価するために取っておく「検証データ」の二つに分けて使用します。
まずは「学習データ」を使って、選定した手法に基づき、モデルにパターンを学習させていきます。
モデルが完成したら、そのモデルが「どれくらい正確に未来を予測できるか」を客観的に評価して検証する必要があります。
この検証に、「検証データ」を用います。検証データに対するモデルの予測値と、実際の値(正解データ)を比較し、その誤差を測定します。
評価には、MAPE(平均絶対パーセント誤差)、RMSE(二乗平均平方根誤差)といった統計的な評価指標がよく用いられます。なお、どの指標を使うかは目的によって変わります。
そして、算出された評価指標の値や、予測結果と実績値の比較グラフなどを見て、最初に設定した目標を達成できているか、ビジネス要件を満たせる精度かを判断します。
もし精度が不十分な場合は、モデルを改善するための「チューニング」を行います。具体的には、モデルの内部パラメータ(設定値)を調整したり、特徴量を追加・削除・変更したり、データの前処理方法を見直したり、場合によっては使用するアルゴリズム自体を変更したりします。
この検証とチューニングのプロセスで特に注意すべきなのが「過学習(オーバーフィッティング)」です。
これは、モデルが学習データに過剰に適合してしまい、学習データに対する予測精度は非常に高いものの、未知のデータに対してはうまく予測できなくなってしまう現象です。
そのため、過学習を防ぐためのテクニック(正則化など)を用いることも重要です。
システム化と業務への統合
予測モデルが構築できたら、実際の業務で活用できるようにシステムに組み込み、日々の業務プロセスへと統合していきます。
まず、構築した予測モデルが定期的に実行され、その結果を利用者が確認したり、他の関連システムが利用したりできるような「仕組み」に落とし込む必要があります。
具体的な実装方法としては、グラフや表を使って分かりやすく表示する画面(ダッシュボード)での可視化や、予測値が事前に設定した条件を満たした場合に自動的に通知するなど、業務に役立つ仕組みを構築します。
また、予測結果を、生産計画システムやERP、在庫管理システム(WMS)や自動発注システムといった既存の業務システムにAPI連携などを通じて、自動的に取り込めるようにすることも効果的です。
これにより、既存システムの情報を予測モデルに活用して精度向上が期待できるほか、既存システムも予測情報を活用して業務アクションにつなげることができ、サプライチェーン全体の効率化やコスト削減、キャッシュフローの改善などに貢献します。
そして、こうしたシステムを設計・開発する際には、利用者が直感的に操作できるかといった「ユーザーインターフェース」、ストレスなく快適に使えるかといった「ユーザーエクスペリエンス」を意識することも重要です。
どんなに高機能でも、現場で「使いにくい」「分かりにくい」と思われてしまっては活用が進まないからです。
さらに、新しい予測情報がシステムから提供されるようになっても、それを日々の業務の中でどのように活かすかのルールや流れが決まっていなければ、効果は限定的です。
そこで、新しい予測システムから得られる情報を、誰が、いつ、どのように確認して具体的なアクションに繋げるのか、ルールとワークフローを設計します。
需要予測は、営業、マーケティング、生産、物流、購買、財務など複数の部署に関連するため、役割分担や責任の所在について合意形成を図ることが不可欠です。既存の業務プロセスへの影響を十分に考慮し、スムーズな移行計画を立てます。
運用・評価・継続的改善
需要予測システムが無事に稼働し、新しい業務プロセスが動き始めたとしても、それでプロジェクトが完了というわけではありません。
導入したシステムを「運用」し、その導入効果を客観的に「評価」することで、市場やビジネスの変化に合わせてシステムとプロセスを「継続的に改善」していく必要があります。
例えば、サーバーやネットワーク、データベースなどのインフラの状態や、予測モデルの実行状況、データ連携が正常に行われているかなどを常に監視します。異常を早期に検知し、問題が大きくなる前に対処できる体制が重要です。
また、ソフトウェアのアップデートや、セキュリティパッチの適用、不要になったデータの削除や整理、定期的なバックアップなどを計画的に実施します。
システムに何らかの問題が発生した場合は、迅速に原因を特定し、復旧させる必要があるため、事前に手順や体制を整えておきます。
これらの監視、メンテナンス、障害対応といった業務を「誰が」「どのように」責任を持って行うのか、運用体制を明確に定義しておくことが不可欠です。
