

日本電信電話株式会社(以下、NTT)は、NTT版大規模言語モデル「tsuzumi」の拡張技術として、少量の対話データから個人の口調や発話内容の特徴を反映して対話を生成する、個人性再現対話技術を開発したことを発表した。また、少量の音声データから個人の声色を反映した音声を合成するZero/Few-shot音声合成技術も開発した。
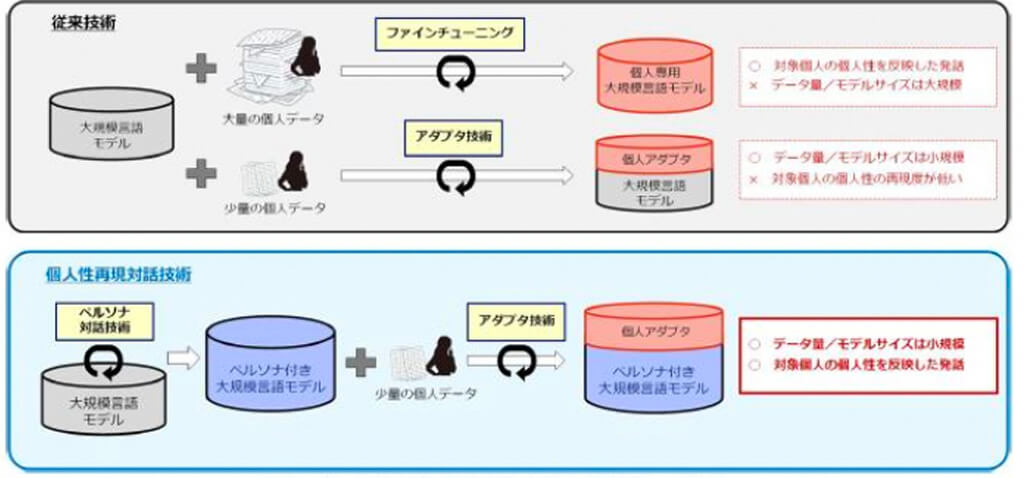
従来、LLMは個人の多くのデータを用いて個人性を再現するためにファインチューニングされていたが、コストが高いため、一部の著名人などに限定されていた。
一方で、アダプタ技術を用いて少量のデータで効率的にLLMを追加学習させる方法もあるが、LLMが多様な人のデータで学習されているため、追加学習データと類似性が低い対話例では、個人の特徴が失われ、他人のような発話が生成されることがあった。
そこで、今回開発された個人性再現対話技術では、ペルソナ対話技術とアダプタ技術を組み合わせることで、個人アダプタで学習されていないような対話でも、ベースとなるLLMが対象となる個人のペルソナを反映した発話を生成するため、全く異なる人の発話内容が生成される問題を回避する。
また、Zero/Few-shot音声合成技術は、数十分程度の音声データを用意する必要がある従来技術と異なり、数秒から数分程度の音声から声色の特徴を抽出し、その特徴を再現した音声を生成することが可能である。
より少ない音声データからでも高品質かつ多様な表現の生成を可能にするため、2つの技術が開発された。
1つ目は、声を再現したい話者の数秒程度の音声から声色の特徴を抽出し、音声合成モデルの学習をすることなくその特徴を再現した音声を生成する「Zero-shot音声合成技術」だ。
2つ目は、再現したい口調の音声を含む数分〜10分程度の音声データから音声合成モデルを学習し、従来に比べ必要な音声データ量を削減しながらも再現性の高い音声を合成可能な「Few-shot音声合成技術」だ。
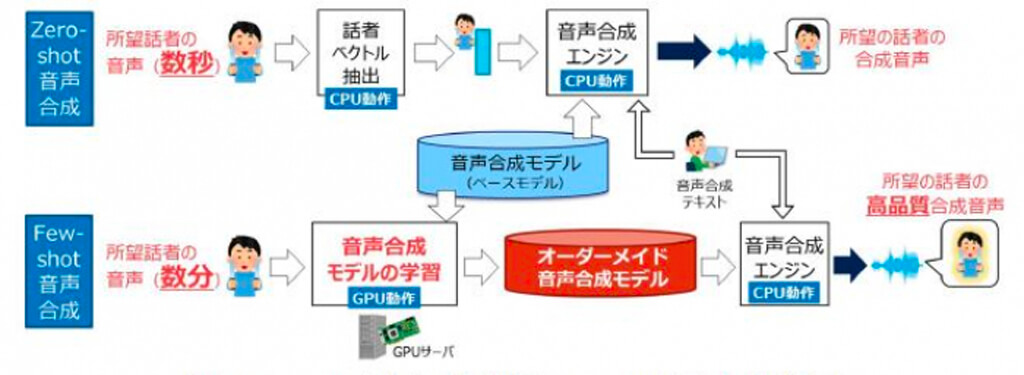
これらの技術を実現するためには、多くのパラメータを持つ深層学習モデルを必要とするが、演算処理の高速化により一般的なスペックのCPUで動作させることに成功しているのだという。
今後は、ユーザのデジタル分身を通じた人間関係の創出効果に関して、NTTドコモのメタコミュニケーションサービス「MetaMe」上でのフィールド実験を開始するとともに、2024年1月17日から東京国際フォーラムにて開催されるdocomo Open House’24にて展示予定だ。
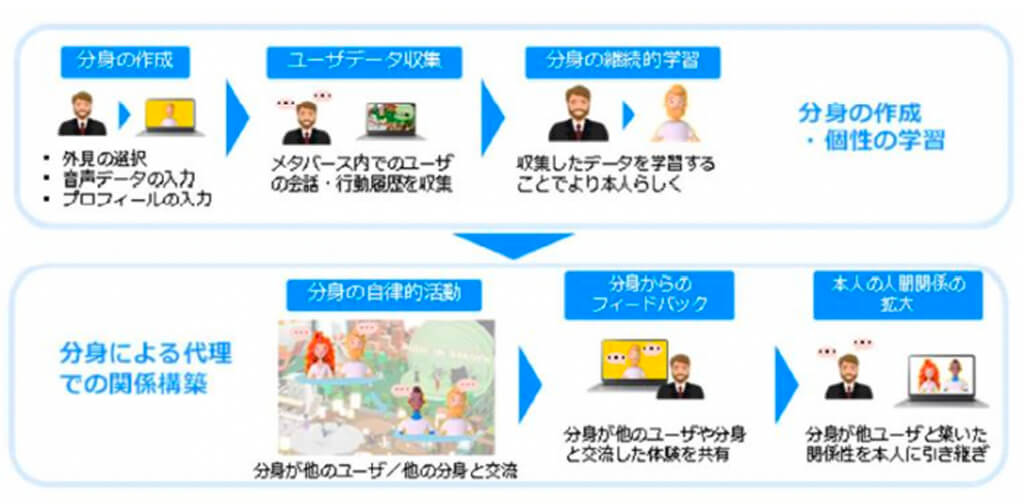
また、NTT版大規模言語モデル「tsuzumi」による個人性再現機能の提供に向け、2024年度中に技術の精度向上を図るとしている。
IoTに関する様々な情報を取材し、皆様にお届けいたします。

