さらに、システム導入によって、当初目指していた目的が達成されているのかを定期的に測定し、客観的に評価します。
評価結果や現場からのフィードバック、そして常に変化する外部環境や内部環境を踏まえ、システム、予測モデル、業務プロセスを継続的に見直し、改善していきます。
改善活動の例としては、新しい実績データや外部要因データを活用したモデルの定期的な再学習による精度維持・向上や、データ特性の変化に応じた特徴量の見直し、予測モデル自体の刷新などが挙げられます。
また、ユーザーからのフィードバックや利用状況の分析に基づき、ダッシュボードの表示内容を改善したり、アラート条件を調整したり、システム連携を強化したりすることも効果的でしょう。
改善活動の方法は様々ですが、最も重要なのは、これらの改善活動を一度きりで終わらせるのではなく、「評価」「改善計画(Plan)」「実行(Do)」「効果測定(Check)」「さらなる改善(Act)」というPDCAサイクルを、組織として継続的に回していく文化を醸成することです。
今回紹介した実装ステップは、簡潔に説明した一例ですが、多くの工程と考慮事項を含んでいることがお分かりいただけたと思います。
需要予測にIoTによるリアルタイムデータを活用するプロセスは単純ではなく、相応の計画性やリソース、専門知識が求められる複雑な取り組みであることが伺えます。
しかし、これを実現することができれば、予測の精度を向上させ、リアルタイムな市場の変化を捉えることが期待でき、大きな経営インパクトをもたらす可能性を秘めています。
一方、その効果の大きさや、自社にとって最適なデータの活用方法は、実際に取り組んでみなければ見えてこない未知数な部分もあります。
そのため、いきなり大規模なシステム導入を目指すのではなく、まずはPoC(Proof of Concept:概念実証)などで小さく始めて効果を検証し、そこから得られた学びをもとに段階的に適用範囲を広げていく、という進め方を選択するケースも多くあります。
事例
IoTを活用した需要予測をさらにイメージできるように、2つの事例を紹介します。
カメラを活用した需要予測
通常メーカーは、需要はあるのに在庫がなく、売上につながるはずの機械を逃すことは避けたいと考えます。そこで、多めに生産しておくという手法を取るケースも少なくありません。
しかしこの手法では、食品などの消費期限がある製品の場合、余ったら廃棄せざるを得ず、ロスが発生してしまうという問題があります。
そこである食品メーカーは、製品を流通させている小売店舗にカメラを導入して、棚の在庫や人流といったリアルタイムなデータを取得してAIが分析することで通過人数辺りの購入数予測を立て、2週間前の需要予測で製造を行いました。
さらに、前日に在庫状況などを踏まえた直前予測を行い、発注数を決めて店舗に商品を送るという手法を取ることで、需要に合わせた製造計画を行っています。
加えて、出荷する量の予測をもとに、流通で必要となるトラックの台数や人員等の割り当ての予測も行い、物流の全体最適につなげているそうです。
製造設備データを活用した需要予測
ある飲料メーカーは、新鮮かつリーズナブルなドリンク製品を店舗で供給するため、欠品防止や新鮮な材料の供給、過剰在庫防止や予防保全を行うためのシステムの構築を求めていました。
そこで、製造マシンにセンサーを設置して稼働状況データを取得し、クラウドへ送信する機能を有するゲートウェイを開発。クラウドに蓄積されたデータを分析して、原材料の需要を予測する仕組みを構築しました。
また、蓄積された製造マシンの稼働状況データから、製造マシンのメンテナンス情報や消耗品交換情報を通知するための機能を開発しました。
これにより、原材料の過剰在庫による劣化や欠品による販売機会喪失を減少させるほか、製造マシンが稼働して欲しい時に故障したりせず、供給を続けられる体制を整えることができました。
まとめ
IoTを活用した需要予測は、前述したように専門知識が求められる複雑な取り組みであるため、PoC段階であったり、部分的な導入であったりするケースが現時点では多いようです。
しかし、今後、ネットワークやデバイス、AIなど、様々な要素技術の発展により、大きな成果が得られる可能性を秘めています。
引き続き、新たな導入成果や要素技術などが発表された際には、紹介していきたいと思います。

現在、デジタルをビジネスに取り込むことで生まれる価値について研究中。IoTに関する様々な情報を取材し、皆様にお届けいたします。

















